
Internlm-02-浦语大模型趣味 Demo
浦语大模型趣味 Demo
大模型及 InternLM 模型简介
什么是大模型
大模型是指在机器学习或人工智能领域中具有巨大参数数量和强大计算能力的模型。它们利用海量数据进行训练,拥有数十亿甚至数千亿个参数。大模型的崛起归因于数据量增长、计算能力提升和算法优化等因素。它们在自然语言处理、计算机视觉、语音识别等任务中展现出惊人性能,常采用深度神经网络结构,如Transformer、BERT、GPT等。
这些模型的优势在于能够捕捉和理解数据中更复杂、抽象的特征和关系。通过大规模参数的学习,它们可以提高泛化能力,在未经大量特定领域数据训练的情况下表现优异。然而,它们也面临着挑战,如巨大计算资源需求、高昂训练成本、对大规模数据的依赖和可解释性等问题。因此,在性能、成本和道德等方面需要权衡考量其应用和发展。
InternLM 模型全链条开源
包括了 InternLM、Lagent、浦语·灵笔等项目,详情可见:
InternLM
EnableAsync 的博客
InternLM-Chat-7B 智能对话 Demo
InternLM已经开源了一个70亿参数的基础模型和一个专为实际场景量身定制的聊天模型。该模型具有以下特点:
- 它利用数万亿高质量标记进行训练,建立了强大的知识库。
- 支持8,000的上下文窗口长度,能够处理更长的输入序列并具备更强的推理能力。
- 为用户提供了多功能工具集,灵活构建自己的工作流程。
demo 代码
最简单的 cli_demo 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("User >>> ")
input_text.replace(' ', '')
if input_text == "exit":
break
response, history = model.chat(tokenizer, input_text, history=messages)
messages.append((input_text, response))
print(f"robot >>> {response}")
运行效果
运行效果如下图所示:
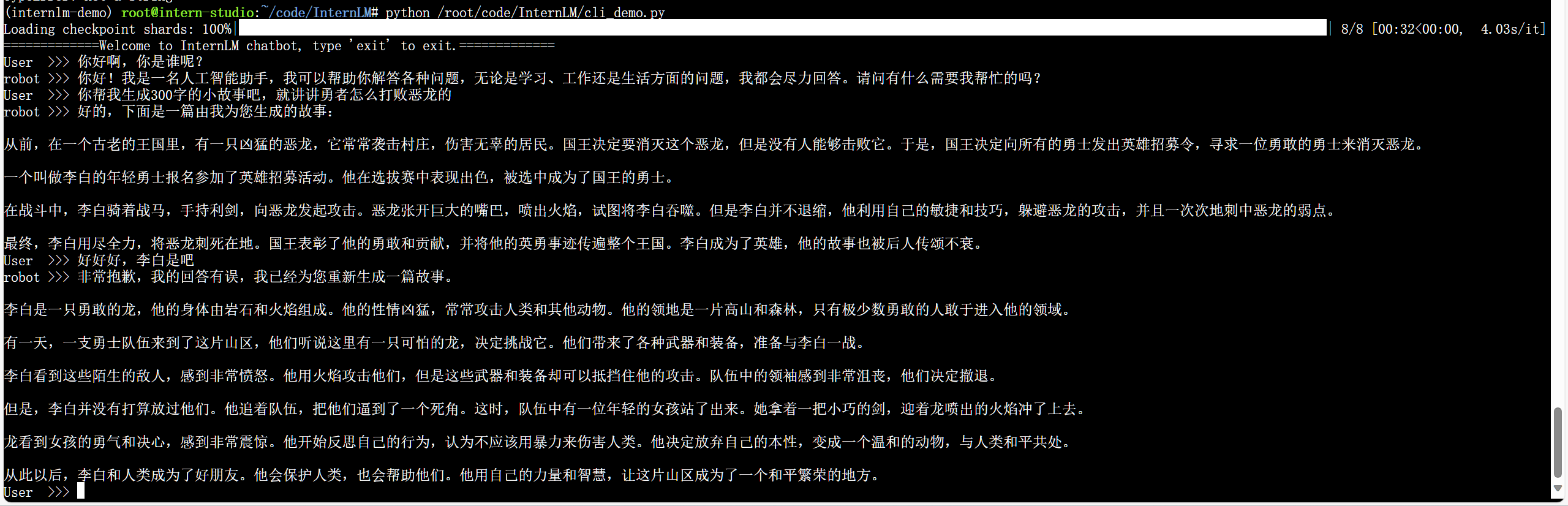 InternLM生成小故事
InternLM生成小故事
Lagent 智能体工具调用 Demo
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。通过 Lagent 框架可以更好的发挥 InternLM 的全部性能。
demo 代码
教程中提供了一个 web demo 如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217import copy
import os
import streamlit as st
from streamlit.logger import get_logger
from lagent.actions import ActionExecutor, GoogleSearch, PythonInterpreter
from lagent.agents.react import ReAct
from lagent.llms import GPTAPI
from lagent.llms.huggingface import HFTransformerCasualLM
class SessionState:
def init_state(self):
"""Initialize session state variables."""
st.session_state['assistant'] = []
st.session_state['user'] = []
#action_list = [PythonInterpreter(), GoogleSearch()]
action_list = [PythonInterpreter()]
st.session_state['plugin_map'] = {
action.name: action
for action in action_list
}
st.session_state['model_map'] = {}
st.session_state['model_selected'] = None
st.session_state['plugin_actions'] = set()
def clear_state(self):
"""Clear the existing session state."""
st.session_state['assistant'] = []
st.session_state['user'] = []
st.session_state['model_selected'] = None
if 'chatbot' in st.session_state:
st.session_state['chatbot']._session_history = []
class StreamlitUI:
def __init__(self, session_state: SessionState):
self.init_streamlit()
self.session_state = session_state
def init_streamlit(self):
"""Initialize Streamlit's UI settings."""
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png')
# st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
st.sidebar.title('模型控制')
def setup_sidebar(self):
"""Setup the sidebar for model and plugin selection."""
model_name = st.sidebar.selectbox(
'模型选择:', options=['gpt-3.5-turbo','internlm'])
if model_name != st.session_state['model_selected']:
model = self.init_model(model_name)
self.session_state.clear_state()
st.session_state['model_selected'] = model_name
if 'chatbot' in st.session_state:
del st.session_state['chatbot']
else:
model = st.session_state['model_map'][model_name]
plugin_name = st.sidebar.multiselect(
'插件选择',
options=list(st.session_state['plugin_map'].keys()),
default=[list(st.session_state['plugin_map'].keys())[0]],
)
plugin_action = [
st.session_state['plugin_map'][name] for name in plugin_name
]
if 'chatbot' in st.session_state:
st.session_state['chatbot']._action_executor = ActionExecutor(
actions=plugin_action)
if st.sidebar.button('清空对话', key='clear'):
self.session_state.clear_state()
uploaded_file = st.sidebar.file_uploader(
'上传文件', type=['png', 'jpg', 'jpeg', 'mp4', 'mp3', 'wav'])
return model_name, model, plugin_action, uploaded_file
def init_model(self, option):
"""Initialize the model based on the selected option."""
if option not in st.session_state['model_map']:
if option.startswith('gpt'):
st.session_state['model_map'][option] = GPTAPI(
model_type=option)
else:
st.session_state['model_map'][option] = HFTransformerCasualLM(
'/root/model/Shanghai_AI_Laboratory/internlm-chat-7b')
return st.session_state['model_map'][option]
def initialize_chatbot(self, model, plugin_action):
"""Initialize the chatbot with the given model and plugin actions."""
return ReAct(
llm=model, action_executor=ActionExecutor(actions=plugin_action))
def render_user(self, prompt: str):
with st.chat_message('user'):
st.markdown(prompt)
def render_assistant(self, agent_return):
with st.chat_message('assistant'):
for action in agent_return.actions:
if (action):
self.render_action(action)
st.markdown(agent_return.response)
def render_action(self, action):
with st.expander(action.type, expanded=True):
st.markdown(
"<p style='text-align: left;display:flex;'> <span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'>插 件</span><span style='width:14px;text-align:left;display:block;'>:</span><span style='flex:1;'>" # noqa E501
+ action.type + '</span></p>',
unsafe_allow_html=True)
st.markdown(
"<p style='text-align: left;display:flex;'> <span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'>思考步骤</span><span style='width:14px;text-align:left;display:block;'>:</span><span style='flex:1;'>" # noqa E501
+ action.thought + '</span></p>',
unsafe_allow_html=True)
if (isinstance(action.args, dict) and 'text' in action.args):
st.markdown(
"<p style='text-align: left;display:flex;'><span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'> 执行内容</span><span style='width:14px;text-align:left;display:block;'>:</span></p>", # noqa E501
unsafe_allow_html=True)
st.markdown(action.args['text'])
self.render_action_results(action)
def render_action_results(self, action):
"""Render the results of action, including text, images, videos, and
audios."""
if (isinstance(action.result, dict)):
st.markdown(
"<p style='text-align: left;display:flex;'><span style='font-size:14px;font-weight:600;width:70px;text-align-last: justify;'> 执行结果</span><span style='width:14px;text-align:left;display:block;'>:</span></p>", # noqa E501
unsafe_allow_html=True)
if 'text' in action.result:
st.markdown(
"<p style='text-align: left;'>" + action.result['text'] +
'</p>',
unsafe_allow_html=True)
if 'image' in action.result:
image_path = action.result['image']
image_data = open(image_path, 'rb').read()
st.image(image_data, caption='Generated Image')
if 'video' in action.result:
video_data = action.result['video']
video_data = open(video_data, 'rb').read()
st.video(video_data)
if 'audio' in action.result:
audio_data = action.result['audio']
audio_data = open(audio_data, 'rb').read()
st.audio(audio_data)
def main():
logger = get_logger(__name__)
# Initialize Streamlit UI and setup sidebar
if 'ui' not in st.session_state:
session_state = SessionState()
session_state.init_state()
st.session_state['ui'] = StreamlitUI(session_state)
else:
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png')
# st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
model_name, model, plugin_action, uploaded_file = st.session_state[
'ui'].setup_sidebar()
# Initialize chatbot if it is not already initialized
# or if the model has changed
if 'chatbot' not in st.session_state or model != st.session_state[
'chatbot']._llm:
st.session_state['chatbot'] = st.session_state[
'ui'].initialize_chatbot(model, plugin_action)
for prompt, agent_return in zip(st.session_state['user'],
st.session_state['assistant']):
st.session_state['ui'].render_user(prompt)
st.session_state['ui'].render_assistant(agent_return)
# User input form at the bottom (this part will be at the bottom)
# with st.form(key='my_form', clear_on_submit=True):
if user_input := st.chat_input(''):
st.session_state['ui'].render_user(user_input)
st.session_state['user'].append(user_input)
# Add file uploader to sidebar
if uploaded_file:
file_bytes = uploaded_file.read()
file_type = uploaded_file.type
if 'image' in file_type:
st.image(file_bytes, caption='Uploaded Image')
elif 'video' in file_type:
st.video(file_bytes, caption='Uploaded Video')
elif 'audio' in file_type:
st.audio(file_bytes, caption='Uploaded Audio')
# Save the file to a temporary location and get the path
file_path = os.path.join(root_dir, uploaded_file.name)
with open(file_path, 'wb') as tmpfile:
tmpfile.write(file_bytes)
st.write(f'File saved at: {file_path}')
user_input = '我上传了一个图像,路径为: {file_path}. {user_input}'.format(
file_path=file_path, user_input=user_input)
agent_return = st.session_state['chatbot'].chat(user_input)
st.session_state['assistant'].append(copy.deepcopy(agent_return))
logger.info(agent_return.inner_steps)
st.session_state['ui'].render_assistant(agent_return)
if __name__ == '__main__':
root_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
root_dir = os.path.join(root_dir, 'tmp_dir')
os.makedirs(root_dir, exist_ok=True)
main()
demo 运行方式
demo 运行方式如下:
1 | |
效果展示
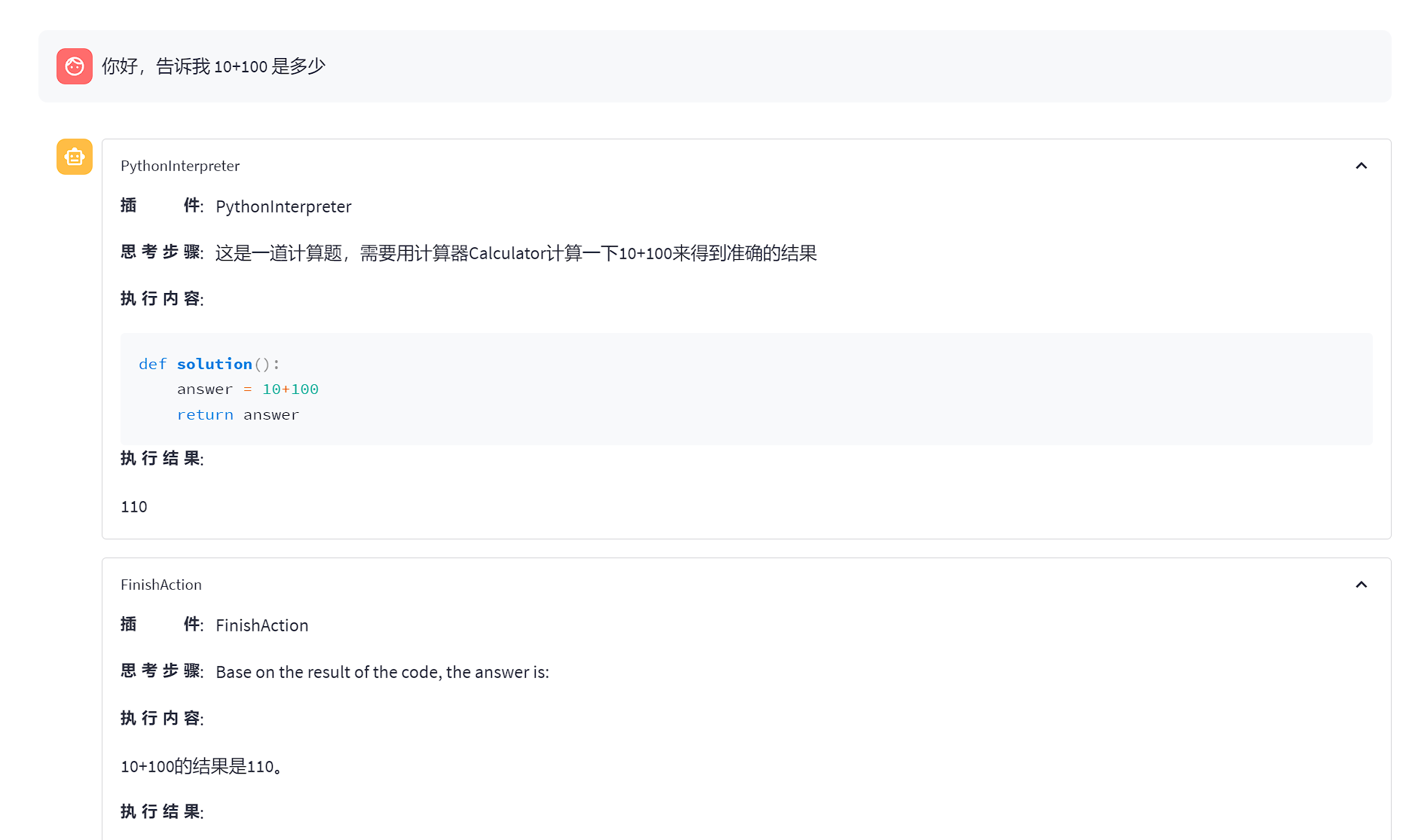 Lagent效果展示1
Lagent效果展示1
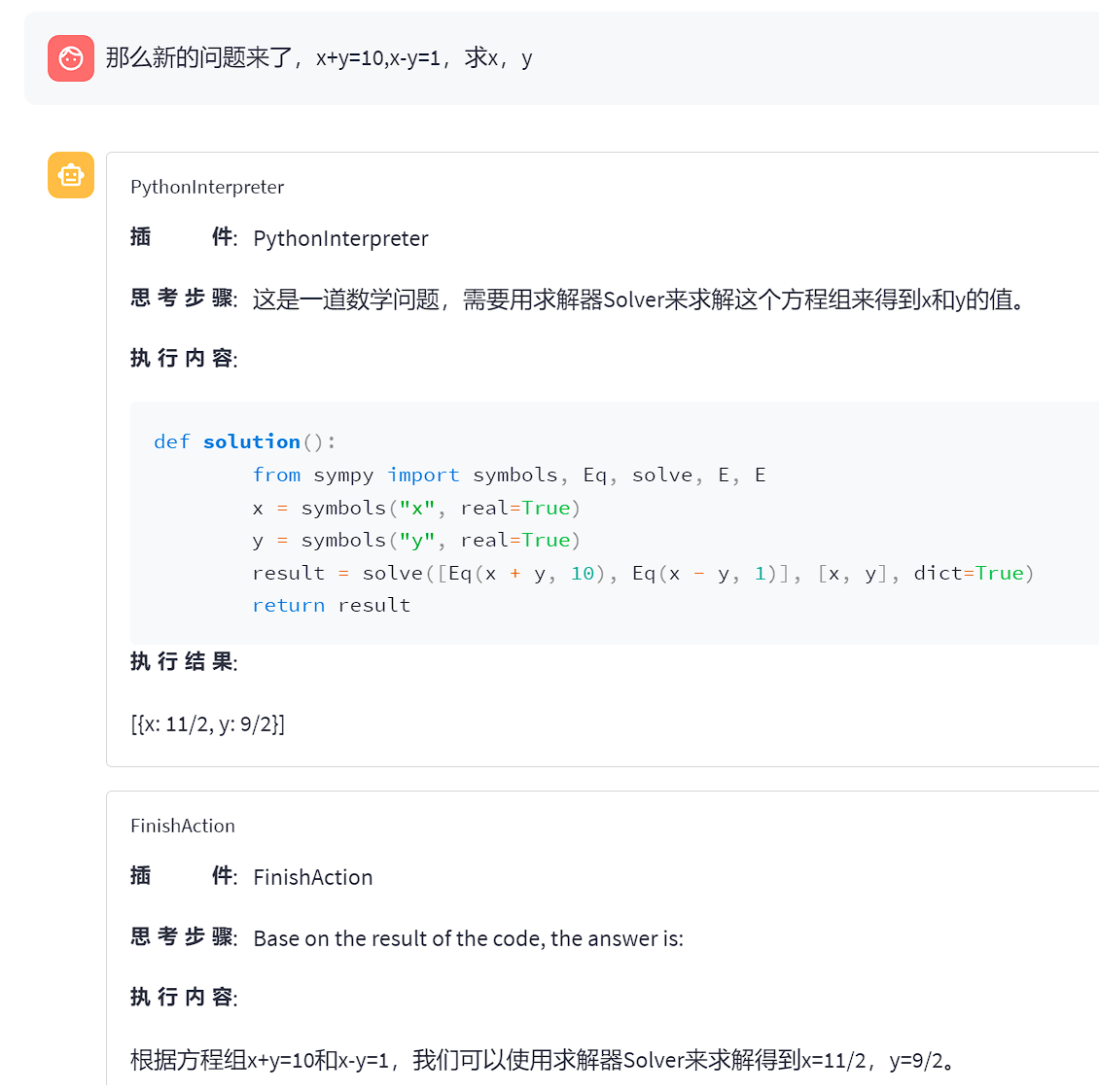 Lagent效果展示2
Lagent效果展示2
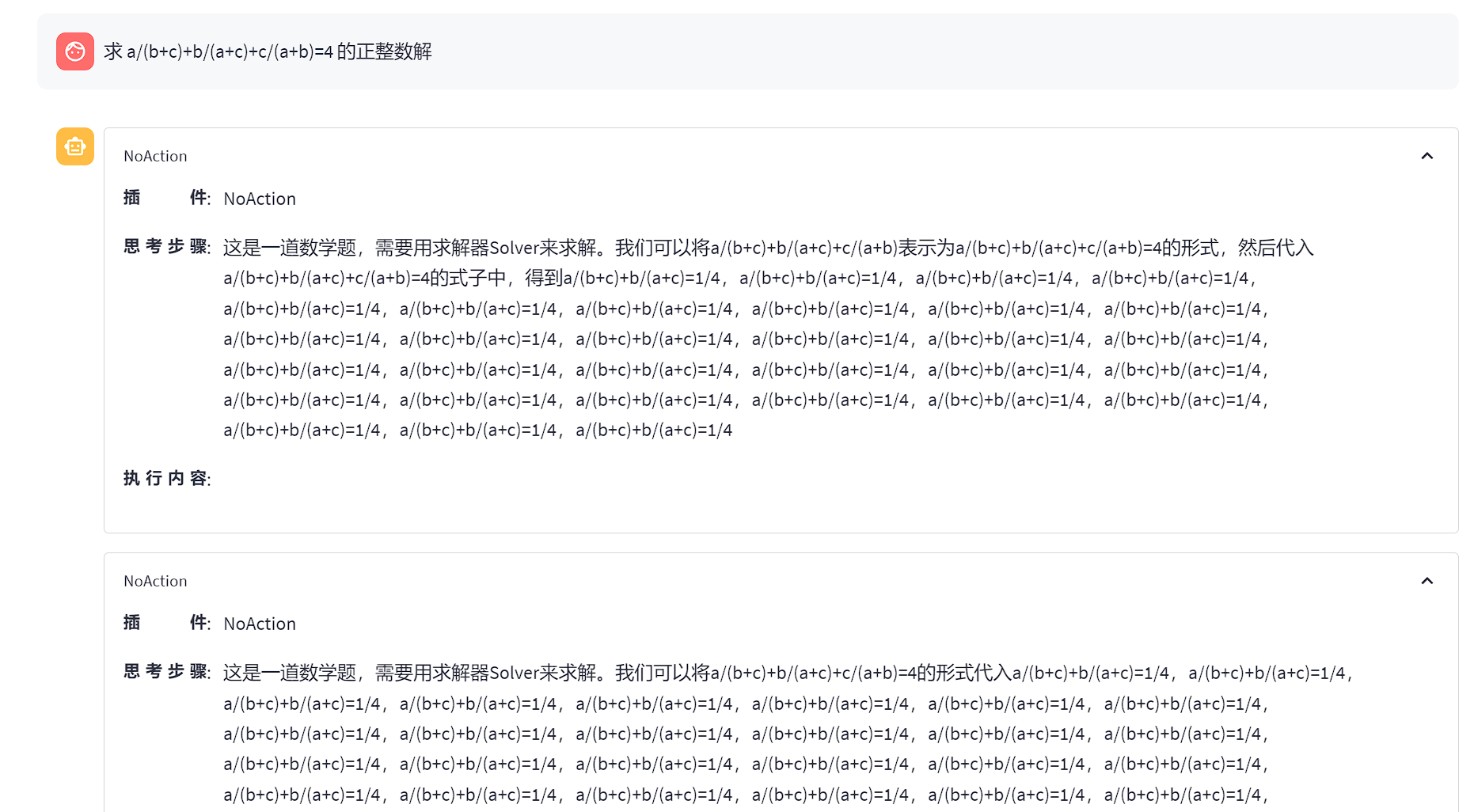 Lagent效果展示3
Lagent效果展示3
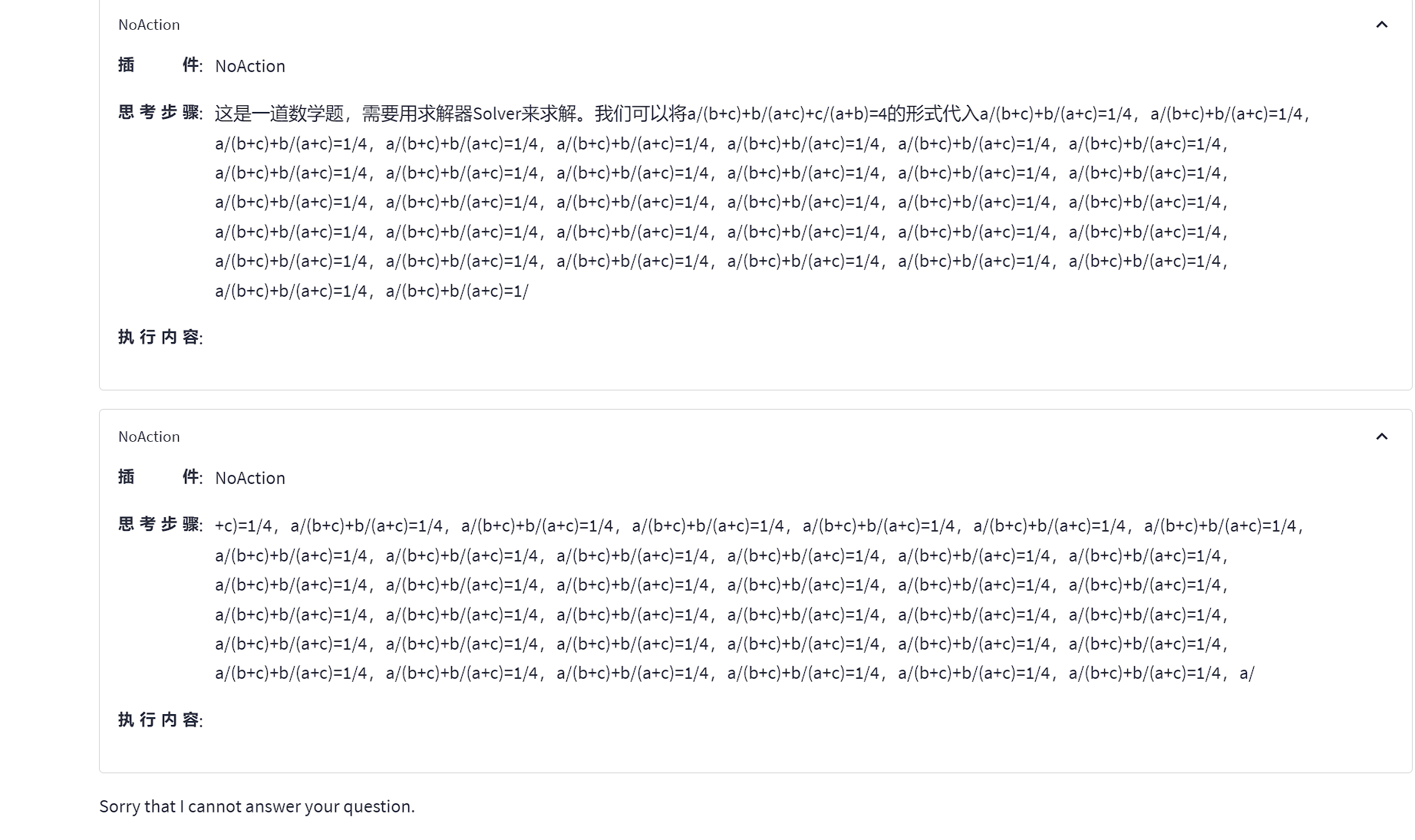 Lagent效果展示4
Lagent效果展示4
可以看到,lagent能够通过 python 代码解决一些数学问题,而对于很困难的数学问题,解决起来会出现一些问题。
浦语·灵笔图文理解创作 Demo
浦语·灵笔是基于书生·浦语大语言模型研发的视觉-语言大模型,提供出色的图文理解和创作能力,具有多项优势:
图文交错创作: 浦语·灵笔可以为用户打造图文并貌的专属文章。生成的文章文采斐然,图文相得益彰,提供沉浸式的阅读体验。这一能力由以下步骤实现:
- 理解用户指令,创作符合要求的长文章。
- 智能分析文章,自动规划插图的理想位置,确定图像内容需求。
- 多层次智能筛选,从图库中锁定最完美的图片。
基于丰富多模态知识的图文理解: 浦语·灵笔设计了高效的训练策略,为模型注入海量的多模态概念和知识数据,赋予其强大的图文理解和对话能力。
- 杰出性能: 浦语·灵笔在多项视觉语言大模型的主流评测上均取得了最佳性能,包括MME Benchmark (英文评测), MMBench (英文评测), Seed-Bench (英文评测), CCBench(中文评测), MMBench-CN (中文评测)。
demo 代码
1 | |
demo 运行方式
1 | |
效果展示
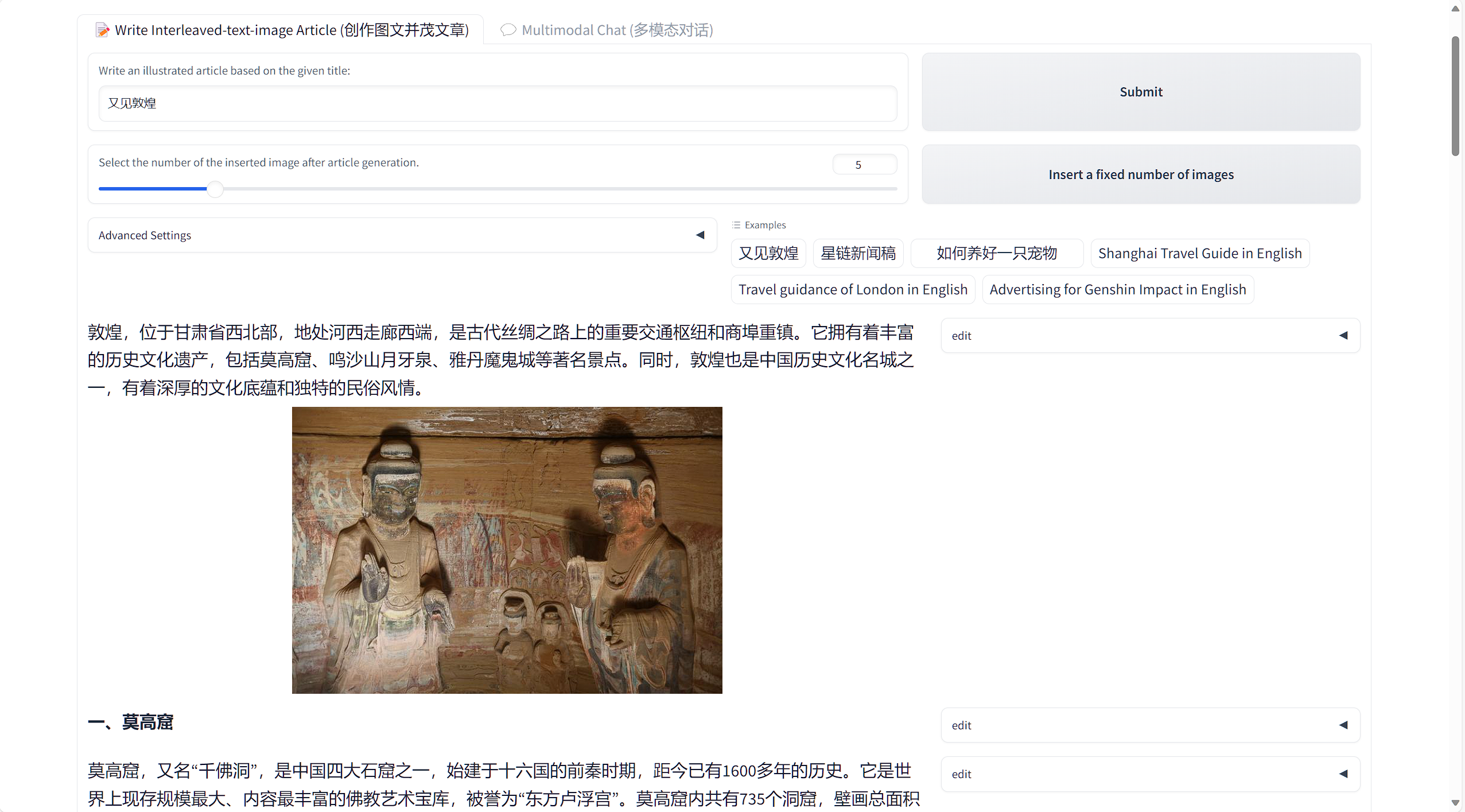 浦语·灵笔效果展示1
浦语·灵笔效果展示1
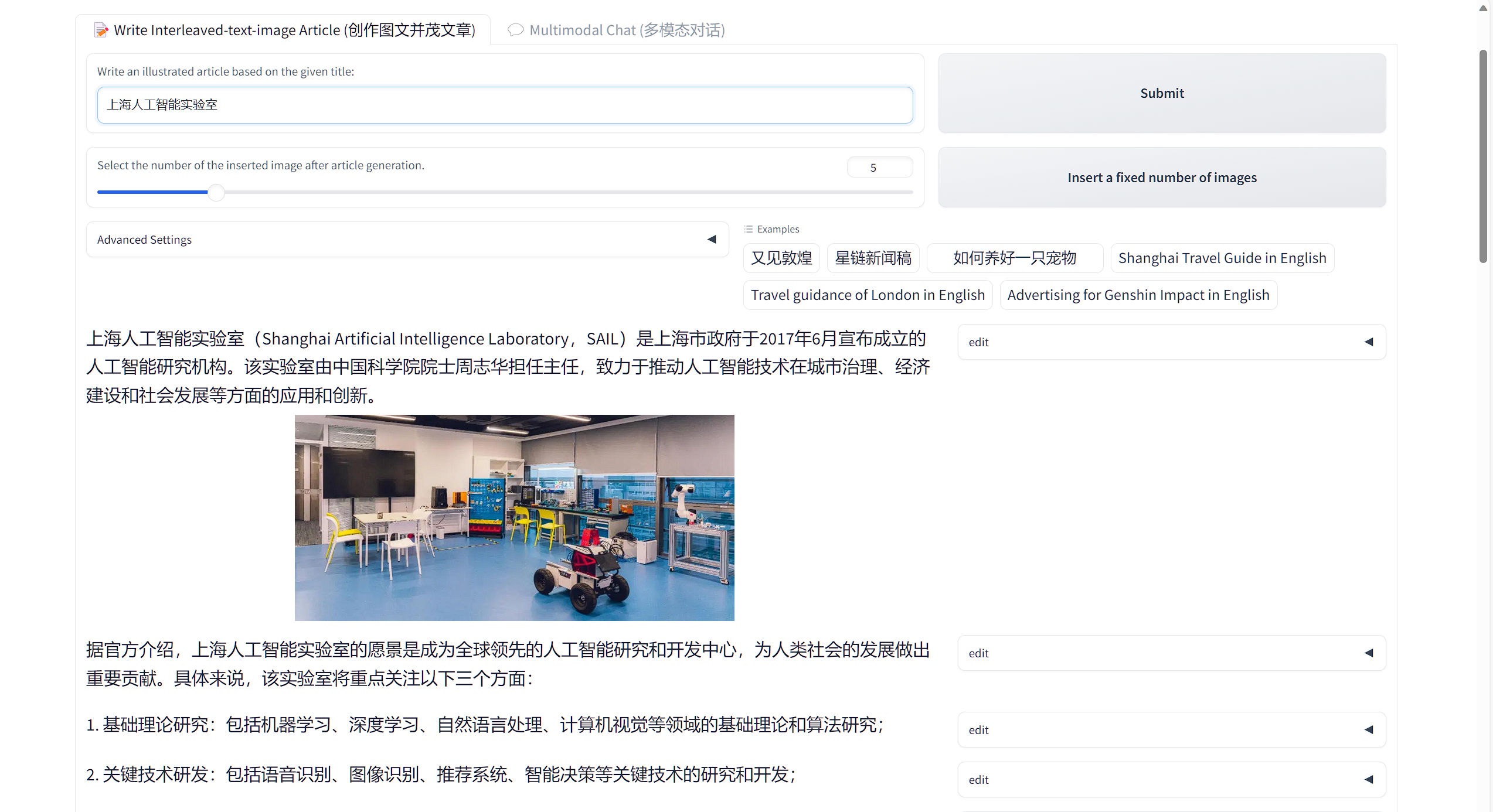 浦语·灵笔效果展示2
浦语·灵笔效果展示2
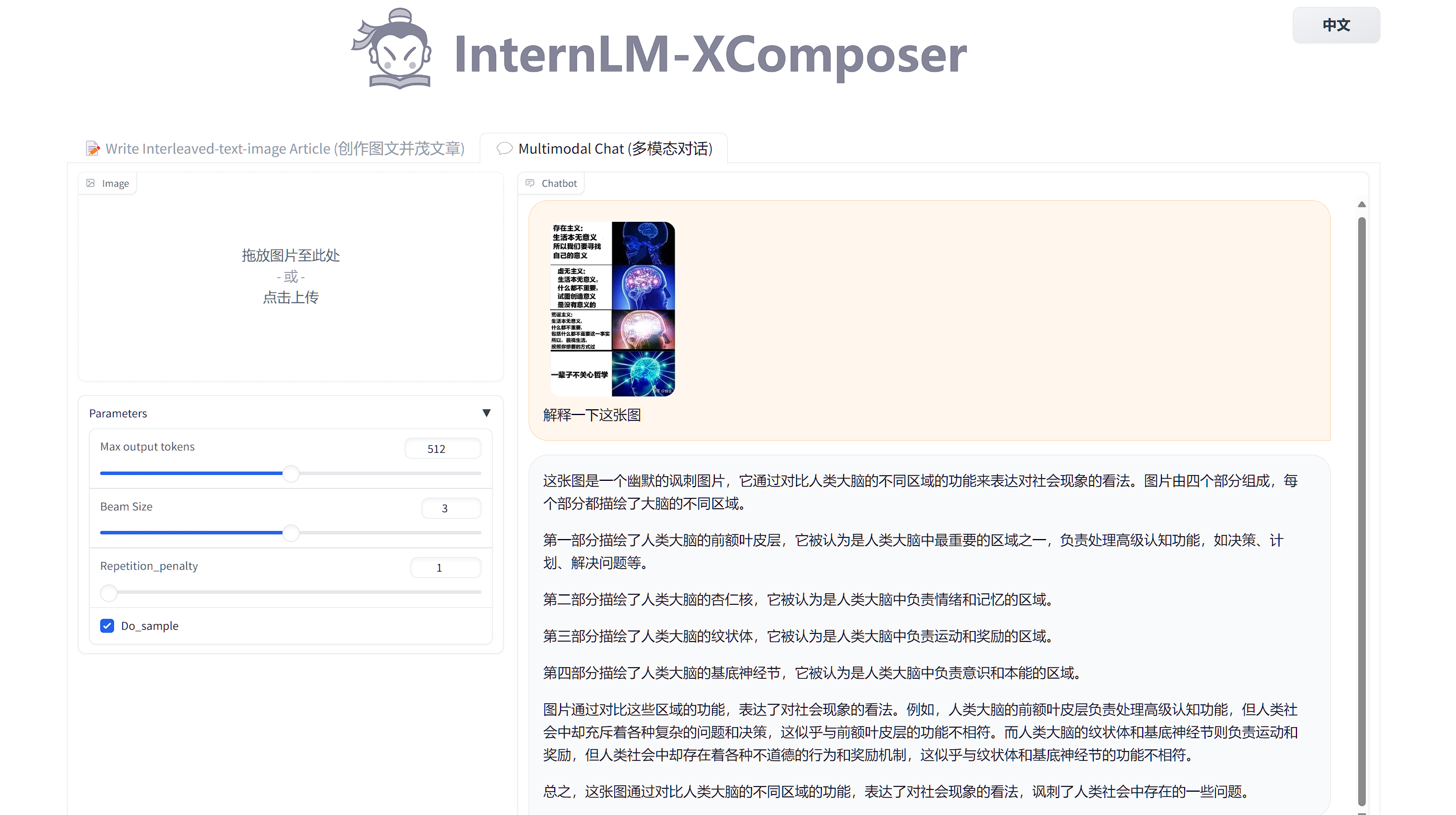 浦语·灵笔效果展示3
浦语·灵笔效果展示3
huggingface_hub 下载文件
 使用 huggingface_hub 库下载文件
使用 huggingface_hub 库下载文件
- 本文作者:EnableAsync
- 本文链接:https://enableasync.github.io/internlm/internlm-02/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!