
6.824 学习记录
Patterns and Hints for Concurrency in Go
Lecture 10: Guest Lecture on Go: Russ Cox - YouTube
https://www.youtube.com/watch?v=IdCbMO0Ey9I
Transcript:
okay uh good afternoon good morning good evening good night wherever you are uh let’s get started again uh so uh today we have a guest lecture and probably speaker that needs a little introduction uh uh there’s uh russ cox uh who’s one of the co-leads on the go uh project and you know we’ll talk a lot more about it uh let me say a couple words uh and not try to embarrass russ too much russia has a long experience with distributed systems uh he was a developer and contributor to plan nine uh when he was a high school
student and as an undergrad at harvard he joined the phd program at mit uh which is where we met up and probably if you’re taking any sort of you know pdos class if you will there’s going to be a you will see russ’s touches on it and certainly in 824 you know the the go switch to go for us has been a wonderful thing and uh but if you differ in opinion of course feel free to ask russ questions and make suggestions um he’s always welcome to uh entertain any ideas so with that russ it’s yours great
thanks can you still see the slides is that working okay great so um so we built go to support writing the sort of distributed systems that we were building at google and that made go a great fit for you know what came next which is now called cloud software and also a great fit for a24 um so in this lecture i’m going to try to explain how i think about writing some current programs in go and i’m going to walk through the sort of design and implementation of programs for four different patterns that i see come up often
and along the way i’m going to try to highlight some hints or rules of thumb that you can keep in mind when designing your own go programs and i know the syllabus links to an older version of these slides so you might have seen them already i hope that the lecture form is a bit more intelligible than just sort of looking at the slides um and i hope that in general these patterns are like common enough that you know maybe they’ll be helpful by themselves but also that you know you’ll you’ll the hints will help you prepare
for whatever it is you need to implement so to start it’s important to distinguish between concurrency and parallelism and concurrency is about how you write your programs about being able to compose independently executing control flows whether you want to call them processes or threads or go routines so that your program can be dealing with lots of things at once without turning into a giant mess on the other hand parallelism is about how the programs get executed about allowing multiple computations to run
simultaneously so that the program can be doing lots of things at once not just dealing with lots of things at once and so concurrency lends itself naturally to parallel execution but but today the focus is on how to use go’s concurrency support to make your programs clearer not to make them faster if they do get faster that’s wonderful but but that’s not the point today so i said i’d walk through the design and implementation of some programs for four common concur excuse me concurrency patterns that i see often
but before we get to those i want to start with what seems like a really trivial problem but that illustrates one of the most important points about what it means to use concurrency to structure programs a decision that comes up over and over when you design concurrent programs is whether to represent states as code or as data and by as code i mean the control flow in the program so suppose we’re reading characters from a file and we need to scan over a c style quoted string oh hello so the slides aren’t changing
yeah it will they well can you see prologue gorgeous for state right now no we see the title slide oh no yeah i was wondering about that because um there was like a border around this thing when i started and then it went away so let me let me just unshare and reshare i have to figure out how to do that in zoom uh unfortunately the keynote menu wants to be up and i don’t know how to get to the zoom menu um ah my screen sharing is paused why is my screen sharing paused can i resume there we go yeah all right i don’t know the zoom box says
your screen sharing is paused so if that now now the border’s back so i’ll watch that all right so um see i was back here so so you know we’re reading a string it’s not a parallel program it’s reading one character at a time so there’s no opportunity for parallelism but there is a good opportunity for concurrency so if we don’t actually care about the exact escape sequences in the string what we need to do is match this regular expression and we don’t have to worry about understanding it exactly
we’ll come back to what it means but but that’s basically all you have to do is implement this regular expression and so you know you probably all know you can turn a regular expression into a state machine and so we might use a tool that generates this code and in this code there’s a single variable state that’s the state of the machine and the loop goes over the state one character at a time reads a character depending on the state and the character changes to a different state until it gets to the end
and so like this is a completely unreadable program but it’s the kind of thing that you know an auto-generated program might look like and and the important point is that the program state is stored in data in this variable that’s called state and if you can change it to store the state in code that’s often clearer so here’s what i mean um suppose we duplicate the read care calls into each case of the switch so we haven’t made any semantic changes here we just took the read care that was at
the top and we moved it into the middle now instead of setting state and then immediately doing the switch again we can change those into go to’s and then we can simplify a little bit further there’s a go to state one that’s right before the state one label we can get rid of that then there’s a um i guess yeah so then there’s uh you know there’s only one way to get to state two so we might as well pull the state two code up and put it inside the if where the go to appears and then you know both sides of that if
now end in go to state one so we can hoist that out and now what’s left is actually a pretty simple program you know state zero is never jumped to so it just begins there and then state one is just a regular loop so we might as well make that look like a regular loop um and now like this is you know looking like a program and then finally we can you know get rid of some variables and simplify a little bit further and um and we can rotate the loop so that you know we don’t do a return true in the middle of the loop we do the
return true at the end and so now we’ve got this program that is actually you know reasonably nice and it’s worth mentioning that it’s possible to clean up you know much less egregious examples you know if you had tried to write this by hand your first attempt might have been the thing on the left where you’ve got this extra piece of state and then you can apply the same kinds of transformations to move that state into the actual control flow and end up at the same program that we have on the right that’s cleaner
so this is you know a useful transformation to keep in mind anytime you have state that kind of looks like it might be just reiterating what’s what’s happening in the program counter um and so you know you can see this if the the origin in the original state like if state equals zero the program counter is at the beginning of the function and if state equals one or if an escape equals false and the other version the per encounter is just inside the for loop and state equals two is you know further down in the for loop
and the benefit of writing it this way instead of with the states is that it’s much easier to understand like i can actually just walk through the code and explain it to you you know if you just read through the code you read an opening quote and then you start looping and then until you find the closing quote you read a character and if it’s a backslash you skip the next character and that’s it right you can just read that off the page which you couldn’t do in the original this version also happens to run
faster although that doesn’t really matter for us um but as i mentioned i’m going to highlight what i think are kind of important lessons as hints for designing your own go programs and this is the first one to convert data state into code state when it makes your programs clearer and again like these are all hints you should you shouldn’t you know for all of these you should consider it as you know only if it helps you can decide so one problem with this hint is that not all programs have the luxury of
having complete control over their control flow so you know here’s a different example instead of having a read care function that can be called this code is written to have a process care method that you have to hand the character to one at a time and then process care has no choice really but to you know encode its state in an explicit state variable because after every character it has to return back out and so it can’t save the state in the program counter in the stack it has to have the state in an actual variable but
in go we have another choice right because we can’t save the state on that stack and in that program counter but you know we can make another go routine to hold that state for us so supposing we already have this debugged read string function that we really don’t want to rewrite in this other way we just want to reuse it it works maybe it’s really big and hairy it’s much more complicated than the thing we saw we just want to reuse it and so the way we can do that and go is we can start a new go routine
that does the read string part and it’s the same read string code as before we pass in the character reader and now here the um you know the init method makes this this go routine to do the character reading and then every time the process care method is called um we send a message to the go routine on the car channel that says here’s the next character and then we receive a message back that says like tell me the current status and the current status is always either i need more input or you know it basically you know was it okay or not
and so um you know this lets us move the this the program counter that we we couldn’t do on the first stack into the other stack of the go routine and so using additional go teams is a great way to hold additional code state and give you the ability to do these kinds of cleanups even if the original structure the product the problem makes it look like you can’t but go ahead i i assume you’re fine with uh people asking questions yeah absolutely i just wanted to make sure that yeah yeah definitely please
interrupt um and so so the hint here is to use additional go routines to hold additional code state and there’s there’s one caveat to this and then it’s not free to to just make go routines right you have to actually make sure that they exit because otherwise you’ll just accumulate them and so you do have to think about uh you know why does the go routine exit like you know is it going to get cleaned up and in this case we know that you know q dot parse is going to return where you know parse go
sorry that’s not right um oh sorry the read string here read string is going to return any time it sends a a message that says need more input where’d it go there’s something missing from this slide sorry i went through this last night um so so as we go in we go into init we kick off this go routine it’s going to call read care a bunch of times and then we read the status once and that that first status is going to happen because the the first call to read care from read string is going to send i need
more input and then we’re going to send a character back um we’re going to send the character back in process care and then every time process care gets called it returns a status and so up until you get um you know need more input you’re going to get the um uh sorry this is not working um you’re going to get any more input for every time you want to read a character and then when it’s done reading characters what i haven’t shown you here what seems to be missing somehow is when things exit and when
things exit let’s see if it’s on this slide yeah so there’s a return success and a return bad input that i’d forgotten about and so uh you know these return a different status and then they’re done so when process care uh you know in in the read stream version when it returns you know bad input or success we we say that you know it’s done and so as long as the caller is going through and um you know calling until it gets something that’s not need more input then the go routine will finish but you
know maybe if we stop early if the caller like hits an eof and stops on its own without telling us that it’s done there’s a go routine left over and so that could be a problem and so you just you need to make sure that you know when and why each go routine will exit and the nice thing is that if you do make a mistake and you leave guardians stuck they just sit there it’s like the best possible bug in the world because they just sit around waiting for you to look at them and all you have to do is remember to
look for them and so you know here’s a very simple program at least go routines and it runs an http server and so you know if we run this it kicks off a whole bunch of effort routines and they all uh block trying to send to a channel and then it makes the http server and so if i run this program it just sits there and if i type control backslash on a unix system i get a sig quit which makes it crash and dump all the stacks of the go routines and you can see on the slide that you know it’s going to print over and over
again here’s the go routine in h called from g called from f and and in a channel send and if you look at the line numbers you can see exactly where they are another option is that since we’re in an http server and the hp server imports the net http prof package you can actually just visit the http server’s debug pprofgoreteen url which gives you the stacks of all the running go routines and unlike the crash dump it takes a little more effort and it deduplicates the go routines based on their stacks
and so and then it sorts them by how many there are of each stack and so if you have a go routine leak the leak shows up at the very top so in this case you’ve got 100 go routines stuck in h called from g call from f and then we can see there’s like one of a couple other go routines and we don’t really care about them and so you know this is a new hint that it just it’s really really useful to look for stucco routines by just going to this end point all right so that was kind of the warm-up now i
want to look at the first real concurrency pattern which is a publish subscribe server so publish subscribe is a way of structuring a program that you decouple the parts that are publishing interesting events from the things that are subscribing to them and there’s a published subscriber pub sub server in the middle that connects those so the individual publishers and the individual subscribers don’t have to be aware of exactly who the other ones are so you know on your android phone um an app might publish a make a phone
call event and then the the dialer might subscribe to that and actually start and you know help dial and and so in a real pub sub server there are ways to filter events based on like what kind they are so that when you publish and make a phone call event like it doesn’t go to your email program but you know for now we’re just going to assume that the filtering is taken care of separately and we’re just worried about the actual publish and subscribe and the concurrency of that so here’s an api we want to implement with any number of
clients that can call subscribe with a channel and afterwards events that are published will be sent on that channel and then when a client is no longer interested it can call cancel and pass in the same channel to say stop sending me events on that channel and the way that cancel will signal that it really is done sending events on that channel is it will close the channel so that the the receive the caller can can keep receiving events until it sees the channel get closed and then it knows that the cancel has taken effect
um so notice that the information is only flowing one way on the channel right you can send to the channel and then it the receiver can receive from it and the information flows from the sender to the receiver and it never goes the other way so closing is also a signal from the sender to the receiver but all the sending is over the receiver cannot close the channel to tell the sender like i don’t want you to send anymore because that’s information going the opposite direction and it’s just a lot easier to reason about
if the information only goes one way and of course if you need communication in both directions you can use a pair of channels and it often turns out to be the case that those uh different directions may have different types of data flowing like before we saw that there were runes going in one direction and status updates going in the other direction so how do we implement this api here’s a pretty basic implementation that you know could be good enough we have a server and the server state is a map of registered subscriber channels
protected by a lock we initialize the server by just allocating the map and then to publish the event we just send it to every registered channel to subscribe a new channel we just add it to the map and to cancel we take it out of the map and then because these are all um these are all methods that might be called from multiple go routines um we need to call lock and unlock around these to um you know protect the map and notice that i wrote defer unlock right after the lock so i don’t have to remember to unlock it later
uh you’ve probably all seen this you know it’s sort of a nice idiom to just do the lock unlock and then you know have a blank line and have that be its own kind of paragraph in the code one thing i want to point out is that using defer makes sure that the mutex gets unlocked even if you have multiple returns from the function so you can’t forget but it also makes sure that it gets unlocked if you have a panic like in subscribe and cancel where there’s you know panics for misuse and there is a subtlety here about if
you might not want to unlock the mutex if the panic happened while the thing that was locked is in some inconsistent state but i’m going to ignore that for now in general you try to avoid having the the things that might panic happen while you’re you know potentially an inconsistent state and i should also point out that the use of panic at all in subscribe and cancel implies that you really trust your clients not to misuse the interface that it is a program error worth you know tearing down the entire program
potentially for that to happen and in a bigger program where other clients were using this api you’d probably want to return an error instead and not have the possibility of taking down the whole program but panicking simplifies things for now and you know error handling in general is kind of not the topic today a more important concern with this code than panics is what happens if a go routine is slow to receive events so all the operations here are done holding the mutex which means all the clients kind of have to proceed in
lockstep so during publish there’s a loop that’s sending on the channels sending the event to every channel and if one subscriber falls behind the next subscriber doesn’t get the event until that slow subscriber you know wakes up and actually gets the the event off off that channel and so one slow subscriber can slow down everyone else and you know forcing them to proceed in lockstep this way is not always a problem if you’ve you know documented the restriction and for whatever reason you know how the
clients are are written and you know that they won’t ever fall too far behind this could be totally fine it’s a really simple implementation and um and it has nice properties like on return from publish you know that the event has actually been handed off to each of the other grow routines you don’t know that they’ve started processing it but you know it’s been handed off and so you know maybe that’s good enough and you could stop here a second option is that if you need to tolerate just a little bit of slowness
on the the subscribers then you could say that they need to give you a buffered channel with room for a couple events in the buffer so that you know when you’re publishing you know as long as they’re not too far behind there’ll always be room for the new event to go into the channel buffer and then the actual publish won’t block for too long and again maybe that’s good enough if you’re sure that they won’t ever fall too far behind you get to stop there but in a really big program you do want to cope more gracefully with
arbitrarily arbitrarily slow subscribers and so then the question is what do you do and so you know in general you have three options you can slow down the event generator which is what the previous solutions implicitly do because publish stops until the subscribers catch up or you can drop events or you can queue an arbitrary number of past events those are pretty much your only options so we talked about you know publish and slowing down the event generator there’s a middle ground where you coalesce the events or you drop them
um so that you know the subscriber might find out that you know hey you missed some events and i can’t tell you what they were because i didn’t save them but but i’m at least going to tell you you missed five events and then maybe it can do something else to try to catch up and this is the kind of approach that um that we take in the profiler so in the profiler if you’ve used it if uh there’s a go routine that uh fills the profile on on a signal handler actually with profiling events and then there’s a
separate go routine whose job is to read the data back out and like write it to disk or send it to a http request or whatever it is you’re doing with profile data and there’s a buffer in the middle and if the receiver from the profile data falls behind when the buffer fills up we start adding entries to a final profile entry that just has a single entry that’s that’s a function called runtime.
lost profile data and so if you go look at the profile you see like hey the program spent five percent of its time in lost profile data that just means you know the the profile reader was too slow and it didn’t catch up and and we lost some of the profile but we’re clear about exactly you know what the error rate is in the profile and you pretty much never see that because all the readers actually do keep up but just in case they didn’t you have a pretty clear signal um an example of purely dropping the events is the os signal package
where um you have to pass in a channel that will be ready to receive the signal a signal like sig hop or sig quit and when the signal comes in the run time tries to send to each of the channels that subscribe to that signal and if it can’t send to it it just doesn’t it’s just gone um because you know we’re in a signal handler we can’t wait and so what the callers have to do is they have to pass in a buffered channel and if they pass in a buffered channel that has you know length at least one
buffer length at least one and they only register that channel to a single signal then you know that if a signal comes in you’re definitely going to get told about it if it comes in twice you might only get told about it once but that’s actually the same semantics that unix gives to processes for signals anyway so that’s fine so those are both examples of dropping or coalescing events and then the third choice is that you might actually just really not want to lose any events it might just be really important that you
never lose anything in which case you know you can queue an arbitrary number of events you can somehow arrange for the program to just save all the events that the you know slow subscriber hasn’t seen yet somewhere and and give them to the subscriber later and it’s really important to think carefully before you do that because in a distributed system you know there’s always slow computers always computers that have fallen offline or whatever and they might be gone for a while and so you don’t want to introduce
unbounded queuing in general you want to think very carefully before you do that and think well you know how unbounded is it really and can i tolerate that and so like that’s a reason why channels don’t have just an unbounded buffering it’s really almost never the right choice and if it is the right choice you probably want to build it very carefully um and so but we’re going to build one just to see what it would look like and before we do that i just want to adjust the program a little bit so we have this mutex in the code
and the mutex is an example of of keeping the the state whether you’re locked or not in a state variable but we can also move that into a program counter variable by putting it in a different go routine and so in this case we can start a new go routine that runs a program a function called s dot loop and it handles requests sent on three new channels publish subscribe and cancel and so in init we make the channels and then we we kick off s dot loop and s dot loop is sort of the amalgamation of the previous method
bodies and it just receives from any of the three channels a request a publish a subscriber a cancel request and it does whatever was asked and now that map the subscriber map can be just a local variable in s dot loop and and so um you know it’s the same code but now that data is clearly owned by s.
loop nothing else could even get to it because it’s a local variable and then we just need to change the original methods to send the work over to the loop go routine and so uppercase publish now sends on lowercase publish the channel the event that it wants to publish and similarly subscribe and cancel they create a request that has a channel uh that we want to subscribe and also a channel to get the answer back and they send that into the loop and then the loop sends back the answer and so i referred to transforming the program this way as like converting the
mutex into a go routine because we took the data state of the mutex there’s like a lock bit inside it and now that lock bit is implicit in the program counter of the loop um it’s very clear that you can’t ever have you know a publish and subscribe happening at the same time because it’s just single threaded code and just you know executes in sequence on the other hand the the original version had a kind of like clarity of state where you could sort of inspect it and and reason about well this is the
important state and and it’s harder in the go routine version to see like what’s important state and what’s kind of incidental state from just having a go routine and in a given situation you know one might be more important than the other so a couple years ago i did all the labs for the class when it first switched to go and and raft is a good example of where you probably prefer the state with the mutex is because raft is is so different from most concurrent programs and that like each replica is just kind of profoundly
uncertain of its state right like the state transitions you know one moment you think you’re the leader and the next moment you’ve been deposed like one moment your log has ten entries the next moment you find actually no it only has two entries and so being able to manipulate that state directly rather than having to you know somehow get it in and out of the program counter makes a lot more sense for raft but that’s pretty unique in most situations it cleans things up to put the state in the program counter
all right so in order to deal with the slow subscribers now we’re going to add some helper go routines and their job is to manage a particular subscriber’s backlog and keep the overall program from blocking and so this is the helper go team and the the the main loop go routine will send the events to the helper which we then trust because we wrote it not to fall arbitrarily behind and then the helpers job is to cue events if needed and send them off to the subscriber all right so this actually has um two
problems the first is that if there’s nothing in the queue then the select is actually wrong to try to offer q of zero and in fact just evaluating q of zero at the start of the select will panic because the queue is empty and so we can fix these by setting up the arguments separately from the select and in particular we need to make a channel send out that’s going to be nil which is never able to proceed in a select um as we know when we don’t want to send and it’s going to be the actual out channel when we do want to send and
then we have to have a separate variable that holds the event that we’re going to send it will only you know actually read from q of 0 if there’s something in the queue the second thing that’s wrong is that we need to handle closing of the channel of the input channel because when the input channel closes we need to flush the rest of the queue and then we need to close the output channel so to check for that we change the select from just doing e equals receive from n to e comma okay equals receive from n and the comma
okay we’ll be told whether or not the channel is actually sending real data or else it’s closed and so when okay is false we can set into nil to say let’s stop trying to receive from in there’s nothing there we’re just going to keep getting told that it’s closed and then when the loop is fine when the queue is finally empty we can exit the loop and so we change the for condition to say we want to keep exiting the loop as long as there actually still is an input channel and there’s something
to write back to the output channel and then once both of those are not true anymore it’s time to close it’s time to exit the loop and we close the output channel and we’re done and so now we’ve correctly propagated the closing of the input channel to the output channel so that was the helper and the server loop used to look like this and to update it we just changed the subscription map before it was a map from subscribe channels to bools it was just basically a set and now it’s a map from subscribe
channel to helper channel and every time we get a new subscription we make a helper channel we kick off a helper go routine and we record the helper channel in the subscription map instead of the the actual channel and then the rest of uh the rest of the the loop actually barely changes at all so i do want to point out that like if you wanted to have a different strategy for you know what you do with uh clients that fall too far behind that can all go in the helper go routine the code on the screen right now is completely unchanged so we’ve we’ve
completely separated the publish subscribe maintaining the the actual list of subscribers map from the what do you do when things get too slow map or problem and so it’s really nice that you’ve got this clean separation of concerns into completely different go routines and that can help you you know keep your program simpler and so that’s the general hint is that you can use go routines a lot of the time to separate independent concerns all right so um the second pattern for today is a work scheduler
and you did one of these in lab one for mapreduce and i’m just gonna you know build up to that and and this doesn’t do all the rpc stuff it just kind of assumes that there’s kind of channel channel based interfaces to all the the servers so you know we have this function scheduled it takes a fixed list of servers has a number of tasks to run and it has just this abstracted function call that you you call to run the task on a specific server you can imagine it was you know doing the rpcs underneath so we’re going to need some way to keep
track of which servers are available to execute new tasks and so one option is to use our own stack or queue implementation but another option is to use a channel because it’s a good synchronized queue and so we can send into the channel to add to the queue and receive from it to pop something off and in this case we’ll make the queue be a queue of servers and we’ll start off it’s a queue of idle servers servers that aren’t doing any work for us right now and we’ll start off by just initializing
it by sending all the known servers into the idle list and then we can loop over the tasks and for every task we kick off a go routine and its job is to pull a server off the idle list run the task and then put the server back on and this loop body is another example of the earlier hint to use guaranteeing select independent things run independently because each task is running as a separate concern they’re all running in parallel unfortunately there are two problems with this program the first one is that the closure that’s
running as a new go routine refers to the loop iteration variable which is task and so by the time the go routine starts exiting you know the loop has probably continued and done at task plus plus and so it’s actually getting the wrong value of task you’ve probably seen this by now um and of course the best way to to catch this is to run the race detector and at google we even encourage teams to set up canary servers that run the race detector and split off something like you know 0.
1 percent of their traffic to it just to catch um you know races that might be in the production system and you know finding a bug with a race detector is is way better than having to debug some you know corruption later so there are two ways to fix this race the first way is to give the closure an explicit parameter and pass it in and the go statement requires a function call specifically for this reason so that you can set specific arguments that get evaluated in the context of the original go routine and then get copied to the new
go routine and so in this case we can declare a new argument task two we can pass task to it and then inside the go routine task 2 is a completely different copy of of task and i only named it task 2 to make it easier to talk about but of course there’s a bug here and the bug is that i forgot to update task inside the function to refer to task two instead of task and so we basically never do that um what we do instead is we just give it the same name so that it’s impossible now for the code inside the go regime to
refer to the wrong copy of task um that was the first way to fix the race there’s a second way which is you know sort of cryptic the first time you see it but it amounts to the same thing and that is that you just make a copy of the the variable inside the loop body so every time a colon equals happens that creates a new variable so in the for loop in the outer for loop there’s a colon equals at the beginning and there’s not one the rest of the loop so that’s all just one variable for the entire loop
whereas if we put a colon equals inside the body every time we run an iteration of the loop that’s a different variable so if the guard if the go function closure captures that variable those will all be distinct so we can do the same thing we do task two and this time i remember to update the body but you know just like before it’s too easy to forget to update the body and so typically you write task colon equals task which looks kind of magical the first time you see it but but that’s what it’s for
all right so i said there were two bugs in the program the first one was this race on task and the second one is that uh we didn’t actually do anything after we kicked off all the tasks we’re not waiting for them to be done um and and in particular uh we’re kicking them off way too fast because you know if there’s like a million tasks you’re going to kick off a million guard teams and they’re all just going to sit waiting for one of the five servers which is kind of inefficient and so what
we can do is we can pull the fetching of the the next idle server up out of the go routine and we pull it up out of the go routine now we’ll only kick off a go routine when there is a next server to use and then we can kick it off and and you know use that server and put it back and the using the server and put it back runs concurrently but doing the the fetch of the idle server inside the loop slows things down so that there’s only ever now number of servers go routines running instead of number of tasks
and that receive is essentially creating some back pressure to slow down the loop so it doesn’t get too far ahead and then i mentioned we have to wait for the task to finish and so we can do that by just at the end of the loop uh going over the the list again and pulling all the servers out and we’ve pulled you know the right number of servers out of the idle list that means they’re all done and so that’s that’s the full program now to me the most important part of this is that you still get to write a for
loop to iterate over the tasks there’s lots of other languages where you have to do this with state machines or some sort of callbacks and you don’t get the luxury of encoding this in the control flow um and so this is a you know much cleaner way where you can just you know use a regular loop but there are some some changes we could make some improvements and so one improvement is to notice that there’s only one go routine that makes requests of a server at a particular time so instead of having one go routine per
task maybe we should have one go routine per server because there are probably going to be fewer servers than tasks and to do that we have to change from having a channel of idle servers to a channel of you know yet to be done tasks and so we’ve renamed the idle channel to work and then we also need a done channel to count um you know how many uh tasks are done so that we know when we’re completely finished and so here there’s a new function run tasks and that’s going to be the per server function and we kick off one of
them for each server and run tasks his job is just to loop over the work channel run the tasks and when the server is done we send true to done and the you know the server tells us that you know it’s done and the server exits when the work channel gets closed that’s what makes that for loop actually stop so then you know having kicked off the servers we can then just sit there in a loop and send each task to the work channel close the work channel and say hey there’s no more work coming all the servers you should finish and then and
then exit and then wait for all the servers to tell us that they’re done so in the lab there were a couple complications one was that you know you might get new servers at any given time um and so we could change that by saying the servers come in on a channel of strings and and that actually fits pretty well into the current structure where you know when you get a new server you just um kick off a new uh run tasks go routine and so the only thing we have to change here is to put that loop into its own go routine so that while
we’re sending tasks to servers we can still accept new servers and kick off the helper go routines but now we have this problem that we don’t really have a good way to tell when all the servers are done because we don’t know how many servers there are and so we could try to like maintain that number as servers come in but it’s a little tricky and instead we can count the number of tasks that have finished so we just move the done sending true to done up a line so that instead of doing it per server
we now do it per task and then at the end of the loop or at the end of the function we just have to wait for the right number of tasks to be done and so so now again we sort of know uh why these are gonna the finish um there’s actually a deadlock still and that is that if the the number of tasks is um is too big actually i think always you you’ll get a deadlock and if you run this you know you get this nice thing where the dirt it tells you like hey your routines are stuck and the problem is that you know we have this run task uh
server loop and the server loop is trying to say hey i’m done and you’re trying to say hey like here’s some more work so if you have more than one task you’ll run into this deadlock where you know you’re trying to send the next task to a server i guess that is more task than servers you’re trying to send the next task to a server and all the servers are trying to say hey i’m done with the previous task but you’re not there to receive from the done channel and so again you know it’s really nice
that the the guardians just hang around and wait for you to look at them and we can fix this one way to fix this would be to add a separate loop that actually does a select that either sends some work or accounts for some of the work being done that’s fine but a cleaner way to do this is to take the the work sending loop the task sending loop and put it in its own go routine so now it’s running independently of the counting loop and the counting loop can can run and you know unblock servers that are done with certain tasks while
other tasks are still being sent but the simplest possible fix for this is to just make the work channel big enough that you’re never gonna run out of space because we might decide that you know having a go routine per task is you know a couple kilobytes per task but you know an extra inch in the channel is eight bytes so probably you can spend eight bytes per task and so if you can you just make the work channel big enough that you know that all the sends on work are going to never block and you’ll always get down to the the counting loop
at the end pretty quickly and so doing that actually sets us up pretty well for the other wrinkle in the lab which is that sometimes calls can time out and here i’ve modeled it by the call returning a false so just say hey it didn’t work um and so you know in run task it’s really easy to say like if it’s really easy to say like if the call uh fails then or sorry if the call succeeds then you’re done but if it fails just put the task back on the work list and because it’s a queue not a stack
putting it back on the work list is very likely to hand it to some other server um and so that will you know probably succeed because it’s some other server i mean this is all kind of hypothetical but um uh it’s a really you know it fits really well into the structure that we’ve created all right and the final change is that because the server guarantees are sending on work we do have to uh wait to close it until we know that they’re done sending and uh because again you can’t close you know before they finish sending
and so we just have to move the close until after we’ve counted that all the tasks are done um and you know sometimes we get to this point and people ask like why can’t you just kill go routines like why not just be able to say look hey kill all the server guardians at this point we know that they’re not needed anymore and the answer is that you know the go routine has state and it’s interacting with the rest of the program and if it all of a sudden just stops it’s sort of like it hung right and
maybe it was holding a lock maybe it was in the middle of some sort of communication with some other guru team that was kind of expecting an answer so we need to find some way to tear them down more gracefully and that’s by telling them explicitly hey you know you’re done you can you can go away and then they can clean up however they need to clean up um you know speaking of cleaning up there’s there’s actually one more thing we have to do which is to shut down the loop that’s that’s watching for new
servers and so we do have to put a select in here where uh you know the the thing that’s waiting for new servers on the server channel we have to tell it okay we’re done just like stop watching for new servers because all the servers are gone um and we could make this the caller’s problem but but this is actually fairly easy to do all right so um pattern number three which is a a client for a replicated server of service so here’s the interface that we want to implement we have some service that we want that is replicated for
reliability and it’s okay for a client to talk to any one of these servers and so the the replicated client is given a list of servers the uh the arguments to init is a list of servers and a function that lets you call one of the servers with a particular argument set and get a reply and then being given that during init the replicated client then provides a call method that doesn’t tell you what server it’s going to use it just finds a good server to use and it keeps the same keeps using the same server for as long as it can until
it finds out that that server is no good so in this situation there’s almost no shared state that you need to isolate and so like the only state that persists from one call to the next is what server did i use last time because i’m going to try to use that again so in this case that’s totally fine for a mutex i’m just going to leave it there it’s always okay to use mutex if that’s the cleanest way to write the code you know some people get the wrong impression from how much we talk about
channels but it’s always okay to use a mutex if that’s all you need so now we need to implement this replicated call method whose job is to try sending to lots of different servers right but but first to try the the original server so so what does it mean if you know the try fails well there’s like no clear way for it to fail above it just always returns a reply and so the only way it can fail is if it’s taking too long so we’ll assume that if it takes too long that means it failed so in order to deal with timeouts we
have to run that that code in the background in a different go routine so we can do something like this um where we set a timeout we create a timer and then we use the go routine to send in the background and then at the end we wait and either we get the timeout or we get the actual reply if we get the actual reply we return it if we get the timeout we have to do something we’ll have to figure out what to do um it’s worth pointing out that you have to call tdot stop because otherwise the timer sits in a timer queue that you
know it’s going to go off in one second and so you know if this call took a millisecond and you have this timer that’s going to sit there for the next second and then you do this in a loop and you get a thousand timers sitting in that that um that queue before they start actually you know um disappearing and so this is kind of a wart in the api but it’s been there forever and we’ve never fixed it um and and so you just have to remember to call stop uh and then you know now we have to figure out what do we do in the case of
the timeout and so in the case of the timeout we’re going to need to try a different server so we’ll write a loop and we’ll start at um the id that id0 it says and you know if a reply comes in that’s great and otherwise we’ll reset the timeout and go around the loop again and try sending to a different server and notice there’s only one done channel in this program and so you know on the third iteration of the loop we might be waiting and then finally the first server gives us a reply that’s totally fine we’ll
take that reply that’s great um and so then we’ll stop and return it and but if we get all the way through the loop it means that we’ve sent the request to every single server in which case there’s no more timeouts we just have to wait for one of them to come back and so that’s the the plain receive and the return at the end and then it’s important to notice that the done channel is buffered now so that if you know you’ve sent the result to three different servers you’re going to take the first reply and
return but the others are going to want to send responses too and we don’t want those go routines to just sit around forever trying to send to a channel that we’re not reading from so we make the buffer big enough that they can send into the buffer and then go away and the channel just gets garbage collected that says like why can’t the timer just be garbage collected when nobody’s referencing it instead of having to to wait when it goes off when you said that you have multiple waiting if it goes off in one
millisecond yeah the the problem is the timer is referenced by the the run time it’s in the list of active timers and so calling stop takes it out of the list of active timers and and so like that’s arguably kind of a wart in that like in the specific case of a timer that’s like only going to ever get used in this channel way like we could have special case that by like having the channel because inside the timer is this t.
c channel right so we could have had like a different kind of channel implementation that inside had a bit that said hey i’m a timer channel right and and and then like the select on it would like know to just wait but if you just let go of it it would just disappear we’ve kind of like thought about doing that for a while but we never did and so this is like the state of the world um but but you know the garbage collector can’t distinguish between you know the reference inside the runtime and the reference and the rest
of the program it’s all just references and so until we like special case that channel in some way like we we can’t actually get rid of that thank you sure so um so then the only thing we have left is to have this preference where we try to use the same um id that we did the previous time and so to do that preference um we you know had the server id coming back in the reply anyway in the result channel and so you know we do the same sort of loop but we loop over an offset from the actual id we’re going to use which is
the pre the preferred one and then when we get an answer we uh set the preferred one to where we got the answer from and then we reply and you’ll notice that i used a go to statement that’s okay if you need to go to it’s fine um it’s not sort of there’s no zealotry here all right so uh the fourth one and then we’ll we’ll do some questions um is a protocol multiplexer and this is kind of the logic of a core of any rpc system and and this comes up a lot i feel like i wrote a lot of these in grad school
and sort of years after that and so the basic api of a protocol multiplexer is that it sits in from some service which we’re going to pass to the init method and then having been initialized with a service you can call and you can call call and give it a message a request message and then it’ll you know give you back the reply message at some point and the things it needs from the service to do multiflexing is that given a message it has to be able to pull out the tag that uniquely identifies the message
and and will identify the the reply because it will come back in with a matching tag and then it needs to be able to send a message out and to receive you know a message but the send and receive um are there arbitrary messages that are not matched it’s the multiplexer’s job to actually match them so um to start with we’ll have a go routine that’s in charge of calling send and another group team that’s in charge of calling receive both in just a simple loop and so to initialize the service we’ll
set up the structure and then we’ll kick off the send loop and the receive loop and then we also have a map of pending requests and the map it maps from the tag that we saw the id number in the messages to a channel where the reply is supposed to go the send loop is fairly simple you just range over the things that need to be sent and you send them and this just has the effect of serializing the calls to send because we’re not going to force the service implementation to you know deal with us sending you know from multiple
routines at once we’re serializing it so that it can just be thinking of you know sending one one packet at a time and then the receive loop uh is a little bit more complicated it pulls a receive it pulls a reply off the the service and again they’re serialized so we’re only reading one at a time and then it pulls the tag out of the reply and then it says ah i need to find the channel to send this to uh so it pulls the channel out of the pending map it takes it out of the pending map so that you know if we
accidentally get another one we won’t try to send it and then it sends the reply and then to do a call you just have to set yourself up in the map and then hand it to send and wait for the reply so we start off we get the tag out we make our own done channel we insert the tag into the map after first checking for bugs and then we send the the argument message to send and then we wait for the reply to come in undone it’s very very simple i mean like i used to write these sort of things in c and it was it was much much worse
so that was all the patterns that i wanted to show and um you know i hope that those end up being useful for you in whatever future program you’re writing and and i hope that they’re you know just sort of good ideas even in non-go programs but that you know thinking about them and go can help you when you go to do other things as well so i’m gonna put them all back up and then um i have some questions that fran sent that were you know from all of you and um we’ll probably have some time for uh you know questions from from the chat
as well i have no idea in zoom where the chat window is so when we get to that people can just speak up just i don’t use zoom on a daily basis unfortunately um so uh and and normally i know how to use zoom like regularly but with with the presentation it’s like zoom is in this minimize thing that doesn’t have half the things i’m used to anyway um someone asked how long ago took and so far it’s been about 13 and a half years we started discussions in late september 2007 i joined full-time in august 2008 when i
finished at mit we did the initial open source launch november 2009 we released go one the sort of first stable version in october 2011. uh or sorry the plan was october 2011. go one itself was march 2012. and then we’ve just been on you know it’s a regular schedule since then the next major change of course is is going to be generics and um and adding generics and that’s probably going to be go 118 which is going to be next in february someone asked you know how big a team does it take to build a language like go
and you know for those first two years there were just five of us and and that was enough to get us to uh you know something that we released that actually could run in production but it was fairly primitive um you know it was it was a good prototype it was a solid working prototype but but it wasn’t like what it is today and over time we’ve expanded a fair amount now we’re up to something like 50 people employed directly or employed by google to work directly on go and then there’s tons of open source
contributors i mean there’s literal cast of thousands that have helped us over the last 13 years and there’s absolutely no way we could have done it even with 50 people without all the different contributions from the outside someone asked about design priorities um and and motivations and you know we we built it for us right the priority was to build something that was gonna help google and it just turned out that google was like a couple years ahead we were just in a really lucky spot where google was a
couple years ahead of the rest of the industry on having to write distributed systems right now everyone using cloud software is is writing programs that talk to other programs and sending messages and you know there’s hardly any single machine programs anymore and so you know we sort of locked into at some level you know building the language that we that the rest of the world needed a couple years later and and then the other thing that that was really a priority was making it work for large numbers of programmers and because
you know google had a very large number of programmers working in one code base and and now we have open source where you know even if you’re a small team you’re depending on code that’s written by a ton of other people usually and so a lot of the the issues that come up with just having many programmers still come up in that context so those were really the things we were trying to solve and you know for all of these things we we took a long time before we were willing to actually commit to putting something in the
language like everyone basically had to agree in the the core original group and and so that meant that it took us a while to sort of get the pieces exactly the way we wanted them but once we got them there they’ve actually been very stable and solid and really nice and they work together well and and the same thing is kind of happening with generics now where we actually feel i feel personally really good about generics i feel like it feels like the rest of go and that just wasn’t the case for the proposals
that we had you know even a couple years ago much less the you know early ones uh someone said they they really like defer uh which is unique to language and and i do too thank you um but i wanted to point out that you know we we did absolutely you know create defer for go but um swift has adopted it and i think there’s a proposal for sipos bus to adopt it as well so you know hopefully it kind of moves out a little bit there was a question about um go and using capitalization for exporting and which i know is like something that
uh you know sort of is jarring when you first see it and and the story behind that is that well we needed something and we knew that we would need something but like at the beginning we just said look everything’s exported everything’s publicly visible we’ll deal with it later and after about a year it was like clear that we needed some way to you know let programmers hide things from other programmers and you know c plus plus has this public colon and private colon and in a large struct it’s actually
really annoying that like you’re looking you’re in the you’re looking at definitions and you have to scroll backwards and try to find where the like most recent public colon or private colon was and if it’s really big it can be hard to find one and so it’s like hard to tell whether a particular definition is public or private and then in java of course it’s at the beginning of every single field and that seemed kind of excessive too it’s just too much typing and so we looked around some more and
and someone pointed out to us that well python has this convention where you put an underscore in front to make something hidden and that seemed interesting but you probably don’t want the default to be not hidden you want the default to be hidden um and then we thought about well we could put like a plus in front of names um and then someone suggested well like what about uppercase could be exported and it seemed like a dumb terrible idea it really did um but as you think about it like i really didn’t like this idea um and i
have like very clear memory of sitting of like the room and what i was staring at as we discussed this uh but i had no logical argument against it and it turned out it was fantastic it was like it seemed bad it just like aesthetically but it is one of my favorite things now about go that when you look at a use of something you can see immediately you get that bit of is this something that other people can access or not at every use because if you know you see code calling a function to do you know whatever it is that it does you
think oh wow like can other people do that and and you know your brain sort of takes care of that but now i go to c plus and i see calls like that and i get really worried i’m like wait is that is that something other classes can get at um and having that bid actually turns out to be really useful for for reading code a couple people asked about generics if you don’t know we have an active proposal for generics we’re actively working on implementing it we hope that the the release later in the year
uh towards the end of the year will actually have you know a full version of generics that you can you can actually use the the um that’ll be like a preview release the real release that we hope it will be in is go 118 which is february of next year so maybe next class uh we’ll actually get to use generics we’ll see but i’m certainly looking forward to having like a generic min and max the reason we don’t have those is that you’d have to pick which type they were for or have like a whole suite of them
and it just seemed silly it seemed like we should wait for generics um someone asked is there any area of programming where go may not be the best language but it’s still used and and the answer is like absolutely like that happens all the time with every language um i think go is actually really good all around language um but you know you might use it for something that’s not perfect for just because the rest of your program is written and go and you want to interoperate with the rest of the program so you know there’s this website called
the online encyclopedia of integer sequences it’s a search engine you type in like two three five seven eleven and it tells you those are the primes um and it turns out that the back end for that is all written and go and if you type in a sequence it doesn’t know it actually does some pretty sophisticated math on the numbers all with big numbers and things like that and all of that is written in go to because it was too annoying to shell out to maple and mathematica and sort of do that cross-language thing
even though you’d much rather implement it in those languages so you know you run into those sorts of compromises all the time and that’s fine um someone asked about uh you know go is supposed to be simple so that’s why there’s like no generics and no sets but isn’t also for software developers and don’t software developers need all this stuff and you know it’s silly to reconstruct it and i think that’s it’s true that there’s someone in tension but but simplicity in the sense of leaving
things out was not ever the goal so like for sets you know it just seemed like maps are so close to sets you just have a set a map where the value is empty or a boolean that’s a set and for generics like you have to remember that when we started go in 2007 java was like just finishing a true fiasco of a rollout of generics and so like we were really scared of that we knew that if we just tried to do it um you know we would get it wrong and we knew that we could write a lot of useful programs without generics
and so that was what we did and um and we came back to it when you know we felt like okay we’ve you know spent enough time writing other programs we kind of know a lot more about what we need from from generics for go and and we can take the time to talk to real experts and i think that you know it would have been nice to have them five or ten years ago but we wouldn’t have had the really nice ones that we’re going to have now so i think it was probably the right decision um so there was a question about go
routines and the relation to the plan line thread library which which was all cooperatively scheduled and whether go routines were ever properly scheduled and like if that caused problems and it is absolutely the case that like go and and the go routine runtime were sort of inspired by previous experience on plan nine there was actually a different language called aleph on an early version plan nine that was compiled it had channels it had select it had things we called tasks which were a little bit like our teens but it
didn’t have a garbage collector and that made things really annoying in a lot of cases and also the way that tasks work they were tied to a specific thread so you might have three tasks in one thread and two tasks and another thread and in the three tasks in the first thread the only one ever ran at a time and they could only reschedule during a channel operation and so you would write code where those three tasks were all operating on the same data structure and you just knew because it was in your head when you wrote it
that you know it was okay for these two different tasks to be scribbling over the same data structure because they could never be running at the same time and meanwhile you know in the other thread you’ve got the same situation going on with different data and different tasks and then you come back to the same program like six months later and you totally forget which tasks could write to different pieces of data and i’m sure that we had tons of races i mean it was just it was a nice model for small programs
and it was a terrible model for for programming over a long period of time or having a big program that other people had to work on so so that was never the model for go the model for go was always it’s good to have these lightweight go routines but they’re gonna all be running independently and if they’re going to share anything they need to use locks and they need to use channels to commute to communicate and coordinate explicitly and and that that has definitely scaled a lot better than any of the planned line stuff ever
did um you know sometimes people hear that go routines are cooperatively scheduled and they they think you know something more like that it’s it’s true that early on the go routines were not as preemptively scheduled as you would like so in the very very early days the only preemption points when you called into the run time shortly after that the preemption points were any time you entered a function but if you were in a tight loop for a very long time that would never preempt and that would cause like garbage
collector delays because the garbage collector would need to stop all the go routines and there’d be some guaranteeing stuck in a tight loop and it would take forever to finish the loop um and so actually in the last couple releases we finally started we figured out how to get um unix signals to deliver to threads in just the right way so that and we can have the right bookkeeping to actually be able to use that as a preemption mechanism and and so now things are i think i think the preemption delays for garbage
collection are actually bounded finally but but from the start the model has been that you know they’re running preemptively and and they don’t get control over when they get preempted uh as a sort of follow-on question someone else asked uh you know where they can look to in the source tree to learn more about guru teams and and the go team scheduler and and the answer is that you know this is basically a little operating system like it’s a little operating system that sits on top of the other operating system instead of on
top of cpus um and so the first thing too is like take six eight two eight which is like there i mean i i worked on 6828 and and xv6 like literally like the year or two before i went and did the go run time and so like there’s a huge amount of 688 in the go runtime um and in the actual go runtime directory there’s a file called proc.
go which is you know proc stands for process because like that’s what it is in the operating systems um and i would start there like that’s the file to start with and then sort of pull on strings someone asked about python sort of negative indexing where you can write x of minus one and and that comes up a lot especially from python programmers and and it seems like a really great idea you write these like really nice elegant programs where like you want to get the last element you just say x minus one but the real problem is that like you
have x of i and you have a loop that’s like counting down from from you know n to zero and you have an off by one somewhere and like now x of minus one instead of being you know x of i when i is minus one instead of being an error where you see like immediately say hey there’s a bug i need to find that it just like silently grabs the element off the other end of the array and and that’s where you know the sort of python um you know simplicity you know makes things worse and so that was why we left it out
because it was it was gonna hide bugs too much we thought um you know you could imagine something where you say like x of dollar minus one or len minus one not len of x but just len but you know it seemed like too much of a special case and it really it doesn’t come up enough um someone asked about uh you know what aspect of go was hardest to implement and honestly like a lot of this is not very hard um we’ve done most of this before we’d written operating systems and threading libraries and channel implementations
and so like doing all that again was fairly straightforward the hardest thing was probably the garbage collector go is unique among garbage collected languages in that it gives programmers a lot more control over memory layout so if you want to have a struct with two different other structs inside it that’s just one big chunk of memory it’s not a struct with pointers to two other chunks of memory and because of that and you can take the address of like the second field in the struct and pass that around
and that means the garbage collector has to be able to deal with a pointer that could point into the middle of an allocated object and that’s just something that java and lisp and other things just don’t do um and so that makes the garbage collector a lot more complicated in how it maintains its data structures and we also knew from the start that you really want low latency because if you’re handling network requests uh you can’t you know just pause for 200 milliseconds while and block all of those
in progress requests to do a garbage collection it really needs to be in you know low latency and not stop things and we thought that multicore would be a good a good opportunity there because we could have the garbage collector sort of doing one core and the go program using the other cores and and that might work really well and that actually did turn out to work really well but it required hiring a real expert in garbage collection to uh like figure out how to do it um and make it work but but now it’s it’s really great um i
i have a quick question yeah you said um like if it’s struck like it’s declared inside another stroke it actually is all a big chunk of memory yeah why do why did you implement it like that what’s the reasoning behind that um i well so there’s a couple reasons one is for a garbage collector right it’s a service and the load on the garbage collector is proportional to the number of objects you allocate and so if you have you know a struct with five things in it you can make that one allocation that’s like a fifth of
the the load on the garbage collector and that turns out to be really important but the other thing that’s really important is cache locality right like if you have the processor is pulling in chunks of memory in like you know 64 byte chunks or whatever it is and it’s much better at reading memory that’s all together than reading memory that’s scattered and so um you know we have a git server at google called garrett that is written in java and it was just starting at the time that go was you know just coming out and and
we we just missed like garrett being written and go i think by like a year um but we talked to the the guy who had written garrett and he said that like one of the biggest problems in in garrett was like you have all these shot one hashes and just having the idea of 20 bytes is like impossible to have in java you can’t just have 20 bytes in a struct you have to have a pointer to an object and the object like you know you can’t even have 20 bytes in the object right you have to declare like five different ins or
something like that to get 20 bites and there’s just like no good way to do it and and it’s just the overhead of just a simple thing like that really adds up um and so you know we thought giving programmers control over memory was really important um so another question was was about automatic parallelization like for loops and things like that we don’t do anything like that in the standard go tool chain there are there are go compilers for go front ends for gcc and llvm and so to the extent that those do those
kind of loop optimizations in c i think you know we get the same from the go friends for those but it’s it’s not the kind of parallelization that we typically need at google it’s it’s more um you know lots of servers running different things and and so you know that sort of you know like the sort of big vector math kind of stuff doesn’t come up as much so it just hasn’t been that important to us um and then the last question i have written now is that someone uh asked about like how do you decide when
to acquire release locks and why don’t you have re-entry locks and for that i want to go back a slide let me see yeah here so like you know during the lecture i said things like the lock pro like new protects the map or it protects the data but what we really mean at that point is that we’re saying that the lock protects some collection of invariants that apply to the data or that are true of the data and the reason that we have the lock is to to protect the operations that depend on the invariants and that sometimes temporarily
invalidate the invariants from each other and so when you call lock what you’re saying is i need to make use of the invariance that this lock protects and when you call unlock what you’re saying is i don’t need them anymore and if i temporarily invalid invalidated them i’ve put them back so that the next person who calls lock will see you know correct invariants so in the mux you know we want the invariant that each registered pending channel gets at most one reply and so to do that when we take don out of the map
we also delete it from the map before we unlock it and if there was some separate kind of cancel operation that was directly manipulating the map as well it could lock the it could call lock it could take the thing out call unlock and then you know if it actually found one it would know no one is going to send to that anymore because i took it out whereas if you know we had written this code to have you know an extra unlock and re-lock between the done equals pending of tag and the delete then you wouldn’t have that you know
protection of the invariants anymore because you would have put things back you unlocked and relocked while the invariants were broken and so it’s really important to you know correctness to think about locks as protecting invariants and and so if you have re-entrant locks uh all that goes out the window without the re-entrant lock when you call lock on the next line you know okay the lock just got acquired all the invariants are true if you have a re-entrant lock all you know is well all the invariants were true
for whoever locked this the first time who like might be way up here on my call stack and and you really know nothing um and so that makes it a lot harder to reason about like what can you assume and and so i think reentrant locks are like a really unfortunate part of java’s legacy another big problem with re-engine locks is that if you have code where you know you call something and it is depending on the re-entrant lock for you know something where you’ve acquired the lock up above and and then at some point you say you
know what actually i want to like have a timeout on this or i want to do it uh you know in some other go routine while i wait for something else when you move that code to a different go routine re-entrant always means locked on the same stack that’s like the only plausible thing it could possibly mean and so if you move the code that was doing the re-entrant lock onto a different stack then it’s going to deadlock because it’s going to that lock is now actually going to real lock acquire and it’s going to be
waiting for you to let go of the lock i mean you’re not going to let go of it because you know you think that code needs to finish running so it’s actually like completely fundamentally incompatible with restructurings where you take code and run it in different threads or different guarantees and so so anyway like my advice there is to just you know think about locks as protecting invariants and then you know just avoid depending on reentrant locks it it really just doesn’t scale well to to real programs
so i’ll put this list back up actually you know we have that up long enough i can try to figure out how to stop presenting um and then i can take a few more questions um i had i had a question yeah um and i mean i i think coming from python like it’s very useful right it’s very common to use like like standard functional operations right like map yeah um or filter stuff like that like um like list comprehension and when you know i switched over to go and started programming it’s used i i looked it up and people
say like you shouldn’t do this do this with loop right i was wondering why um well i mean one is that like you can’t do it the other way so you might just look through the way you can do it um but uh you know a bigger a bigger issue is that well there’s that was one answer the other answer is that uh you know if you do it that way you actually end up creating a lot of garbage and if you care about like not putting too much load on the garbage collector that kind of is another way to avoid that you know so if you’ve got
like a map and then a filter and then another map like you can make that one loop over the data instead of three loops over the data each of which generate a new piece of garbage but you know now that we have generics coming um you’ll actually be able to write those functions like you couldn’t actually write what the type signature of those functions were before and so like you literally couldn’t write them and python gets away with this because there’s no no you know static types but now we’re
actually going to have a way to do that and i totally expect that once generics go in there will be a package slices and if you import slices you can do slices.map and slices.filter and like slices.unique or something like that and and i think those will all happen um and you know if if that’s the right thing then that’s great thanks sure um one of the hints that you had it was about running go routines that are independent like concurrently um and some of the examples of the code i i think i couldn’t understand it seemed
to me like you can just like call the function in the same thread rather than a different thread and i was not sure why you would call it in a different thread so um usually it’s because you want them to proceed independently so um so in one of the one of the examples we had like the there was a loop that was sending um you know tasks to the work queue but there was the servers were running in different go routines and reading from the work queue and doing work but then when they were done they would send uh you know hey i’m done now to the
done channel but ascend in go doesn’t complete until the receive actually matches with it and so if the thing that’s sending on the work queue is not going to start receiving from the done channel until it’s done sending to all the work queues or sending all the work into all the tasks into the work queue then now you have a deadlock because the the main thread the main go routine is trying to send new work to the servers the servers are not taking new work they’re trying to tell the main thread
that they’re done but the main thread’s not going to actually start at like reading from the done channel until it finishes giving out all the work and so there’s just they’re just staring at each other waiting for different things to happen whereas if we take that loop that if we just put the little girl routine around the loop that’s sending the work then that can go somewhere else and then it can proceed independently and while it’s stuck waiting for the servers to send to um take more work
the servers are stuck waiting for the main go routine to you know acknowledge that it finished some work and now the main goal team actually gets down to the loop that you know pulls that finishes that actually acknowledges that it finished the work that reads from the done channel and so it’s just a way to separate out you know these are two different things that logically they didn’t have to happen one after the other and because they were happening one after the other that caused a deadlock and by taking one out and
moving it let it run independently um that removes the deadlock thank you so much sure could you talk a little bit about how ghost race detector is implemented sure it is the llvm race detector um and so that probably doesn’t help but but it is exactly the thing that llvm calls thread sanitizer and um and so we actually have a little binary blob that uh you know we link against because we don’t want to depend on all of lvm but it’s the llvm race detector and the way the llvm race sector works is that it allocates a ton of
extra virtual memory and then based on the address of of the thing being read or written it has this other you know spot in virtual memory where it records information about like the last uh thread you know it thinks of threads but their go routines um has with the last thread that did a read or a write and then also every time a synchronizing event happens like you know a communication from one go routine to another uh that counts as establishing a happens before edge between two different go routines and if you ever get something where you
have a read and a write and they’re not properly sequenced right like so if you have a read and then it happens before something in another chain which then you know later does the right that’s fine but if you have a read and a write and there’s no happens before sequence that connects them then um then that’s a race and it actually you know has some pretty clever ways to you know dynamically figure out quickly you know did this read happen is there a happens before a path between this readings
right as they happen and it slows down the program by like maybe 10x but you know if you just divert a small amount of traffic there that’s probably fine if it’s for testing that’s also probably fine and it’s way better than like not finding out about the races so it’s totally worth it and honestly 10 or 20 x is is fantastic the original thread sanitizer was more like 100 or a thousand x and that was not good enough well what’s the rate detector called lrvm uh it’s called thread sanitizer but
it’s part of llvm which is um the clang c compiler the the one that um almost everyone uses now is is part of the llvm project can you talk about slices um and like the design choices having them as views on a raise which like confused me at first yeah yeah it is a little confusing at first um the the main thing is that you want it to be efficient to kind of walk through an array or to like you know if you’re in quicksort or merge sword or something where you have an array of things and now you want to say well now sort
this half and sort the other half you want to be able to efficiently say like here this is half of the previous one like you know sort that and so in c the way you do that is you just pass in you know the pointer to the first element and the number of elements and that’s basically all a slice is and then the other pattern that comes up a lot when you’re you know trying to be efficient with arrays is you have to grow them and and so you don’t want to recall realic on every single new element you want to amortize that
and so the way you do that in in c again is that you have a base pointer you have the length that you’re using right now and you have the length that you allocated and then to you know add one you you check and see if the length is is bigger than the amount you allocated if so you reallocate it and otherwise you just keep bumping it forward and and slices are really just an encoding of those idioms because those are kind of the most efficient way to manage the memory and so in in any kind of like c plus vector or
um sort of thing like that that’s what’s going on underneath but it makes it a lot harder to um like the c plus vector because of ownership reasons you know the vector is tied to the actual underlying memory it’s a lot harder to get like a sub vector that’s just the view onto like the second half for merge sort so that’s sort of the idea is that it just like there are all these patterns for accessing memory efficiently that came from c and we tried to make them fit and to go in an idiomatic way
in a safe way can you talk about how you decided to um implement the go like remote module system where you import directly from a url versus like yeah um i mean i just didn’t want to run a service and like like you know a lot of the things like ruby gems and those like were not as as for the front of my mind at the time just because they were newer but like i had used pearl for a while and like cpan and and i just thought it was it was insane that like everyone was fighting over these short names like db you know
there probably shouldn’t be an argument over like who gets to make the db package um and so putting domain names in the front seemed like a good way to decentralize it and and it was also a good way for us not to run any server because you know we could just say well you know we’ll recognize the host name and then and then go grab it from source control um from someone else’s server and that turned out to be a really great idea i think um because we just we don’t have that kind of same infrastructure
that other things depend on like in the java world it’s actually really problematic there are multiple there’s no sort of standard registry but they all use these short names and so uh like maven can be configured to build from multiple different registries and you if you’re an open source software package provider you actually have to go around and be sure that you upload it to all the different registries because if you don’t if you miss one and it becomes popular someone else will upload different code to that one
and um and then like maven actually just takes whichever one comes back first it just like sends a request to all of them and whatever comes back first so like you know if someone wants to make a malicious copy of your package all you do is find some registry other people use that you forgot to upload it to and like you know they get to win the race sometimes so it’s like it’s a real problem like i think having domain name there really helps split up the ownership in a really important way thank you sure
so the maybe we should take a quick uh pause here those people that have to go can go i’m sure russ is willing to uh stick around for a little bit longer yeah and answer any questions uh but i do want to thank ross for giving this lecture uh you know hopefully this will help you running more good go programs these patterns and uh so thank you russ very welcome it’s nice to be here and then more questions feel free to ask questions yeah oh just a little logistical thing uh the slides that are on the 6824 website are
not they exactly the same as russ’s slides people check them out i’ll get franz a new pdf yeah more general question about when is writing a new language the like the best solution to a problem that’s a great question um it’s almost never the best solution but you know at the time we had just an enormous number of programmers like thousands of programmers working in one code base and the compilations were just taking forever because um seatbelts plus was just not not meant for you know efficient incremental
compilation and and so it and furthermore at the time like threading libraries were really awful like people just didn’t use threats i remember like one of the first days i was at mit and talking to robert and robert said to me um like in 2001 he said to me like well we don’t use threads here because threads are slow and and that was like totally normal like that was just the way the world at the time um and and at google we were having a lot of trouble because it was all event-based like little callbacks in c plus plus
and there were these multi-core machines and we actually didn’t know how to get things to work on them because like linux threads were not something you could really rely on to work and and so we ended up like if you had a four core machine you just run four different process in completely independent processes of the web server and just treat it as like four machines um and that was clearly like not very efficient so like there were a lot of good reasons to like try something um but you know it’s a huge amount of
work to get to the point where go is today and i think that um so much is not the language right like there were important things that we made did in the language that enabled other um considerations but uh so much of the successful languages the ecosystem that got built up around it and the tooling that we built and the go command and like all these like not the language things so you know programming language uh people who are like focus on the language itself i think sometimes get distracted by all the stuff around like they miss all the
stuff around it um can i ask a follow-up on that yeah i was wondering how is working on go different now since it’s more mature than it was before oh that’s a great question um you know in the early days it was so easy to make changes and now it’s really hard to make changes i think that’s the number one thing um you know in the early days like everything was in one source code repository literally all the go code in the world was the one source code repository and so like there were days where we changed the syntax like you
used to have a star before chan every time you set a channel because it was then it was a pointer underneath and it was all kind of exposed so you’d always say star channel instead of jan and and and similarly for maps and at some point we realized like this is dumb like you have to say the star let’s just take it out and um and so like we made the change to the compiler and i opened up literally like the couple hundred go source files in the world in my editor and like the entire team stood behind me and like
i typed some regular expressions and we looked at the effect on the files yep that looks right save it you know compile it we’re done and like today you know we can’t make backwards compatible changes at all um and and even making you know new changes like it it affects a lot of people and so uh you know you sort of propose something and you know people point out well this won’t work for me and you try to like adjust that maybe um it’s just it’s a lot harder we estimate there’s at least a million
maybe two million go programmers in the world and it’s very different from when they were you know four or five not sure if this is a valid question but what what language is go written in is it written in go also or no now it is now it is the original um compiler runtime were written in c but a few years ago we went through a big um we actually wrote a a program to translate c to go and that only worked for rc code but still it was good enough so that we wouldn’t lose kind of all the sort of encoded knowledge in that code
about why things were the way they were and like how things work so we have to start from scratch but now it’s all written and go and you know a little bit of assembly and that means that um people can uh you know people who know go can help on the the go project whereas before like if you wanted to work on the compiler or the runtime you had to know c really well and like we weren’t getting a lot of people knew c really well like there’s not actually that many of them proportionately and and furthermore like our entire user
base is go programmers not c programmers so moving to go was was a really big deal i was wondering how did you prioritize what features to add to the language at like this point like in all generics like a lot of people were like asking for that like did y’all know like how you choose what to work on i mean we’ve considered language mostly frozen for a while and um and so we haven’t been adding much uh there was a long period where we said we weren’t adding anything and then we added a little bit of things
in the last couple years to lead up to generics just kind of shake the rust off on like all the like what breaks when you change something in the language so like you can put underscores between digits and long numbers now things like that um but you know generics has clearly been the next thing that needed to happen and we just had to figure out how in general we try to only add things that don’t have weird kind of interference with other features and we try to add things that are you know really important that will help a
lot of people for the kinds of programs that we’re trying to target with go which is like distributed systems and that sort of thing cool thank you oh i had a question actually yeah uh so um for i noticed that like you know uh go doesn’t have like basic functions like min or max for like yeah so is that like something that you’re considering like say adding with like the generic stuff maybe is that why you didn’t decide yeah exactly right because like you can’t have a min you’d have been event and you could have
minivan date but those had to have different names and that was kind of annoying um so now we can write just a generic name over any type that has a less than operator yeah that’ll be good and you know honestly like for the specific case of min and max so i know it’s not that hard to code i know i was gonna say i’m starting to feel like we should just make some built-ins like like you know print and things like that so that you know you can just always have them but even if we don’t like you it’ll be
math.min and that’ll be there at least um yeah we really didn’t want to make them built-ins until we could like express their types and we couldn’t do that until generics happened because there is actually a min for like floating points actually yeah i know it’s kind of weird because it’s because the math library is basically copied from the c math.
h set of things yes so that’s a good point like we can’t actually put them in math because they’re already there okay but no yeah but we’ll figure it out like i think we should probably just put them in the language but we have to get generis through first and another thing actually i noticed that you did usako like competitive programming yeah i did too actually oh cool yeah so how did you so actually i included this in one of the questions that i submitted let me pull it up um so my question was like
um how did how was like how did you go from doing competitive programming to like doing what you you’re doing now at google working on going how’s the transition between like competitive programming to systems also finally what made you decide to go into systems and how did it relate to programming i mean competitive programming at the time that i did it was not as all-consuming as i gather it is now like like you know you could just like be able to implement a simple dynamic programming like little two for loops and that was
fine and now you have all these like complex hall algorithms and all that stuff that i can’t do so like you know at some point like at some level like it was different um but you know i was actually more interested in the sort of systems you kind of stopped from the start and and the the program contests were just like something fun to do on the side so there wasn’t like a huge transition there um i was never into like implementing complex algorithms and and that you know max flow and all those sorts of things
on the other hand like when you start a new language you actually do get to write a lot of core things right um like someone has to write the sort function and it has to be a good general sort function and like i spent a while last month like looking into dip algorithms and and that’s like you know sort of matches that background pretty well so like it does come up um but you know it’s just it’s just a different kind of programming oh so you thought of it as more of a side thing back then no like yeah
it wasn’t it was definitely not the sort of main thing i did when i was writing programs yeah because like today it’s effectively like the main thing i know i know it’s you know if you don’t do it full-time like there’s just no way you can you know there just weren’t that many people who cared it you know in uh 1995 yeah 20 years later um can you ask a related question to that so how did you decide to go from i’m from like academic work into i mean your work is still like a little bit more different than
like the usual like software engineering thing but still yeah um you know i got lucky uh i i grew up near bell labs in new jersey and so like that was how i ended up working on playing the iron a little bit in high school and college um and so you know i sort of knew i was going to go to grad school and you know the plan was to go back to bell labs but it kind of imploded while i was in grad school with the dot com boom and the dot com crash and um and so like you know google was was sort of a just vacuuming up phds systems phds at
the time and and and doing really interesting things i mean you probably you know there’s a i don’t know i haven’t looked at syllabus for this year but you know there’s things like spanner and um big table and chubby and and things like that and you know they they had a whole host of good distributed systems kind of stuff going on and so you know it was sort of lucky to be able to to go to that too um and you know at the time i graduated i was also looking at you know industrial research labs like microsoft
research and and places like that so you know there’s definitely an opportunity there for you know researchy things but not in academia if that’s what you want um it’s a little harder to find now i mean most of the places i know like microsoft research imploded too a couple years later but um you know it’s uh it’s still an option and and you know it’s just a slightly different path um you end up the the differences i see from academia is like you end up caring a ton more about actually making things work
100 time and supporting them for like a decade or more whereas like you finish your paper and you kind of like get to put it off to the side and that’s that’s really nice actually at some level um it’s uh it’s definitely strange to me to be you know editing source files that i wrote you know in in some cases actually 20 years ago um because i used a bunch of code that i’d already written when we started go and it’s very weird to think that like i’ve been keeping this program running
for 20 years thinking
Concurrency and Parallelism
Concurrency: How you write your programs about being able to compose independently executing control flows whether you want to call them processes or threads or go routines.
Parallelism: How the programs get executed about allowing multiple computations to run simultaneously so that the program can be doing lots of things at once not just dealing with lots of things at once and so concurrency lends itself naturally to parallel execution
并发性:如何编写程序以支持独立执行的控制流的组合,无论你想称它们为进程、线程还是 Go 协程。
并行性:程序如何被执行,允许多个计算同时运行,使得程序可以同时处理许多事情,而不仅仅是同时应对许多事情。因此,并发性自然适合并行执行。
Goroutines for State
Hint: Convert data state into code state when it makes programs clearer.
Lab1: MapReduce
论文
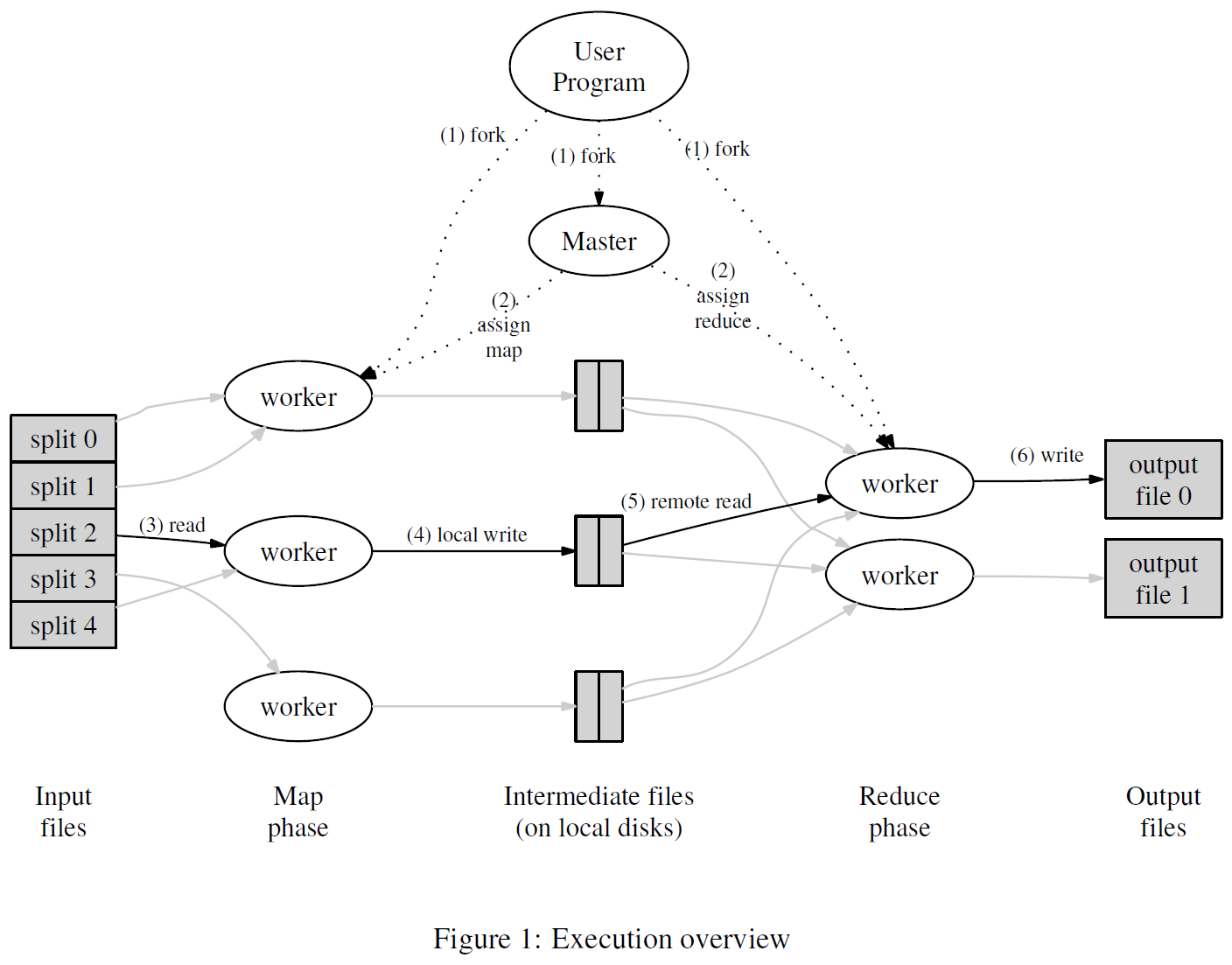 MapReduce框架图
MapReduce框架图
 MapReduce论文结构
MapReduce论文结构
MapReduce 结构
- Map and Reduce Function(由用户定义)
- Worker(我们实现)
- Coordinator(源论文中的 master,我们实现)
单机顺序式实现
MapReduce 实现: src/main/mrsequential.go。
Map and Reduce Function:mrapps/wc.go 这里是一个 word-count app,mrapps/indexer.go 是
运行方法:
1 | |
分布式实现
需要我们实现:
- mr/coordinator.go,
- mr/worker.go
- mr/rpc.go
运行方式
1 | |
1 | |
1 | |
1 | |
测试方案:
1 | |
1 | |
一些要求
- 在map阶段,应将中间键值根据nReduce个reduce任务的数量划分为多个桶,这里的nReduce即main/mrcoordinator.go传递给MakeCoordinator()方法的参数。每个mapper应当为reduce任务创建nReduce个中间文件以供消费。
- worker的实现应该把第X个reduce任务的输出放置于mr-out-X文件中。每个mr-out-X文件应当包含每行一个reduce函数的输出结果。这一行需要使用Go语言的”%v %v”格式化字符串生成,调用时传入键和值。你可以在main/mrsequential.go中找到被注释为”这是正确的格式”的代码行作为参考。如果你的实现与此格式相差太多,测试脚本将会失败。
- 你可以修改mr/worker.go、mr/coordinator.go以及mr/rpc.go文件。为了测试目的,你可以暂时修改其他文件,但请确保你的代码能与原始版本兼容——我们将使用原始版本进行测试。
- worker应将中间Map阶段的输出保存为当前目录下的文件,以便后续作为Reduce任务的输入读取这些文件。
- main/mrcoordinator.go期望mr/coordinator.go实现一个Done()方法,在MapReduce作业完全完成时返回true;此时,mrcoordinator.go将会退出。
- 当整个作业完全完成后,worker进程也应当退出。一种简单的实现方式是利用call()的返回值:如果worker无法联系上coordinator,则可以认为coordinator因为作业已完成而退出,因此worker也可以终止。根据你的设计,你也可能会发现设置一个“请退出”的伪任务是有帮助的,coordinator可以通过这个伪任务通知workers退出。
一些帮助
- 开始的一个方法是修改mr/worker.go中的Worker()函数,让它发送一个RPC请求给coordinator以请求任务。然后修改coordinator,使其响应返回一个尚未开始的map任务的文件名。接着,修改worker读取该文件并调用应用程序的Map函数,就像在mrsequential.go中所做的那样。
- 应用程序的Map和Reduce函数是在运行时使用Go语言的插件包从文件加载的,这些文件名以.so结尾。
- 如果你更改了mr/目录下的任何内容,你可能需要重新构建所使用的MapReduce插件,例如通过go build -buildmode=plugin ../mrapps/wc.go命令。
- 本实验依赖于workers共享一个文件系统。当所有workers在同一台机器上运行时这很简单,但如果workers运行在不同的机器上,则需要像GFS这样的全局文件系统。
- 对于中间文件采用合理的命名规则,比如mr-X-Y,其中X是Map任务编号,Y是reduce任务编号。
- worker的map任务代码需要一种方式将中间键值对存储到文件中,并且可以在reduce任务期间正确地读回。一种可能是使用Go语言的encoding/json包。要以JSON格式写入键值对至打开的文件,可以这样做:
1 | |
而读回此类文件的方式如下:
1 | |
- 你的worker的map部分可以使用worker.go中的ihash(key)函数为给定的键选择reduce任务。
- 你可以从mrsequential.go中借用一些代码用于读取Map输入文件、在Map和Reduce之间排序中间键值对以及将Reduce输出存储到文件中。
- 作为RPC服务器的coordinator将是并发执行的;不要忘记锁定共享数据。
- 使用Go语言的race detector工具,可以通过go run -race启动。test-mr.sh脚本开头有一个注释,告诉你如何与-race选项一起运行它。在我们评分时不会使用race detector,然而,如果你的代码存在竞态条件,在测试时即使不使用race detector也很可能会失败。
- workers有时需要等待,例如reduces不能在最后一个map完成之前开始。一种可能性是让workers定期向coordinator询问工作,使用time.Sleep()在每次请求之间进行休眠。另一种可能性是在coordinator的相关RPC处理器中实现一个循环等待,可以通过time.Sleep()或sync.Cond来实现。由于Go语言为每个RPC在其自己的线程中运行处理程序,因此一个处理程序的等待不应妨碍coordinator处理其他RPCs。
- coordinator无法可靠地区分崩溃的workers、因某种原因暂停但仍存活的workers以及执行速度过慢以至于无用的workers。最好的做法是让coordinator等待一段时间(如10秒),然后放弃并重新分配任务给另一个worker。对于这个实验,设定coordinator等待十秒钟;之后应假设worker已经死亡(当然,实际上它可能并未死亡)。
- 如果你选择实现备份任务(第3.6节),请注意我们测试了在workers执行任务但未崩溃的情况下你的代码不会调度额外的任务。备份任务应该只在一段相对较长的时间后(例如10秒)被调度。
- 为了测试崩溃恢复,你可以使用mrapps/crash.go应用插件,它会在Map和Reduce函数中随机退出。
- 为了确保在发生崩溃时没有人观察到部分写入的文件,MapReduce论文提到了使用临时文件并在完全写入后原子重命名的技巧。你可以使用ioutil.TempFile(或者如果你运行的是Go 1.17或更新版本,则使用os.CreateTemp)创建一个临时文件,并使用os.Rename原子地重命名它。
- test-mr.sh在一个名为mr-tmp的子目录下运行所有进程,所以如果出现问题并且你想查看中间文件或输出文件,请在那里查找。你可以暂时修改test-mr.sh以便在失败的测试后退出,这样脚本就不会继续测试(并覆盖输出文件)。
- test-mr-many.sh连续多次运行test-mr.sh,你可能想要这样做以便发现低概率的bug。它接受一个参数,即运行测试的次数。你不应该并行运行多个test-mr.sh实例,因为coordinator会重用相同的套接字,从而导致冲突。
- Go RPC仅发送字段名称以大写字母开头的结构体。子结构也必须具有首字母大写的字段名称。
- 在调用RPC call()函数时,回复结构应当包含所有的默认值。RPC调用看起来应该是这样的:
1 | |
- 在调用之前不应该设置reply的任何字段。如果你传递的reply结构体包含非默认字段,RPC系统可能会静默地返回错误值。
第一个版本
- 完成了 rpc + 单个 worker
目前的问题:
- 测试多 worker 是否正常
- 测试的时候是把多个 redece 的结果拼起来和最终答案进行比较,所以每个 reduce 的内容得是完整的结果的一部分,而不是每个 reduce 中都是所有出现过的单词。
第二个版本
map 可以根据文件进行分区,可是中间结果如何进行分区呢?假设有 2 个 reduce。
现在有 10 个文件,分别 map 之后产生了 mr-1 mr-2 … mr-10。
则对每个 map 进行进一步划分,根据 key 划分为 mr-1-1 mr-1-2。
map 的时候不用 sort 和组合,这些都可以交给 reduce 来完成。
- 增加数据分区
- 增加锁
第三个版本
wc test 可以测试通过,然而 indexer 不能,总会出现不一致的情况:
1 | |
考虑原因可能是 map 还在进行中,或者在写文件时,已经触发了 reduce 任务,需要给 map 任务添加一个完成信息。
可以等 map 结束之后给 master 传递信息使得该任务变成完成状态,并允许 reduce。
增加了写中间文件原子操作之后,indexer 可以正常工作了。
并不能,只是出错概率减小了
- 写文件原子操作
mr-[0-9]*-%d避免解析 mr-out-* 文件
实现方法:先写到 tmp 文件,然后重命名成文件就好,重命名是原子操作。
第四个版本
增加了
- 容错逻辑(分发任务之后开始计时,如果时间到了还是 wait,那么就 resume 为 map/reduce)
- 把 list 换成了 map
- 修改写文件原子操作,先写到 temp 文件,注意 temp 文件一定不能重名。还要注意在同一个文件系统上,这样 rename 才是原子操作。
- 存在一个问题,当 reduce crash 时,重新开了一个在运行,之前 crash 的那个恢复之后又调用了一次 finish,同一个 finish 了 2 次,就出错了。所以要注意 crash 掉的不要 finish。在接受到 finish 请求的时候判断是不是 Wait,如果是则再 Done,并完成数量加一。
完成所有的测试!芜湖!
1 | |
GFS
特点:单 master、弱一致性
Master 管理文件、存储文件的 Chunk ID 信息。
GFS 一致性
master
第一个是文件名到Chunk ID或者Chunk Handle数组的对应。这个表单告诉你,文件对应了哪些Chunk。但是只有Chunk ID是做不了太多事情的,所以有了第二个表单。
第二个表单记录了Chunk ID到Chunk数据的对应关系。这里的数据又包括了:
每个Chunk存储在哪些服务器上,所以这部分是Chunk服务器的列表
每个Chunk当前的版本号,所以Master节点必须记住每个Chunk对应的版本号。
所有对于Chunk的写操作都必须在主Chunk(Primary Chunk)上顺序处理,主Chunk是Chunk的多个副本之一。所以,Master节点必须记住哪个Chunk服务器持有主Chunk。
并且,主Chunk只能在特定的租约时间内担任主Chunk,所以,Master节点要记住主Chunk的租约过期时间。
Master会在磁盘上存储log,每次有数据变更时,Master会在磁盘的log中追加一条记录,并生成CheckPoint(类似于备份点)。
Chunk Handle的数组(第一个表单)要保存在磁盘上。给它标记成NV(non-volatile, 非易失),这个标记表示对应的数据会写入到磁盘上。
Chunk服务器列表不用保存到磁盘上。因为Master节点重启之后可以与所有的Chunk服务器通信,并查询每个Chunk服务器存储了哪些Chunk,所以我认为它不用写入磁盘。所以这里标记成V(volatile),
- 版本号要不要写入磁盘取决于GFS是如何工作的,我认为它需要写入磁盘。我们之后在讨论系统是如何工作的时候再详细讨论这个问题。这里先标记成NV。
- 主Chunk的ID,几乎可以确定不用写入磁盘,因为Master节点重启之后会忘记谁是主Chunk,它只需要等待60秒租约到期,那么它知道对于这个Chunk来说没有主Chunk,这个时候,Master节点可以安全指定一个新的主Chunk。所以这里标记成V。
- 类似的,租约过期时间也不用写入磁盘,所以这里标记成V。
任何时候,如果文件扩展到达了一个新的64MB,需要新增一个Chunk或者由于指定了新的主Chunk而导致版本号更新了,Master节点需要向磁盘中的Log追加一条记录说,我刚刚向这个文件添加了一个新的Chunk或者我刚刚修改了Chunk的版本号。所以每次有这样的更新,都需要写磁盘。GFS论文并没有讨论这么多细节,但是因为写磁盘的速度是有限的,写磁盘会导致Master节点的更新速度也是有限的,所以要尽可能少的写入数据到磁盘。
这里在磁盘中维护log而不是数据库的原因是,数据库本质上来说是某种B树(b-tree)或者hash table,相比之下,追加log会非常的高效,因为你可以将最近的多个log记录一次性的写入磁盘。因为这些数据都是向同一个地址追加,这样只需要等待磁盘的磁碟旋转一次。而对于B树来说,每一份数据都需要在磁盘中随机找个位置写入。所以使用Log可以使得磁盘写入更快一些。
当Master节点故障重启,并重建它的状态,你不会想要从log的最开始重建状态,因为log的最开始可能是几年之前,所以Master节点会在磁盘中创建一些checkpoint点,这可能要花费几秒甚至一分钟。这样Master节点重启时,会从log中的最近一个checkpoint开始恢复,再逐条执行从Checkpoint开始的log,最后恢复自己的状态。
client 读文件
Raft
1. 脑裂(Split Brain)
- 脑裂(Split Brain)是指在分布式系统中,由于网络分区(Network Partition)或其他故障导致系统中的不同节点无法正常通信,进而使得系统被分割成两个或多个独立的部分,每个部分都认为自己是系统的主节点(Primary),并独立地进行操作和决策。这种情况下,系统会出现数据不一致性和决策冲突,导致系统行为异常。
1. 脑裂的场景
在分布式系统中,通常会有多副本(Replicas)来提高系统的容错能力。例如,VMware FT(Fault Tolerance)系统中,有一个主虚拟机(Primary VM)和一个备份虚拟机(Backup VM),它们通过一个 Test-and-Set 服务来决定谁是主节点。如果 Test-and-Set 服务本身是单点的,那么它可以通过仲裁来避免脑裂。但如果 Test-and-Set 服务本身也有多副本(例如 S1 和 S2),就可能出现脑裂。
2. 脑裂的发生
假设系统中有两个服务器(S1 和 S2)和两个客户端(C1 和 C2)。客户端需要通过 Test-and-Set 服务来确定主节点。正常情况下,客户端会同时与两个服务器通信,确保数据一致性。但如果网络出现故障,客户端可能只能与其中一个服务器通信:
- C1 可以访问 S1,但无法访问 S2。
C2 可以访问 S2,但无法访问 S1。
在这种情况下:
C1 会认为 S1 是主节点,并开始执行操作。
C2 会认为 S2 是主节点,并开始执行操作。
此时,系统被分割成两个独立的部分,每个部分都认为自己是主节点,这就是脑裂。
3. 脑裂的后果
脑裂会导致以下严重问题:
- 数据不一致性:S1 和 S2 的数据可能会出现冲突,因为它们各自独立地处理请求。
- 决策冲突:两个主节点可能会同时对同一资源进行操作,导致系统行为不可预测。
- 系统不可用:为了避免数据不一致,系统可能需要停止服务,直到问题解决。
4. 避免脑裂的方法
为了避免脑裂,分布式系统通常会采用以下方法:
- 单点仲裁:使用一个单点(如 Test-and-Set 服务)来决定主节点。虽然单点本身是单点故障,但它可以避免脑裂。
- 网络分区检测:通过检测网络分区,确保系统在分区发生时能够快速做出决策,避免两个部分各自为政。
- 人工干预:在某些情况下,系统会停止自动操作,转而由人工干预来解决冲突。
5. 总结
脑裂是分布式系统中的一种严重故障场景,它会导致系统分裂成多个独立的部分,每个部分都认为自己是主节点,从而引发数据不一致性和决策冲突。为了避免脑裂,系统通常需要依赖单点仲裁、网络分区检测或人工干预等方法。
2. 过半票决(Majority Vote)
尽管存在脑裂的可能,但是随着技术的发展,人们发现哪怕网络可能出现故障,可能出现分区,实际上是可以正确的实现能够自动完成故障切换的系统。当网络出现故障,将网络分割成两半,网络的两边独自运行,且不能访问对方,这通常被称为网络分区。
在构建能自动恢复,同时又避免脑裂的多副本系统时,人们发现,关键点在于过半票决(Majority Vote)。这是Raft论文中出现的,用来构建Raft的一个基本概念。过半票决系统的第一步在于,服务器的数量要是奇数,而不是偶数。例如在上图中(只有两个服务器),中间出现故障,那两边就太过对称了。这里被网络故障分隔的两边,它们看起来完全是一样的,它们运行了同样的软件,所以它们也会做相同的事情,这样不太好(会导致脑裂)。
但是,如果服务器的数量是奇数的,那么当出现一个网络分割时,两个网络分区将不再对称。假设出现了一个网络分割,那么一个分区会有两个服务器,另一个分区只会有一个服务器,这样就不再是对称的了。这是过半票决吸引人的地方。所以,首先你要有奇数个服务器。然后为了完成任何操作,例如Raft的Leader选举,例如提交一个Log条目,在任何时候为了完成任何操作,你必须凑够过半的服务器来批准相应的操作。这里的过半是指超过服务器总数的一半。直观来看,如果有3个服务器,那么需要2个服务器批准才能完成任何的操作。
这里背后的逻辑是,如果网络存在分区,那么必然不可能有超过一个分区拥有过半数量的服务器。例如,假设总共有三个服务器,如果一个网络分区有一个服务器,那么它不是一个过半的分区。如果一个网络分区有两个服务器,那么另一个分区必然只有一个服务器。因此另一个分区必然不能凑齐过半的服务器,也必然不能完成任何操作。
这里有一点需要明确,当我们在说过半的时候,我们是在说所有服务器数量的一半,而不是当前开机服务器数量的一半。这个点困扰了我(Robert教授)很长时间。如果你有一个系统有3个服务器,其中某些已经故障了,如果你要凑齐过半的服务器,你总是需要从3个服务器中凑出2个,即便你知道1个服务器已经因为故障关机了。过半总是相对于服务器的总数来说。
对于过半票决,可以用一个更通用的方程式来描述。在一个过半票决的系统中,如果有3台服务器,那么需要至少2台服务器来完成任意的操作。换个角度来看,这个系统可以接受1个服务器的故障,任意2个服务器都足以完成操作。如果你需要构建一个更加可靠的系统,那么你可以为系统加入更多的服务器。所以,更通用的方程是:
如果系统有 2 * F + 1 个服务器,那么系统最多可以接受F个服务器出现故障,仍然可以正常工作。
通常这也被称为多数投票(quorum)系统,因为3个服务器中的2个,就可以完成多数投票。
前面已经提过,有关过半票决系统的一个特性就是,最多只有一个网络分区会有过半的服务器,所以我们不可能有两个分区可以同时完成操作。这里背后更微妙的点在于,如果你总是需要过半的服务器才能完成任何操作,同时你有一系列的操作需要完成,其中的每一个操作都需要过半的服务器来批准,例如选举Raft的Leader,那么每一个操作对应的过半服务器,必然至少包含一个服务器存在于上一个操作的过半服务器中。也就是说,任意两组过半服务器,至少有一个服务器是重叠的。实际上,相比其他特性,Raft更依赖这个特性来避免脑裂。例如,当一个Raft Leader竞选成功,那么这个Leader必然凑够了过半服务器的选票,而这组过半服务器中,必然与旧Leader的过半服务器有重叠。所以,新的Leader必然知道旧Leader使用的任期号(term number),因为新Leader的过半服务器必然与旧Leader的过半服务器有重叠,而旧Leader的过半服务器中的每一个必然都知道旧Leader的任期号。类似的,任何旧Leader提交的操作,必然存在于过半的Raft服务器中,而任何新Leader的过半服务器中,必然有至少一个服务器包含了旧Leader的所有操作。这是Raft能正确运行的一个重要因素。
学生提问:可以为Raft添加服务器吗?
Rober教授:Raft的服务器是可以添加或者修改的,Raft的论文有介绍,可能在Section 6。如果是一个长期运行的系统,例如运行5年或者10年,你可能需要定期更换或者升级一些服务器,因为某些服务器可能会出现永久的故障,又或者你可能需要将服务器搬到另一个机房去。所以,肯定需要支持修改Raft服务器的集合。虽然这不是每天都发生,但是这是一个长期运行系统的重要维护工作。Raft的作者提出了方法来处理这种场景,但是比较复杂。
所以,在过半票决这种思想的支持下,大概1990年的时候,有两个系统基本同时被提出。这两个系统指出,你可以使用这种过半票决系统,从某种程度上来解决之前明显不可能避免的脑裂问题,例如,通过使用3个服务器而不是2个,同时使用过半票决策略。两个系统中的一个叫做Paxos,Raft论文对这个系统做了很多的讨论;另一个叫做ViewStamped Replication(VSR)。尽管Paxos的知名度高得多,Raft从设计上来说,与VSR更接近。VSR是由MIT发明的。这两个系统有着数十年的历史,但是他们仅仅是在15年前,也就是他们发明的15年之后,才开始走到最前线,被大量的大规模分布式系统所使用。
3. Raft 初探
Raft会以库(Library)的形式存在于服务中。如果你有一个基于Raft的多副本服务,那么每个服务的副本将会由两部分组成:应用程序代码和Raft库。应用程序代码接收RPC或者其他客户端请求;不同节点的Raft库之间相互合作,来维护多副本之间的操作同步。
从软件的角度来看一个Raft节点,我们可以认为在该节点的上层,是应用程序代码。例如对于Lab 3来说,这部分应用程序代码就是一个Key-Value数据库。应用程序通常都有状态,Raft层会帮助应用程序将其状态拷贝到其他副本节点。对于一个Key-Value数据库而言,对应的状态就是Key-Value Table。应用程序往下,就是Raft层。所以,Key-Value数据库需要对Raft层进行函数调用,来传递自己的状态和Raft反馈的信息。
同时,如Raft论文中的图2所示,Raft本身也会保持状态。对我们而言,Raft的状态中,最重要的就是Raft会记录操作的日志。
 image-20250131224240484
image-20250131224240484
对于一个拥有三个副本的系统来说,很明显我们会有三个服务器,这三个服务器有完全一样的结构(上面是应用程序层,下面是Raft层)。理想情况下,也会有完全相同的数据分别存在于两层(应用程序层和Raft层)中。除此之外,还有一些客户端,假设我们有了客户端1(C1),客户端2(C2)等等。
 image-20250131224341803
image-20250131224341803
客户端就是一些外部程序代码,它们想要使用服务,同时它们不知道,也没有必要知道,它们正在与一个多副本服务交互。从客户端的角度来看,这个服务与一个单点服务没有区别。
客户端会将请求发送给当前Raft集群中的Leader节点对应的应用程序。这里的请求就是应用程序级别的请求,例如一个访问Key-Value数据库的请求。这些请求可能是Put也可能是Get。Put请求带了一个Key和一个Value,将会更新Key-Value数据库中,Key对应的Value;而Get向当前服务请求某个Key对应的Value。
所以,看起来似乎没有Raft什么事,看起来就像是普通的客户端服务端交互。一旦一个Put请求从客户端发送到了服务端,对于一个单节点的服务来说,应用程序会直接执行这个请求,更新Key-Value表,之后返回对于这个Put请求的响应。但是对于一个基于Raft的多副本服务,就要复杂一些。
假设客户端将请求发送给Raft的Leader节点,在服务端程序的内部,应用程序只会将来自客户端的请求对应的操作向下发送到Raft层,并且告知Raft层,请把这个操作提交到多副本的日志(Log)中,并在完成时通知我。
之后,Raft节点之间相互交互,直到过半的Raft节点将这个新的操作加入到它们的日志中,也就是说这个操作被过半的Raft节点复制了。
当且仅当Raft的Leader节点知道了所有(课程里说的是所有,但是这里应该是过半节点)的副本都有了这个操作的拷贝之后。Raft的Leader节点中的Raft层,会向上发送一个通知到应用程序,也就是Key-Value数据库,来说明:刚刚你提交给我的操作,我已经提交给所有(注:同上一个说明)副本,并且已经成功拷贝给它们了,现在,你可以真正的执行这个操作了。
所以,客户端发送请求给Key-Value数据库,这个请求不会立即被执行,因为这个请求还没有被拷贝。当且仅当这个请求存在于过半的副本节点中时,Raft才会通知Leader节点,只有在这个时候,Leader才会实际的执行这个请求。对于Put请求来说,就是更新Value,对于Get请求来说,就是读取Value。最终,请求返回给客户端,这就是一个普通请求的处理过程。
学生提问:问题听不清。。。这里应该是学生在纠正前面对于所有节点和过半节点的混淆
Robert教授:这里只需要拷贝到过半服务器即可。为什么不需要拷贝到所有的节点?因为我们想构建一个容错系统,所以即使某些服务器故障了,我们依然期望服务能够继续工作。所以只要过半服务器有了相应的拷贝,那么请求就可以提交。
学生提问:除了Leader节点,其他节点的应用程序层会有什么样的动作?
Robert教授:哦对,抱歉。当一个操作最终在Leader节点被提交之后,每个副本节点的Raft层会将相同的操作提交到本地的应用程序层。在本地的应用程序层,会将这个操作更新到自己的状态。所以,理想情况是,所有的副本都将看到相同的操作序列,这些操作序列以相同的顺序出现在Raft到应用程序的upcall中,之后它们以相同的顺序被本地应用程序应用到本地的状态中。假设操作是确定的(比如一个随机数生成操作就不是确定的),所有副本节点的状态,最终将会是完全一样的。我们图中的Key-Value数据库,就是Raft论文中说的状态(也就是Key-Value数据库的多个副本最终会保持一致)。
4. Log 同步时序
接下来我将画一个时序图来描述Raft内部的消息是如何工作的。假设我们有一个客户端,服务器1是当前Raft集群的Leader。同时,我们还有服务器2,服务器3。这张图的纵坐标是时间,越往下时间越长。假设客户端将请求发送给服务器1,这里的客户端请求就是一个简单的请求,例如一个Put请求。
 image-20250131225756591
image-20250131225756591
之后,服务器1的Raft层会发送一个添加日志(AppendEntries)的RPC到其他两个副本(S2,S3)。现在服务器1会一直等待其他副本节点的响应,一直等到过半节点的响应返回。这里的过半节点包括Leader自己。所以在一个只有3个副本节点的系统中,Leader只需要等待一个其他副本节点。
 image-20250131225809410
image-20250131225809410
一旦过半的节点返回了响应,这里的过半节点包括了Leader自己,所以在一个只有3个副本的系统中,Leader只需要等待一个其他副本节点返回对于AppendEntries的正确响应。
 image-20250131225825412
image-20250131225825412
当Leader收到了过半服务器的正确响应,Leader会执行(来自客户端的)请求,得到结果,并将结果返回给客户端。
 image-20250131225835695
image-20250131225835695
与此同时,服务器3可能也会将它的响应返回给Leader,尽管这个响应是有用的,但是这里不需要等待这个响应。这一点对于理解Raft论文中的图2是有用的。
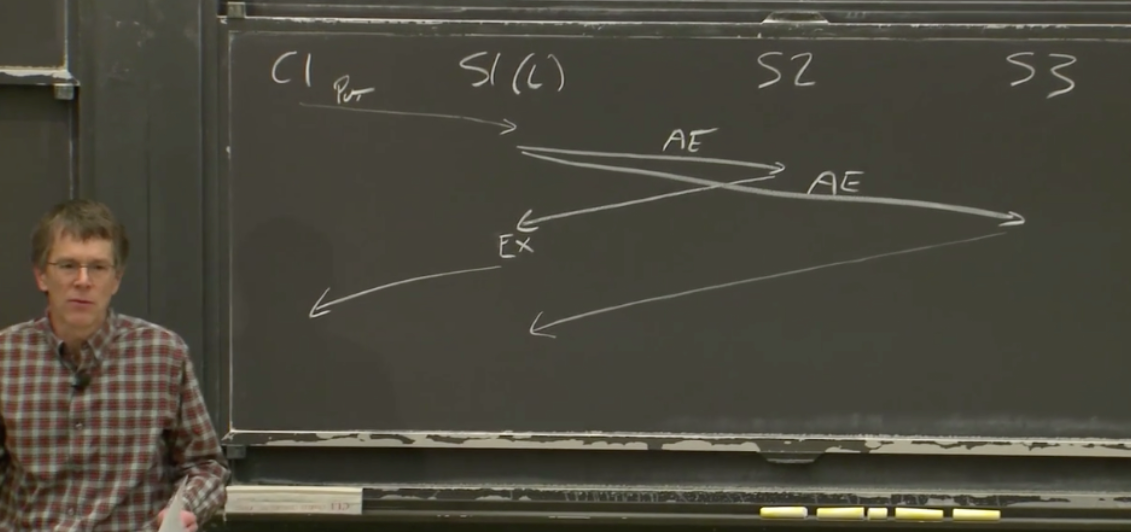 image-20250131225855632
image-20250131225855632
好了,大家明白了吗?这是系统在没有故障情况下,处理普通操作的流程。
学生提问:S2和S3的状态怎么保持与S1同步?
Robert教授:我的天,我忘了一些重要的步骤。现在Leader知道过半服务器已经添加了Log,可以执行客户端请求,并返回给客户端。但是服务器2还不知道这一点,服务器2只知道:我从Leader那收到了这个请求,但是我不知道这个请求是不是已经被Leader提交(committed)了,这取决于我的响应是否被Leader收到。服务器2只知道,它的响应提交给了网络,或许Leader没有收到这个响应,也就不会决定commit这个请求。所以这里还有一个阶段。一旦Leader发现请求被commit之后,它需要将这个消息通知给其他的副本。所以这里有一个额外的消息。
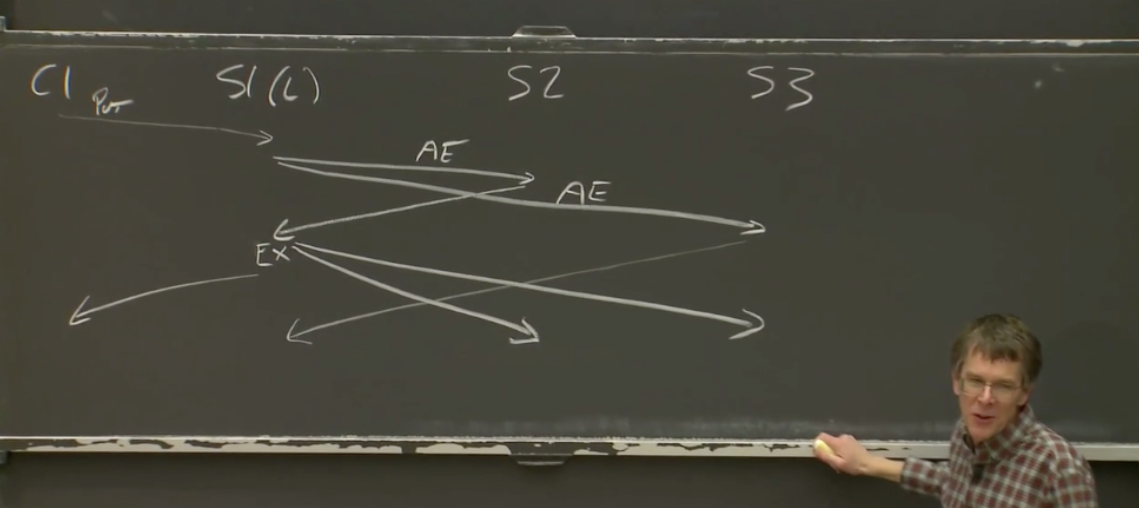 image-20250131225909195
image-20250131225909195
这条消息的具体内容依赖于整个系统的状态。至少在Raft中,没有明确的committed消息。相应的,committed消息被夹带在下一个AppendEntries消息中,由Leader下一次的AppendEntries对应的RPC发出。任何情况下,当有了committed消息时,这条消息会填在AppendEntries的RPC中。下一次Leader需要发送心跳,或者是收到了一个新的客户端请求,要将这个请求同步给其他副本时,Leader会将新的更大的commit号随着AppendEntries消息发出,当其他副本收到了这个消息,就知道之前的commit号已经被Leader提交,其他副本接下来也会执行相应的请求,更新本地的状态。
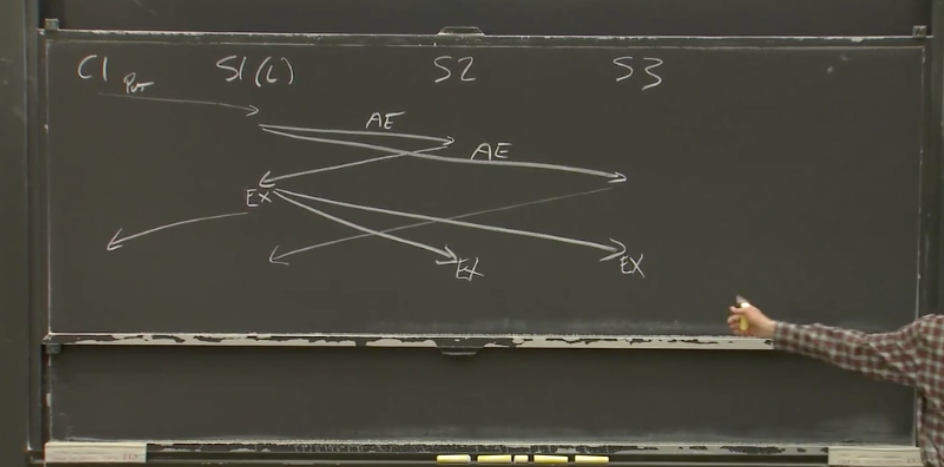 image-20250131225921613
image-20250131225921613
学生提问:这里的内部交互有点多吧?
Robert教授:是的,这是一个内部需要一些交互的协议,它不是特别的快。实际上,客户端发出请求,请求到达某个服务器,这个服务器至少需要与一个其他副本交互,在返回给客户端之前,需要等待多条消息。所以,一个客户端响应的背后有多条消息的交互。
学生提问:也就是说commit信息是随着普通的AppendEntries消息发出的?那其他副本的状态更新就不是很及时了。
Robert教授:是的,作为实现者,这取决于你在什么时候将新的commit号发出。如果客户端请求很稀疏,那么Leader或许要发送一个心跳或者发送一条特殊的AppendEntries消息。如果客户端请求很频繁,那就无所谓了。因为如果每秒有1000个请求,那么下一条AppendEntries很快就会发出,你可以在下一条消息中带上新的commit号,而不用生成一条额外的消息。额外的消息代价还是有点高的,反正你要发送别的消息,可以把新的commit号带在别的消息里。
实际上,我不认为其他副本(非Leader)执行客户端请求的时间很重要,因为没有人在等这个步骤。至少在不出错的时候,其他副本执行请求是个不太重要的步骤。例如说,客户端就没有等待其他副本执行请求,客户端只会等待Leader执行请求。所以,其他副本在什么时候执行请求,不会影响客户端感受的请求时延。
5. 日志
Raft系统之所以对Log关注这么多的一个原因是,Log是Leader用来对操作排序的一种手段。这对于复制状态机(详见4.2)而言至关重要,对于这些复制状态机来说,所有副本不仅要执行相同的操作,还需要用相同的顺序执行这些操作。而Log与其他很多事物,共同构成了Leader对接收到的客户端操作分配顺序的机制。比如说,我有10个客户端同时向Leader发出请求,Leader必须对这些请求确定一个顺序,并确保所有其他的副本都遵从这个顺序。实际上,Log是一些按照数字编号的槽位(类似一个数组),槽位的数字表示了Leader选择的顺序。
Log的另一个用途是,在一个(非Leader,也就是Follower)副本收到了操作,但是还没有执行操作时。该副本需要将这个操作存放在某处,直到收到了Leader发送的新的commit号才执行。所以,对于Raft的Follower来说,Log是用来存放临时操作的地方。Follower收到了这些临时的操作,但是还不确定这些操作是否被commit了。我们将会看到,这些操作可能会被丢弃。
Log的另一个用途是用在Leader节点,我(Robert教授)很喜欢这个特性。Leader需要在它的Log中记录操作,因为这些操作可能需要重传给Follower。如果一些Follower由于网络原因或者其他原因短时间离线了或者丢了一些消息,Leader需要能够向Follower重传丢失的Log消息。所以,Leader也需要一个地方来存放客户端请求的拷贝。即使对那些已经commit的请求,为了能够向丢失了相应操作的副本重传,也需要存储在Leader的Log中。
所有节点都需要保存Log还有一个原因,就是它可以帮助重启的服务器恢复状态。你可能的确需要一个故障了的服务器在修复后,能重新加入到Raft集群,要不然你就永远少了一个服务器。比如对于一个3节点的集群来说,如果一个节点故障重启之后不能自动加入,那么当前系统只剩2个节点,那将不能再承受任何故障,所以我们需要能够重新并入故障重启了的服务器。对于一个重启的服务器来说,会使用存储在磁盘中的Log。每个Raft节点都需要将Log写入到它的磁盘中,这样它故障重启之后,Log还能保留。而这个Log会被Raft节点用来从头执行其中的操作进而重建故障前的状态,并继续以这个状态运行。所以,Log也会被用来持久化存储操作,服务器可以依赖这些操作来恢复状态。
学生提问:假设Leader每秒可以执行1000条操作,Follower只能每秒执行100条操作,并且这个状态一直持续下去,会怎样?
Robert(教授):这里有一点需要注意,Follower在实际执行操作前会确认操作。所以,它们会确认,并将操作堆积在Log中。而Log又是无限的,所以Follower或许可以每秒确认1000个操作。如果Follower一直这么做,它会生成无限大的Log,因为Follower的执行最终将无限落后于Log的堆积。 所以,当Follower堆积了10亿(不是具体的数字,指很多很多)Log未执行,最终这里会耗尽内存。之后Follower调用内存分配器为Log申请新的内存时,内存申请会失败。Raft并没有流控机制来处理这种情况。
所以我认为,在一个实际的系统中,你需要一个额外的消息,这个额外的消息可以夹带在其他消息中,也不必是实时的,但是你或许需要一些通信来(让Follower)告诉Leader,Follower目前执行到了哪一步。这样Leader就能知道自己在操作执行上领先太多。所以是的,我认为在一个生产环境中,如果你想使用系统的极限性能,你还是需要一条额外的消息来调节Leader的速度。
学生提问:如果其中一个服务器故障了,它的磁盘中会存有Log,因为这是Raft论文中图2要求的,所以服务器可以从磁盘中的Log恢复状态,但是这个服务器不知道它当前在Log中的执行位置。同时,当它第一次启动时,它也不知道那些Log被commit了。
Robert教授:所以,对于第一个问题的答案是,一个服务器故障重启之后,它会立即读取Log,但是接下来它不会根据Log做任何操作,因为它不知道当前的Raft系统对Log提交到了哪一步,或许有1000条未提交的Log。
学生补充问题:如果Leader出现了故障会怎样?
Robert教授:如果Leader也关机也没有区别。让我们来假设Leader和Follower同时故障了,那么根据Raft论文图2,它们只有non-volatile状态(也就是磁盘中存储的状态)。这里的状态包括了Log和最近一次任期号(Term Number)。如果大家都出现了故障然后大家都重启了,它们中没有一个在刚启动的时候就知道它们在故障前执行到了哪一步。所以这个时候,会先进行Leader选举,其中一个被选为Leader。如果你回顾一下Raft论文中的图2有关AppendEntries的描述,这个Leader会在发送第一次心跳时弄清楚,整个系统中目前执行到了哪一步。Leader会确认一个过半服务器认可的最近的Log执行点,这就是整个系统的执行位置。另一种方式来看这个问题,一旦你通过AppendEntries选择了一个Leader,这个Leader会迫使其他所有副本的Log与自己保持一致。这时,再配合Raft论文中介绍的一些其他内容,由于Leader知道它迫使其他所有的副本都拥有与自己一样的Log,那么它知道,这些Log必然已经commit,因为它们被过半的副本持有。这时,按照Raft论文的图2中对AppendEntries的描述,Leader会增加commit号。之后,所有节点可以从头开始执行整个Log,并从头构造自己的状态。但是这里的计算量或许会非常大。所以这是Raft论文的图2所描述的过程,很明显,这种从头开始执行的机制不是很好,但是这是Raft协议的工作流程。下一课我们会看一种更有效的,利用checkpoint的方式。
6. 应用层接口
这一部分简单介绍一下应用层和Raft层之间的接口。你或许已经通过实验了解了一些,但是我们这里大概来看一下。假设我们的应用程序是一个key-value数据库,下面一层是Raft层。
 image-20250203170814935
image-20250203170814935
在Raft集群中,每一个副本上,这两层之间主要有两个接口。
第一个接口是key-value层用来转发客户端请求的接口。如果客户端发送一个请求给key-value层,key-value层会将这个请求转发给Raft层,并说:请将这个请求存放在Log中的某处。
 image-20250203170845208
image-20250203170845208
这个接口实际上是个函数调用,称之为Start函数。这个函数只接收一个参数,就是客户端请求。key-value层说:我接到了这个请求,请把它存在Log中,并在committed之后告诉我。
 image-20250203170906267
image-20250203170906267
另一个接口是,随着时间的推移,Raft层会通知key-value层:哈,你刚刚在Start函数中传给我的请求已经commit了。Raft层通知的,不一定是最近一次Start函数传入的请求。例如在任何请求commit之前,可能会再有超过100个请求通过Start函数传给Raft层。
 image-20250203170931436
image-20250203170931436
这个向上的接口以go channel中的一条消息的形式存在。Raft层会发出这个消息,key-value层要读取这个消息。所以这里有个叫做applyCh的channel,通过它你可以发送ApplyMsg消息。
 image-20250203170948828
image-20250203170948828
当然,key-value层需要知道从applyCh中读取的消息,对应之前调用的哪个Start函数,所以Start函数的返回需要有足够的信息给key-value层,这样才能完成对应。Start函数的返回值包括,这个请求将会存放在Log中的位置(index)。这个请求不一定能commit成功,但是如果commit成功的话,会存放在这个Log位置。同时,它还会返回当前的任期号(term number)和一些其它我们现在还不太关心的内容。
 image-20250203171040933
image-20250203171040933
在ApplyMsg中,将会包含请求(command)和对应的Log位置(index)。
 image-20250203171052069
image-20250203171052069
所有的副本都会收到这个ApplyMsg消息,它们都知道自己应该执行这个请求,弄清楚这个请求的具体含义,并将它应用在本地的状态中。所有的副本节点还会拿到Log的位置信息(index),但是这个位置信息只在Leader有用,因为Leader需要知道ApplyMsg中的请求究竟对应哪个客户端请求(进而响应客户端请求)。
学生提问:为什么不在Start函数返回的时候就响应客户端请求呢?
Robert教授:我们假设客户端发送了任意的请求,我们假设这里是一个Put或者Get请求,是什么其实不重要,我们还是假设这里是个Get请求。客户端发送了一个Get请求,并且等待响应。当Leader知道这个请求被(Raft)commit之后,会返回响应给客户端。所以这里会是一个Get响应。所以,(在Leader返回响应之前)客户端看不到任何内容。
这意味着,在实际的软件中,客户端调用key-value的RPC,key-value层收到RPC之后,会调用Start函数,Start函数会立即返回,但是这时,key-value层不会返回消息给客户端,因为它还没有执行客户端请求,它也不知道这个请求是否会被(Raft)commit。一个不能commit的场景是,当key-value层调用了Start函数,Start函数返回之后,它就故障了,所以它必然没有发送Apply Entry消息或者其他任何消息,所以也不能执行commit。
所以实际上,Start函数返回了,随着时间的推移,对应于这个客户端请求的ApplyMsg从applyCh channel中出现在了key-value层。只有在那个时候,key-value层才会执行这个请求,并返回响应给客户端。
有一件事情你们需要熟悉,那就是,首先,对于Log来说有一件有意思的事情:不同副本的Log或许不完全一样。有很多场合都会不一样,至少不同副本节点的Log的末尾,会短暂的不同。例如,一个Leader开始发出一轮AppendEntries消息,但是在完全发完之前就故障了。这意味着某些副本收到了这个AppendEntries,并将这条新Log存在本地。而那些没有收到AppendEntries消息的副本,自然也不会将这条新Log存入本地。所以,这里很容易可以看出,不同副本中,Log有时会不一样。
不过对于Raft来说,Raft会最终强制不同副本的Log保持一致。或许会有短暂的不一致,但是长期来看,所有副本的Log会被Leader修改,直到Leader确认它们都是一致的。
接下来会有有关Raft的两个大的主题,一个是Lab2的内容:Leader Election是如何工作的;另一个是,Leader如何处理不同的副本日志的差异,尤其在出现故障之后。
7. Leader选举(Leader Election)
这一部分我们来看一下Leader选举。这里有个问题,为什么Raft系统会有个Leader,为什么我们需要一个Leader?
答案是,你可以不用Leader就构建一个类似的系统。实际上有可能不引入任何指定的Leader,通过一组服务器来共同认可Log的顺序,进而构建一个一致系统。实际上,Raft论文中引用的Paxos系统就没有Leader,所以这是有可能的。
有很多原因导致了Raft系统有一个Leader,其中一个最主要的是:通常情况下,如果服务器不出现故障,有一个Leader的存在,会使得整个系统更加高效。因为有了一个大家都知道的指定的Leader,对于一个请求,你可以只通过一轮消息就获得过半服务器的认可。对于一个无Leader的系统,通常需要一轮消息来确认一个临时的Leader,之后第二轮消息才能确认请求。所以,使用一个Leader可以提升系统性能至2倍。同时,有一个Leader可以更好的理解Raft系统是如何工作的。
Raft生命周期中可能会有不同的Leader,它使用任期号(term number)来区分不同的Leader。Followers(非Leader副本节点)不需要知道Leader的ID,它们只需要知道当前的任期号。每一个任期最多有一个Leader,这是一个很关键的特性。对于每个任期来说,或许没有Leader,或许有一个Leader,但是不可能有两个Leader出现在同一个任期中。每个任期必然最多只有一个Leader。
那Leader是如何创建出来的呢?每个Raft节点都有一个选举定时器(Election Timer),如果在这个定时器时间耗尽之前,当前节点没有收到任何当前Leader的消息,这个节点会认为Leader已经下线,并开始一次选举。所以我们这里有了这个选举定时器,当它的时间耗尽时,当前节点会开始一次选举。
开始一次选举的意思是,当前服务器会增加任期号(term number),因为它想成为一个新的Leader。而你知道的,一个任期内不能有超过一个Leader,所以为了成为一个新的Leader,这里需要开启一个新的任期。 之后,当前服务器会发出请求投票(RequestVote)RPC,这个消息会发给所有的Raft节点。其实只需要发送到N-1个节点,因为Raft规定了,Leader的候选人总是会在选举时投票给自己。
这里需要注意的一点是,并不是说如果Leader没有故障,就不会有选举。但是如果Leader的确出现了故障,那么一定会有新的选举。这个选举的前提是其他服务器还在运行,因为选举需要其他服务器的选举定时器超时了才会触发。另一方面,如果Leader没有故障,我们仍然有可能会有一次新的选举。比如,如果网络很慢,丢了几个心跳,或者其他原因,这时,尽管Leader还在健康运行,我们可能会有某个选举定时器超时了,进而开启一次新的选举。在考虑正确性的时候,我们需要记住这点。所以这意味着,如果有一场新的选举,有可能之前的Leader仍然在运行,并认为自己还是Leader。例如,当出现网络分区时,旧Leader始终在一个小的分区中运行,而较大的分区会进行新的选举,最终成功选出一个新的Leader。这一切,旧的Leader完全不知道。所以我们也需要关心,在不知道有新的选举时,旧的Leader会有什么样的行为?
(注:下面这一段实际在Lec 06的65-67分钟出现,与这一篇前后的内容在时间上不连续,但是因为内容相关就放到这里来了)
假设网线故障了,旧的Leader在一个网络分区中,这个网络分区中有一些客户端和少数(未过半)的服务器。在网络的另一个分区中,有着过半的服务器,这些服务器选出了一个新的Leader。旧的Leader会怎样,或者说为什么旧的Leader不会执行错误的操作?这里看起来有两个潜在的问题。第一个问题是,如果一个Leader在一个网络分区中,并且这个网络分区没有过半的服务器。那么下次客户端发送请求时,这个在少数分区的Leader,它会发出AppendEntries消息。但是因为它在少数分区,即使包括它自己,它也凑不齐过半服务器,所以它永远不会commit这个客户端请求,它永远不会执行这个请求,它也永远不会响应客户端,并告诉客户端它已经执行了这个请求。所以,如果一个旧的Leader在一个不同的网络分区中,客户端或许会发送一个请求给这个旧的Leader,但是客户端永远也不能从这个Leader获得响应。所以没有客户端会认为这个旧的Leader执行了任何操作。另一个更奇怪的问题是,有可能Leader在向一部分Followers发完AppendEntries消息之后就故障了,所以这个Leader还没决定commit这个请求。这是一个非常有趣的问题,我将会再花45分钟(下一节课)来讲。
学生提问:有没有可能出现极端的情况,导致单向的网络出现故障,进而使得Raft系统不能工作?
Robert教授:我认为是有可能的。例如,如果当前Leader的网络单边出现故障,Leader可以发出心跳,但是又不能收到任何客户端请求。它发出的心跳被送达了,因为它的出方向网络是正常的,那么它的心跳会抑制其他服务器开始一次新的选举。但是它的入方向网络是故障的,这会阻止它接收或者执行任何客户端请求。这个场景是Raft并没有考虑的众多极端的网络故障场景之一。
我认为这个问题是可修复的。我们可以通过一个双向的心跳来解决这里的问题。在这个双向的心跳中,Leader发出心跳,但是这时Followers需要以某种形式响应这个心跳。如果Leader一段时间没有收到自己发出心跳的响应,Leader会决定卸任,这样我认为可以解决这个特定的问题和一些其他的问题。
你是对的,网络中可能发生非常奇怪的事情,而Raft协议没有考虑到这些场景。
所以,我们这里有Leader选举,我们需要确保每个任期最多只有一个Leader。Raft是如何做到这一点的呢?
为了能够当选,Raft要求一个候选人从过半服务器中获得认可投票。每个Raft节点,只会在一个任期内投出一个认可选票。这意味着,在任意一个任期内,每一个节点只会对一个候选人投一次票。这样,就不可能有两个候选人同时获得过半的选票,因为每个节点只会投票一次。所以这里是过半原则导致了最多只能有一个胜出的候选人,这样我们在每个任期会有最多一个选举出的候选人。
同时,也是非常重要的一点,过半原则意味着,即使一些节点已经故障了,你仍然可以赢得选举。如果少数服务器故障了或者出现了网络问题,我们仍然可以选举出Leader。如果超过一半的节点故障了,不可用了,或者在另一个网络分区,那么系统会不断地额尝试选举Leader,并永远也不能选出一个Leader,因为没有过半的服务器在运行。
如果一次选举成功了,整个集群的节点是如何知道的呢?当一个服务器赢得了一次选举,这个服务器会收到过半的认可投票,这个服务器会直接知道自己是新的Leader,因为它收到了过半的投票。但是其他的服务器并不能直接知道谁赢得了选举,其他服务器甚至都不知道是否有人赢得了选举。这时,(赢得了选举的)候选人,会通过心跳通知其他服务器。Raft论文的图2规定了,如果你赢得了选举,你需要立刻发送一条AppendEntries消息给其他所有的服务器。这条代表心跳的AppendEntries并不会直接说:我赢得了选举,我就是任期23的Leader。这里的表达会更隐晦一些。Raft规定,除非是当前任期的Leader,没人可以发出AppendEntries消息。所以假设我是一个服务器,我发现对于任期19有一次选举,过了一会我收到了一条AppendEntries消息,这个消息的任期号就是19。那么这条消息告诉我,我不知道的某个节点赢得了任期19的选举。所以,其他服务器通过接收特定任期号的AppendEntries来知道,选举成功了。
8. 选举定时器(Election Timer)
任何一条AppendEntries消息都会重置所有Raft节点的选举定时器。这样,只要Leader还在线,并且它还在以合理的速率(不能太慢)发出心跳或者其他的AppendEntries消息,Followers收到了AppendEntries消息,会重置自己的选举定时器,这样Leader就可以阻止任何其他节点成为一个候选人。所以只要所有环节都在正常工作,不断重复的心跳会阻止任何新的选举发生。当然,如果网络故障或者发生了丢包,不可避免的还是会有新的选举。但是如果一切都正常,我们不太可能会有一次新的选举。
如果一次选举选出了0个Leader,这次选举就失败了。有一些显而易见的场景会导致选举失败,例如太多的服务器关机或者不可用了,或者网络连接出现故障。这些场景会导致你不能凑齐过半的服务器,进而也不能赢得选举,这时什么事也不会发生。
一个导致选举失败的更有趣的场景是,所有环节都在正常工作,没有故障,没有丢包,但是候选人们几乎是同时参加竞选,它们分割了选票(Split Vote)。假设我们有一个3节点的多副本系统,3个节点的选举定时器几乎同超时,进而期触发选举。首先,每个节点都会为自己投票。之后,每个节点都会收到其他节点的RequestVote消息,因为该节点已经投票给自己了,所以它会返回反对投票。这意味着,3个节点中的每个节点都只能收到一张投票(来自于自己)。没有一个节点获得了过半投票,所以也就没有人能被选上。接下来它们的选举定时器会重新计时,因为选举定时器只会在收到了AppendEntries消息时重置,但是由于没有Leader,所有也就没有AppendEntries消息。所有的选举定时器重新开始计时,如果我们不够幸运的话,所有的定时器又会在同一时间到期,所有节点又会投票给自己,又没有人获得了过半投票,这个状态可能会一直持续下去。
Raft不能完全避免分割选票(Split Vote),但是可以使得这个场景出现的概率大大降低。Raft通过为选举定时器随机的选择超时时间来达到这一点。我们可以这样来看这种随机的方法。假设这里有个时间线,我会在上面画上事件。在某个时间,所有的节点收到了最后一条AppendEntries消息。之后,Leader就故障了。我们这里假设Leader在发出最后一次心跳之后就故障关机了。所有的Followers在同一时间重置了它们的选举定时器,因为它们大概率在同一时间收到了这条AppendEntries消息。
 image-20250203172126615
image-20250203172126615
它们都重置了自己的选举定时器,这样在将来的某个时间会触发选举。但是这时,它们为选举定时器选择了不同的超时时间。
假设故障的旧的Leader是服务器1,那么服务器2(S2),服务器3(S3)会在这个点为它们的选举定时器设置随机的超时时间。
 image-20250203172149555
image-20250203172149555
这个图里的关键点在于,因为不同的服务器都选取了随机的超时时间,总会有一个选举定时器先超时,而另一个后超时。假设S2和S3之间的差距足够大,先超时的那个节点(也就是S2)能够在另一个节点(也就是S3)超时之前,发起一轮选举,并获得过半的选票,那么那个节点(也就是S2)就可以成为新的Leader。大家都明白了随机化是如何去除节点之间的同步特性吗?
这里对于选举定时器的超时时间的设置,需要注意一些细节。一个明显的要求是,选举定时器的超时时间需要至少大于Leader的心跳间隔。这里非常明显,假设Leader每100毫秒发出一个心跳,你最好确认所有节点的选举定时器的超时时间不要小于100毫秒,否则该节点会在收到正常的心跳之前触发选举。所以,选举定时器的超时时间下限是一个心跳的间隔。实际上由于网络可能丢包,这里你或许希望将下限设置为多个心跳间隔。所以如果心跳间隔是100毫秒,你或许想要将选举定时器的最短超时时间设置为300毫秒,也就是3次心跳的间隔。所以,如果心跳间隔是这么多(两个AE之间),那么你会想要将选举定时器的超时时间下限设置成心跳间隔的几倍,在这里。
 image-20250203172249003
image-20250203172249003
那超时时间的上限呢?因为随机的话都是在一个范围内随机,那我们应该在哪设置超时时间的上限呢?在一个实际系统中,有几点需要注意。
 image-20250203172303521
image-20250203172303521
首先,这里的最大超时时间影响了系统能多快从故障中恢复。因为从旧的Leader故障开始,到新的选举开始这段时间,整个系统是瘫痪了。尽管还有一些其他服务器在运行,但是因为没有Leader,客户端请求会被丢弃。所以,这里的上限越大,系统的恢复时间也就越长。这里究竟有多重要,取决于我们需要达到多高的性能,以及故障出现的频率。如果一年才出一次故障,那就无所谓了。如果故障很频繁,那么我们或许就该关心恢复时间有多长。这是一个需要考虑的点。
另一个需要考虑的点是,不同节点的选举定时器的超时时间差(S2和S3之间)必须要足够长,使得第一个开始选举的节点能够完成一轮选举。这里至少需要大于发送一条RPC所需要的往返(Round-Trip)时间。
 image-20250203172448581
image-20250203172448581
或许需要10毫秒来发送一条RPC,并从其他所有服务器获得响应。如果这样的话,我们需要设置超时时间的上限到足够大,从而使得两个随机数之间的时间差极有可能大于10毫秒。
在Lab2中,如果你的代码不能在几秒内从一个Leader故障的场景中恢复的话,测试代码会报错。所以这种场景下,你们需要调小选举定时器超时时间的上限。这样的话,你才可能在几秒内完成一次Leader选举。这并不是一个很严格的限制。
这里还有一个小点需要注意,每一次一个节点重置自己的选举定时器时,都需要重新选择一个随机的超时时间。也就是说,不要在服务器启动的时候选择一个随机的超时时间,然后反复使用同一个值。因为如果你不够幸运的话,两个服务器会以极小的概率选择相同的随机超时时间,那么你会永远处于分割选票的场景中。所以你需要每次都为选举定时器选择一个不同的随机超时时间。
9. 可能的异常情况
一个旧Leader在各种奇怪的场景下故障之后,为了恢复系统的一致性,一个新任的Leader如何能整理在不同副本上可能已经不一致的Log?
这个话题只在Leader故障之后才有意义,如果Leader正常运行,Raft不太会出现问题。如果Leader正在运行,并且在其运行时,系统中有过半服务器。Leader只需要告诉Followers,Log该是什么样子。Raft要求Followers必须同意并接收Leader的Log,这在Raft论文的图2中有说明。只要Followers还能处理,它们就会全盘接收Leader在AppendEntries中发送给它们的内容,并加到本地的Log中。之后再收到来自Leader的commit消息,在本地执行请求。这里很难出错。
在Raft中,当Leader故障了才有可能出错。例如,旧的Leader在发送消息的过程中故障了,或者新Leader在刚刚当选之后,还没来得及做任何操作就故障了。所以这里有一件事情我们非常感兴趣,那就是在一系列故障之后,Log会是怎样?
这里有个例子,假设我们有3个服务器(S1,S2,S3),我将写出每个服务器的Log,每一列对齐之后就是Log的一个槽位。我这里写的值是Log条目对应的任期号,而不是Log记录的客户端请求。所以第一列是槽位1,第二列是槽位2。所有节点在任期3的时候记录了一个请求在槽位1,S2和S3在任期3的时候记录了一个请求在槽位2。在槽位2,S1没有任何记录。
Lab 2: Key/Value Server
intro
在本实验中,你将构建一个单机键值服务器,该服务器确保每个操作即使在网络故障的情况下也能仅执行一次,并且操作是可线性化的。后续实验将复制此类服务器以处理服务器崩溃的情况。
客户端可以向键值服务器发送三种不同的远程过程调用(RPC):Put(key, value)、Append(key, arg) 和 Get(key)。服务器维护一个内存中的键值对映射。键和值均为字符串。Put(key, value) 用于在映射中安装或替换特定键的值,Append(key, arg) 将参数 arg 追加到键的值并返回旧值,Get(key) 获取键的当前值。对于不存在的键,Get 应返回空字符串。对于不存在的键执行 Append 操作时,应将其视为现有值为零长度字符串的情况。每个客户端通过 Clerk(包含 Put/Append/Get 方法)与服务器通信。Clerk 管理与服务器的 RPC 交互。
你的服务器必须确保应用程序对 Clerk 的 Get/Put/Append 方法的调用是可线性化的。如果客户端请求不是并发的,每个客户端的 Get/Put/Append 调用应观察到前面一系列调用所隐含的状态修改。对于并发调用,返回值和最终状态必须与操作按某种顺序依次执行时相同。调用在时间上有重叠时即为并发,例如,如果客户端 X 调用 Clerk.Put(),客户端 Y 调用 Clerk.Append(),然后客户端 X 的调用返回。一个调用必须观察到在其开始之前已完成的所有调用的效果。
线性化对于应用程序来说非常方便,因为这是你从一个依次处理请求的单个服务器中看到的行为。例如,如果一个客户端从服务器获得更新请求的成功响应,随后其他客户端发起的读取操作将肯定能看到该更新的效果。对于单个服务器,提供线性化相对容易。
线性化
Q: 什么是线性化(linearizability)?
A: 线性化是定义服务在面对并发客户端请求时行为正确性的一种方式。大致来说,它规定服务应看起来像是按请求到达的顺序依次执行请求。
线性化是基于“历史记录”定义的:实际客户端请求和服务器响应的轨迹,标注了客户端发送和接收每条消息的时间。线性化告诉你单个历史记录是否合法;我们可以说,如果服务可以生成的每个历史记录都是线性化的,那么该服务就是线性化的。
对于每个客户端请求,请求消息和对应的响应消息是历史记录中的独立元素,每条消息出现在客户端发送或接收的时间点。因此,历史记录明确展示了请求的并发性和网络延迟。
如果可以为每个操作分配一个“线性化点”(一个时间点),使得每个操作的点位于客户端发送请求和接收响应的时间之间,并且历史记录的响应值与按点的顺序依次执行请求时得到的值相同,那么这个历史记录就是线性化的。如果没有任何线性化点的分配能满足这两个要求,那么该历史记录就不是线性化的。
线性化的一个重要后果是,服务在执行并发(时间上重叠)操作的顺序上有一定的自由度。特别是,如果来自客户端C1和C2的请求是并发的,服务器可能会先执行C2的请求,即使C1发送请求消息的时间早于C2。另一方面,如果C1在C2发送请求之前收到了响应,线性化要求服务表现得像是先执行了C1的请求(即C2的操作必须观察到C1操作的效果,如果有的话)。
Q: 线性化检查器是如何工作的?
A: 一个简单的线性化检查器会尝试每一种可能的顺序(或线性化点的选择),以查看是否有一种是根据线性化定义的规则有效的。由于在大型历史记录上这样做会太慢,聪明的检查器会避免查看明显不可能的顺序(例如,提议的线性化点在操作开始时间之前),在可能的情况下将历史记录分解为可以单独检查的子历史记录,并使用启发式方法首先尝试更可能的顺序。
这些论文描述了这些技术;我认为Knossos是基于第一篇论文,而Porcupine增加了第二篇论文中的想法:
http://www.cs.ox.ac.uk/people/gavin.lowe/LinearizabiltyTesting/paper.pdf
https://arxiv.org/pdf/1504.00204.pdf
Q: 服务是否使用线性化检查器来实现线性化?
A: 不;检查器仅在测试中使用。
Q: 那么服务是如何实现线性化的?
A: 如果服务实现为单个服务器,没有复制、缓存或内部并行性,那么服务几乎只需要按请求到达的顺序依次执行客户端请求。主要的复杂性来自于客户端因为认为网络丢失了消息而重新发送请求:对于有副作用的请求,服务必须小心不要执行任何给定的客户端请求超过一次。如果服务涉及复制或缓存,则需要更复杂的设计。
Q: 你知道有哪些现实世界中的系统使用Porcupine或类似的测试框架进行测试的例子吗?
A: 这种测试很常见——例如,可以看看 https://jepsen.io/analyses;Jepsen是一个测试了许多存储系统正确性(以及适当情况下的线性化)的组织。
特别是Porcupine的一个例子:
https://www.vldb.org/pvldb/vol15/p2201-zare.pdf
Q: 还有哪些其他的一致性模型?
A: 查找以下模型:
- 最终一致性
- 因果一致性
- 叉一致性
- 可串行化
- 顺序一致性
- 时间线一致性
还有数据库、CPU内存/缓存系统和文件系统中的其他模型。
一般来说,不同的模型在对应用程序开发者的直观性和性能方面有所不同。例如,最终一致性允许许多异常结果(例如,即使写入已完成,后续读取可能看不到它),但在分布式/复制环境中,它可以比线性化实现更高的性能。
Q: 为什么线性化被称为强一致性模型?
A: 它之所以被称为强一致性模型,是因为它禁止了许多可能会让应用程序开发者感到惊讶的情况。
例如,如果我调用put(x, 22),并且我的put完成,之后没有其他人写x,随后你调用get(x),你保证会看到22,而不是其他值。也就是说,读取会看到最新的数据。
另一个例子是,如果没有人写x,我调用get(x),你调用get(x),我们不会看到不同的值。
这些属性在我们将要研究的其他一致性模型(如最终一致性和因果一致性)中并不成立。这些模型通常被称为“弱”一致性模型。
Q: 人们在实践中如何确保他们的分布式系统是正确的?
A: 我猜彻底的测试是最常见的计划。
正式方法的使用也很普遍;可以看看这里的一些例子:
https://arxiv.org/pdf/2210.13661.pdf
https://dl.acm.org/doi/abs/10.1145/3477132.3483540
https://www.ccs.neu.edu/~stavros/papers/2022-cpp-published.pdf
https://www.cs.purdue.edu/homes/pfonseca/papers/eurosys2017-dsbugs.pdf
Q: 为什么线性化被用作一致性模型,而不是其他模型,如最终一致性?
A: 人们确实经常构建提供比线性化更弱一致性的存储系统,如最终一致性和因果一致性。
线性化对应用程序编写者有一些很好的特性:
- 读取总是观察到最新的数据。
- 如果没有并发写入,所有读者看到相同的数据。
- 在大多数线性化系统上,你可以添加像test-and-set这样的小型事务(因为大多数线性化设计最终会依次执行每个数据项的操作)。
像最终一致性和因果一致性这样的更弱方案可以允许更高的性能,因为它们不要求立即更新所有数据副本。这种更高的性能通常是决定因素。然而,弱一致性为应用程序编写者引入了一些复杂性:
- 读取可以观察到过时的数据。
- 读取可以观察到写入的顺序错误。
- 如果你写入,然后读取,你可能看不到你的写入,而是看到过时的数据。
- 对同一项目的并发更新不是依次执行的,因此很难实现像test-and-set这样的小型事务。
Q: 如何决定线性化的小橙线的位置——操作的线性化点?在图上看起来像是随机画在请求主体内的某个地方?
A: 这个想法是,为了证明执行是线性化的,你需要(作为人类)找到放置小橙线(线性化点)的位置。也就是说,为了证明历史记录是线性化的,你需要找到符合这些要求的操作顺序:
- 所有函数调用都有一个线性化点,位于其调用和响应之间。
- 所有函数似乎在它们的线性化点瞬间发生,按照顺序定义的行为。
因此,一些线性化点的放置是无效的,因为它们位于请求时间范围之外;其他放置是无效的,因为它们违反了顺序定义(对于键值存储,违反意味着读取没有观察到最新写入的值,其中“最新”指的是线性化点)。
在复杂情况下,你可能需要尝试许多线性化点顺序的组合,以找到一个能够证明历史记录是线性化的组合。如果你尝试了所有组合,但没有一个有效,那么该历史记录就不是线性化的。
Q: 是否存在这种情况:如果两个命令同时执行,我们能够强制执行特定行为,使得一个命令总是首先执行(即它总是有更早的线性化点)?
A: 在线性化的存储服务中(例如GFS或你的Lab 3),如果来自多个客户端的请求几乎同时到达,服务可以选择执行它们的顺序。尽管在实践中,大多数服务会按照请求数据包到达网络的顺序执行并发请求。
线性化点的概念是检查历史记录是否线性化的一种策略的一部分。实际实现通常不涉及线性化点的明确概念。相反,它们通常只是按某种串行(依次)顺序执行传入请求。你可以将每个操作的线性化点视为发生在服务执行请求期间的某个时间点。
Q: 我们还可以执行哪些更强的一致性检查?线性化在直觉上感觉不太有用,因为即使同时执行两个命令,你仍然可能读取到不同的数据。
A: 的确,线性化类似于在程序中使用线程而不使用锁——对同一数据的任何并发访问都是竞争条件。以这种方式编程是可能的,但需要小心。
下一个最强的一致性概念涉及事务,如许多数据库中所使用的,这实际上锁定了任何使用的数据。对于读取和写入多个数据项的程序,事务比线性化更容易编程。“可串行化”是一个提供事务的一致性模型的名称。
然而,事务系统比线性化系统更复杂、更慢、更难实现容错。
Q: 为什么验证现实系统涉及“巨大努力”?
A: 验证意味着证明程序是正确的,即它保证符合某些规范。事实证明,证明复杂程序的重要定理是困难的——比普通编程困难得多。
你可以通过尝试这门课程的实验来感受这一点:
https://6826.csail.mit.edu/2020/
Q: 从指定的阅读材料来看,大多数分布式系统没有经过正式证明是正确的。那么一个团队如何决定一个框架或系统已经经过足够充分的测试,可以作为实际产品发布?
A: 在公司耗尽资金并破产之前,开始发布产品并获得收入是一个好主意。人们在这一点之前尽可能多地进行测试,并且通常会尝试说服一些早期客户使用该产品(并帮助发现漏洞),并明确表示产品可能无法正确工作。也许当产品功能足以满足许多客户并且没有已知的重大漏洞时,你就可以准备发布了。
除此之外,明智的客户也会测试他们依赖的软件。没有严肃的组织期望任何软件是无漏洞的。
Q: 为什么不使用客户端发送命令的时间作为线性化点?即让系统按客户端发送请求的顺序执行操作?
A: 很难构建一个保证这种行为的系统——开始时间是客户端代码发出请求的时间,但由于网络延迟,服务可能要到很久之后才会收到请求。也就是说,请求可能以与开始时间顺序大不相同的顺序到达服务。服务原则上可以延迟执行每个到达的请求,以防稍后到达一个具有更早发出时间的请求,但很难正确实现这一点,因为网络不保证限制延迟。而且这可能会增加每个请求的延迟,可能增加很多。话说回来,我们稍后会看到的Spanner使用了相关技术。
像线性化这样的正确性规范需要在足够宽松以高效实现和足够严格以提供对应用程序程序有用的保证之间找到平衡。“看起来按调用顺序执行操作”太严格,难以高效实现,而线性化的“看起来在调用和响应之间执行”虽然对应用程序开发者来说不那么直观,但可以实现。
Q: 如果有并发的get()操作,而同时也有并发的put()操作,get()操作可能会看到不同的值,这是否是个问题?
A: 在存储系统的上下文中,这通常不是问题。例如,如果我们谈论的值是我的个人资料照片,而两个人在更新照片的同时请求查看它,那么他们看到不同的照片(旧的或新的)是完全合理的。
一些存储系统提供了更复杂的方案,特别是事务,这使得这种情况更容易处理。“可串行化”是一个提供事务的一致性模型的名称。然而,事务系统比线性化系统更复杂、更慢、更难实现容错。
Lab 3: Raft 协议
Raft 锁的使用方法
如果你在 6.824 Raft 实验中对于锁的使用感到困惑,以下规则和思考方式可能会有所帮助。
规则 1:当多个 goroutine 使用同一份数据,且至少有一个 goroutine 可能修改该数据时,必须使用锁来防止数据的同时访问。Go 的竞态检测器(race detector)能有效检测此类违规(但对以下其他规则的情况可能无法检测)。
规则 2:当代码对共享数据进行一系列修改操作,且其他 goroutine 在操作中途读取可能导致错误时,必须使用锁包裹整个操作序列。
示例:1
2
3
4rf.mu.Lock()
rf.currentTerm += 1
rf.state = Candidate
rf.mu.Unlock()
若其他 goroutine 看到这两个更新中的任意一个单独生效(例如旧状态配新任期,或新任期配旧状态)都会导致错误。因此需要在整个更新序列中持续持有锁。所有使用 rf.currentTerm 或 rf.state 的代码也必须持有锁以确保独占访问。
Lock() 和 Unlock() 之间的代码通常称为”临界区”。程序员选择的锁规则(例如”使用 rf.currentTerm 或 rf.state 时必须持有 rf.mu”)常被称为”锁协议”。
规则 3:当代码对共享数据进行一系列读取(或读写混合)操作,且该序列中途被修改会导致错误时,必须使用锁包裹整个序列。
Raft RPC 处理程序中的示例:1
2
3
4
5rf.mu.Lock()
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
}
rf.mu.Unlock()
此代码需要在整个操作序列中持续持有锁。Raft 要求 currentTerm 只能递增不能递减。若允许其他 RPC 处理程序在 if 判断和更新操作之间修改 rf.currentTerm,可能导致任期被错误降低。因此必须在整个序列中持续持有锁,同时所有其他 currentTerm 的使用也必须加锁。
实际 Raft 代码需要比这些示例更长的临界区。例如,Raft RPC 处理程序可能需要在整个处理过程中持有锁。
规则 4:在可能引起等待的操作期间持有锁通常是坏习惯,包括:读取 Go 通道、发送到通道、等待定时器、调用 time.Sleep() 或发送 RPC(等待响应)。原因有二:1)等待期间应允许其他 goroutine 继续执行;2)避免死锁。例如两个节点在持有锁时互相发送 RPC,双方的 RPC 处理程序都需要对方持有的锁,导致永久等待。
等待操作前应先释放锁。若不方便,可创建单独的 goroutine 执行等待。
规则 5:注意在释放锁后重新获取时的状态假设。这种情况常见于避免持有锁等待的场景。以下发送投票 RPC 的代码是错误的:
1 | |
问题在于 args.Term 可能与发起选举时的 rf.currentTerm 不同。从创建 goroutine 到实际读取 currentTerm 可能经过多轮任期更迭,节点可能已不再是候选人。修正方法是让新 goroutine 使用外层代码在持有锁时制作的 currentTerm 副本。类似地,在 Call() 后处理回复时,必须重新获取锁并验证所有相关假设(例如检查 rf.currentTerm 是否在选举决定后发生变化)。
实践建议
这些规则的应用可能令人困惑,尤其是规则 2 和 3 中关于”不应被其他 goroutine 读写打断的操作序列”的界定。如何识别这些序列?如何确定序列的起止?
方法一:从无锁代码开始,仔细分析需要加锁的位置。这种方法需要对并发代码正确性进行复杂推理。
更实用的方法:首先注意到如果完全没有并发(无并行执行的 goroutine),就不需要锁。但 RPC 系统创建的 handler goroutine 和为避免等待而创建的 RPC 发送 goroutine 强制引入了并发。可以通过在以下位置获取锁来消除并发:
- RPC handlers 的起始处
- Make() 中创建的后台 goroutine 的起始处
并在这些 goroutine 完全执行完毕返回时才释放锁。这种锁协议确保没有真正的并行执行,从而避免违反规则 1-3 和 5。当每个 goroutine 的代码在单线程环境下正确时,用锁抑制并发后仍能保持正确。
但规则 4 的问题仍然存在。因此下一步需要找出所有等待操作的位置,谨慎地添加锁释放/重新获取(或创建新 goroutine),特别注意重新获取锁后要重新验证状态假设。这种方法可能比直接识别临界区更容易实现正确性。
(注:这种方法的代价是牺牲多核并行执行的性能优势——代码可能在不需要时持有锁,从而不必要地禁止并行执行。但单个 Raft 节点内部本身也没有太多 CPU 并行机会。)
Raft 结构设计建议
一个 Raft 实例需要处理外部事件(Start () 调用、AppendEntries 和 RequestVote RPC、RPC 回复)以及执行周期性任务(选举和心跳)。以下是关于代码结构的若干建议:
- 状态管理
- Raft 实例包含状态数据(日志、当前索引等),这些状态需要通过锁机制在并发协程中安全更新
- Go 官方文档建议使用共享数据结构配合锁机制,而非通道消息传递,这种方式对 Raft 实现更为直接
- 时间驱动任务
- 领导者需要发送心跳
- 其他节点在超时未收到心跳时需要发起选举
- 建议为每个任务分配独立的长运行协程,而非合并到单一协程
- 选举超时管理
- 推荐在 Raft 结构体中维护 “最后收到心跳时间” 变量
- 选举超时协程应周期性检查(建议使用小常量参数的 time.Sleep ())
- 避免使用 time.Ticker 和 time.Timer(容易出错)
- 日志提交协程
- 创建独立的长运行协程通过 applyCh 按顺序发送已提交日志
- 必须保持单协程发送以确保顺序性
- 使用 sync.Cond 条件变量通知该协程更新 commitIndex
- RPC 处理
- 每个 RPC 应在其专属协程中发送和处理回复,原因:
a) 避免不可达节点阻塞多数响应收集
b) 确保心跳和选举定时器持续运行 - RPC 处理应在同一协程完成,而非通过通道传递回复
- 网络注意事项
- 网络可能延迟或重排 RPC 及其响应
- 需注意图 2 中的 RPC 处理规范(如忽略旧 term 的 RPC)
- 领导者处理响应时需检查:
a) term 是否在发送后发生变化
b) 并发 RPC 响应可能改变领导状态(如 nextIndex)
关键实现提示:
- 保持 RPC 处理程序的幂等性
- 注意状态变更的原子性操作
- 合理使用读写锁优化性能
- 实现完善的日志压缩机制
- 注意边界条件处理(如日志回滚场景)
给学生的参考
学生指南:Raft (阅读需 30 分钟)
发布于 2016 年 3 月 16 日,分享在黑客新闻(Hacker News)、推特(Twitter)、龙虾网(Lobsters)
在过去的几个月里,我一直担任麻省理工学院 6.824 分布式系统课程的助教。该课程传统上有一系列基于 Paxos 共识算法的实验,但今年,我们决定改用 Raft 算法。Raft 旨在 “易于理解”,我们希望这一改变能让学生们的学习过程更轻松。
这篇文章以及配套的《教师指南:Raft》记录了我们使用 Raft 的历程,希望对 Raft 协议的实现者以及试图更好理解 Raft 内部原理的学生有所帮助。如果你在寻找 Paxos 与 Raft 的比较,或者对 Raft 进行更具教学意义的分析,你应该去阅读《教师指南》。本文末尾列出了 6.824 课程学生常问的问题及答案。如果你遇到的问题未在本文主体内容中列出,可以查看问答部分。这篇文章篇幅较长,但其中所讲的都是很多 6.824 课程的学生(以及助教)实际遇到的问题,值得一读。
背景
在深入探讨 Raft 之前,了解一些背景信息可能会有所帮助。6.824 课程过去有一组基于 Paxos 的实验,用 Go 语言编写。选择 Go 语言,一方面是因为它对学生来说易于学习,另一方面它非常适合编写并发、分布式应用(goroutine 特别好用)。在四个实验过程中,学生们构建一个容错的、分片的键值存储系统。第一个实验要求他们构建一个基于共识的日志库,第二个实验在其基础上添加一个键值存储,第三个实验在多个容错集群之间对键空间进行分片,并由一个容错的分片管理器处理配置更改。我们还有第四个实验,学生们必须处理机器的故障和恢复,包括磁盘完好和损坏的情况。这个实验是学生们默认的期末项目。
今年,我们决定使用 Raft 重写所有这些实验。前三个实验内容不变,但第四个实验被去掉了,因为 Raft 已经内置了持久化和故障恢复功能。本文将主要讨论我们在第一个实验中的经历,因为它与 Raft 直接相关,不过我也会提及在 Raft 之上构建应用(如第二个实验中的情况)。
对于刚开始了解 Raft 的人来说,用 Raft 协议网站上的文字来描述它最为合适:
Raft 是一种共识算法,旨在易于理解。它在容错性和性能方面与 Paxos 相当。不同之处在于,它被分解为相对独立的子问题,并且清晰地解决了实际系统所需的所有主要部分。我们希望 Raft 能让更多人了解共识算法,并且这些人能够开发出比目前更多高质量的基于共识的系统。
像这样的可视化图表很好地概述了该协议的主要组件,相关论文也很好地阐述了为什么需要各个部分。如果你还没有读过 Raft 的扩展论文,在继续阅读本文之前,你应该先去读一下,因为我将假设你对 Raft 有一定程度的熟悉。
与所有分布式共识协议一样,细节决定成败。在没有故障的稳定状态下,Raft 的行为很容易理解,可以直观地进行解释。例如,从可视化图表中很容易看出,假设没有故障,最终会选出一个领导者,并且最终发送给领导者的所有操作都会被追随者按正确顺序应用。然而,当引入消息延迟、网络分区和服务器故障时,每一个 “如果”“但是” 和 “并且” 都变得至关重要。特别是,由于阅读论文时的误解或疏忽,我们会反复看到一些错误。这个问题并非 Raft 独有,在所有提供正确性保证的复杂分布式系统中都会出现。
实现 Raft
Raft 的终极指南在 Raft 论文的图 2 中。该图指定了 Raft 服务器之间交换的每个 RPC 的行为,给出了服务器必须维护的各种不变量,并指定了某些操作应在何时发生。在本文的其余部分,我们会经常提到图 2。必须严格按照它来实现。
图 2 定义了每个服务器在每种状态下,对于每个传入的 RPC 应该做什么,以及某些其他事情应该在何时发生(例如何时安全地应用日志中的条目)。一开始,你可能会想把图 2 当作一种非正式的指南,读一遍后,就开始编码实现,大致按照它说的去做。这样做,你很快就能让一个基本可用的 Raft 实现运行起来。然后问题就开始出现了。
实际上,图 2 极其精确,从规范的角度来说,它所做的每一个陈述都应该被视为 “必须”(MUST),而不是 “应该”(SHOULD)。例如,当你收到 AppendEntries 或 RequestVote RPC 时,你可能会合理地重置某个对等节点的选举计时器,因为这两个 RPC 都表明其他某个对等节点要么认为自己是领导者,要么正在试图成为领导者。直观地说,这意味着我们不应该干扰。然而,如果你仔细阅读图 2,它说:
如果在没有收到当前领导者的 AppendEntries RPC,也没有投票给候选者的情况下,选举超时时间到了,就转换为候选者状态。
结果证明,这种区别很重要,因为前一种实现方式在某些情况下会显著降低系统的活性。
细节的重要性
为了让讨论更具体,让我们考虑一个绊倒了许多 6.824 课程学生的例子。Raft 论文在多个地方提到了心跳 RPC。具体来说,领导者会偶尔(至少每心跳间隔一次)向所有对等节点发送 AppendEntries RPC,以防止它们发起新的选举。如果领导者没有新的条目要发送给某个特定的对等节点,AppendEntries RPC 就不包含任何条目,此时它被视为心跳。
我们的许多学生认为心跳在某种程度上是 “特殊的”,即当一个对等节点收到心跳时,它应该与处理非心跳的 AppendEntries RPC 区别对待。特别是,许多学生在收到心跳时,只是简单地重置选举计时器,然后返回成功,而不执行图 2 中指定的任何检查。这是极其危险的。通过接受这个 RPC,追随者隐含地告诉领导者,他们的日志与领导者的日志在包括 AppendEntries 参数中 prevLogIndex 所指位置及之前的部分是匹配的。收到回复后,领导者可能会(错误地)决定某个条目已经被复制到了大多数服务器上,并开始提交它。
许多学生(通常是在修复了上述问题之后)遇到的另一个问题是,在收到心跳时,他们会在 prevLogIndex 之后截断追随者的日志,然后追加 AppendEntries 参数中包含的任何条目。这也是不正确的。我们可以再次参考图 2:
如果现有条目与新条目冲突(相同索引但不同任期),删除现有条目及其之后的所有条目。
这里的 “如果” 至关重要。如果追随者拥有领导者发送的所有条目,追随者 “绝不能” 截断其日志。领导者发送的条目之后的任何元素都必须保留。这是因为我们可能收到了领导者过时的 AppendEntries RPC,截断日志意味着 “撤销” 我们可能已经告诉领导者我们日志中已有的条目。
调试 Raft
不可避免的是,你的 Raft 实现的第一个版本会有漏洞。第二个版本也会有,第三个、第四个同样如此。一般来说,每个版本的漏洞会比前一个版本少,根据经验,你的大多数漏洞将是由于没有忠实地遵循图 2 导致的。
在调试 Raft 时,通常有四个主要的漏洞来源:活锁、不正确或不完整的 RPC 处理程序、未遵循规则以及任期混淆。死锁也是一个常见问题,但通常可以通过记录所有的加锁和解锁操作,并找出哪些锁被获取但未释放来进行调试。让我们依次考虑这些问题:
活锁
当你的系统出现活锁时,系统中的每个节点都在做一些事情,但总体上,你的节点处于一种无法取得进展的状态。这种情况在 Raft 中很容易发生,尤其是如果你没有严格遵循图 2 的话。有一种活锁场景特别常见:无法选出领导者,或者一旦选出了领导者,其他某个节点就开始选举,迫使刚当选的领导者立即退位。
出现这种情况的原因有很多,但我们看到许多学生犯了以下几个错误:
- 确保你在图 2 指定的时间准确重置选举计时器。具体来说,只有在以下情况下你才应该重新启动选举计时器:a) 你从当前领导者那里收到了 AppendEntries RPC(即,如果 AppendEntries 参数中的任期过时,你不应该重置计时器);b) 你正在启动一次选举;或者 c) 你投票给了另一个对等节点。
最后一种情况在不可靠的网络中尤其重要,在这种网络中,追随者很可能拥有不同的日志。在那些情况下,你最终往往会发现只有少数服务器能够得到大多数服务器愿意投票支持。如果你在有人请求你投票时就重置选举计时器,那么拥有过时日志的服务器和拥有更新日志的服务器成为领导者的可能性就会一样大。
事实上,由于拥有足够新日志的服务器很少,这些服务器不太可能在足够平静的情况下举行选举并当选。如果你遵循图 2 中的规则,拥有更新日志的服务器就不会被过时服务器的选举打断,因此更有可能完成选举并成为领导者。
- 按照图 2 中关于何时应该启动选举的指示操作。特别要注意的是,如果你是候选者(即你当前正在进行选举),但选举计时器超时了,你应该启动另一次选举。这对于避免由于 RPC 延迟或丢失导致系统停滞很重要。
- 确保在处理传入的 RPC 之前遵循 “服务器规则” 中的第二条规则。第二条规则规定:
如果 RPC 请求或响应包含的任期 T 大于当前任期,将当前任期设置为 T,转换为追随者状态(§5.1)。
例如,如果你已经在当前任期内投过票,而传入的 RequestVote RPC 的任期比你高,你应该首先退位并采用他们的任期(从而重置 votedFor),然后处理这个 RPC,这将导致你授予投票。
不正确的 RPC 处理程序
尽管图 2 清楚地说明了每个 RPC 处理程序应该做什么,但一些微妙之处仍然很容易被忽略。以下是我们反复看到的一些问题,你在实现过程中应该留意:
- 如果某一步说 “回复 false”,这意味着你应该立即回复,并且不执行后续的任何步骤。
- 如果你收到一个 AppendEntries RPC,其 prevLogIndex 指向的位置超出了你日志的末尾,你应该像处理存在该条目但任期不匹配的情况一样处理它(即回复 false)。
- 即使领导者没有发送任何条目,AppendEntries RPC 处理程序的检查 2 也应该执行。
- AppendEntries 最后一步(#5)中的 min 操作是必要的,并且需要用最后一个新条目的索引来计算。仅仅让从日志中在 lastApplied 和 commitIndex 之间应用条目的函数在到达日志末尾时停止是不够的。这是因为在领导者发送给你的条目之后,你的日志中可能存在与领导者日志不同的条目(而领导者发送的条目与你日志中的条目是匹配的)。由于 #3 规定只有在存在冲突条目时才截断日志,这些不同的条目不会被删除,如果 leaderCommit 超出了领导者发送给你的条目,你可能会应用不正确的条目。
- 按照 5.4 节中描述的那样准确实现 “最新日志” 检查非常重要。不要偷懒,只检查日志长度!
未遵循规则
虽然 Raft 论文非常明确地说明了如何实现每个 RPC 处理程序,但它也没有具体说明一些规则和不变量的实现方式。这些内容列在图 2 右侧的 “服务器规则” 部分。虽然其中一些内容相当直观,但也有一些需要你非常仔细地设计应用程序,以确保不违反这些规则:
- 如果在执行过程中的任何时候,commitIndex 大于 lastApplied,你应该应用特定的日志条目。不一定要立即执行(例如在 AppendEntries RPC 处理程序中),但重要的是要确保只由一个实体来执行这个应用操作。具体来说,你要么需要有一个专门的 “应用器”,要么在这些应用操作周围加锁,这样其他例程就不会也检测到需要应用条目并尝试应用。
- 确保你定期检查 commitIndex 是否大于 lastApplied,或者在 commitIndex 更新后(即 matchIndex 更新后)进行检查。例如,如果你在向对等节点发送 AppendEntries 的同时检查 commitIndex,你可能需要等到下一个条目被追加到日志中,才能应用你刚刚发送并得到确认的条目。
- 如果领导者发送一个 AppendEntries RPC,它被拒绝,但不是因为日志不一致(这种情况只可能在我们的任期已过时才会发生),那么你应该立即退位,并且不要更新 nextIndex。如果你更新了,当你立即重新当选时,可能会与 nextIndex 的重置发生竞争。
- 领导者不允许将 commitIndex 更新到前一个任期(或者,就此而言,未来的任期)的某个位置。因此,正如规则所说,你特别需要检查 log [N].term == currentTerm。这是因为如果条目不是来自当前任期,Raft 领导者不能确定该条目实际上已被提交(并且将来不会被更改)。论文中的图 8 说明了这一点。
- 一个常见的混淆来源是 nextIndex 和 matchIndex 之间的区别。特别是,你可能会观察到 matchIndex = nextIndex - 1,然后就干脆不实现 matchIndex。这是不安全的。虽然 nextIndex 和 matchIndex 通常会同时更新为相似的值(具体来说,nextIndex = matchIndex + 1),但它们的用途截然不同。nextIndex 是对领导者与某个给定追随者共享的前缀的猜测。它通常很乐观(我们共享所有内容),只有在收到否定响应时才会向后移动。例如,当一个领导者刚刚当选时,nextIndex 被设置为日志末尾的索引。从某种意义上说,nextIndex 用于提高性能,你只需要向这个对等节点发送这些内容。
matchIndex 用于保证安全性。它是对领导者与某个给定追随者共享的日志前缀的保守测量。matchIndex 绝不能设置为过高的值,因为这可能会导致 commitIndex 向前移动得太远。这就是为什么 matchIndex 初始化为 -1(即我们认为没有共享前缀),并且只有在追随者对 AppendEntries RPC 做出肯定确认时才会更新。
任期混淆
任期混淆是指服务器被来自旧任期的 RPC 弄糊涂。一般来说,在接收 RPC 时,这不是一个问题,因为图 2 中的规则明确说明了当你看到旧任期时应该怎么做。然而,图 2 通常没有讨论当你收到旧的 RPC 回复时应该怎么做。根据经验,我们发现到目前为止最简单的做法是首先记录回复中的任期(它可能高于你当前的任期),然后将当前任期与你在原始 RPC 中发送的任期进行比较。如果两者不同,丢弃回复并返回。只有当两者任期相同时,你才应该继续处理回复。通过一些巧妙的协议推理,这里可能还有进一步的优化方法,但这种方法似乎效果很好。如果不这样做,就会陷入漫长、曲折的困境,充满心血、汗水、泪水和绝望。
一个相关但不完全相同的问题是,假设从发送 RPC 到收到回复期间,你的状态没有改变。一个很好的例子是,当你收到 RPC 的响应时,设置 matchIndex = nextIndex - 1,或者 matchIndex = len (log)。这是不安全的,因为自从你发送 RPC 以来,这两个值都可能已经被更新了。相反,正确的做法是将 matchIndex 更新为你最初在 RPC 参数中发送的 prevLogIndex + len (entries [])。
关于优化的题外话
Raft 论文包含了一些有趣的可选特性。在 6.824 课程中,我们要求学生实现其中两个:日志压缩(第 7 节)和加速日志回溯(第 8 页左上角)。前者对于避免日志无限制增长是必要的,后者对于快速使过时的追随者跟上进度很有用。
这些特性不属于 “核心 Raft”,因此在论文中没有像主要的共识协议那样受到那么多关注。日志压缩在图 13 中有相当详细的介绍,但如果你读得太随意,可能会忽略一些设计细节:
- 对应用状态进行快照时,你需要确保应用状态与 Raft 日志中某个已知索引之后的状态相对应。这意味着应用程序要么需要向 Raft 传达快照对应的索引,要么 Raft 需要在快照完成之前延迟应用额外的日志条目。
- 文本没有讨论当服务器崩溃并重新启动且涉及快照时的恢复协议。特别是,如果 Raft 状态和快照是分别提交的,服务器可能会在持久化快照和持久化更新后的 Raft 状态之间崩溃。这是一个问题,因为图 13 中的步骤 7 规定,快照所涵盖的 Raft 日志必须被丢弃。
如果服务器重新启动时,读取了更新后的快照,但日志是过时的,它可能最终会应用一些已经包含在快照中的日志条目。这是因为 commitIndex 和 lastApplied 没有被持久化,所以 Raft 不知道那些日志条目已经被应用过了。解决这个问题的方法是在 Raft 中引入一个持久状态,记录 Raft 持久化日志中第一个条目的 “实际” 索引对应的值。然后可以将其与加载的快照的 lastIncludedIndex 进行比较,以确定丢弃日志头部的哪些元素。
加速日志回溯优化的说明非常不详细,可能是因为作者认为对于大多数部署来说它不是必需的。从文本中不清楚客户端返回的冲突索引和任期应该如何被领导者用来确定使用哪个 nextIndex。我们认为作者可能希望你遵循的协议是:
- 如果追随者的日志中没有 prevLogIndex,它应该返回 conflictIndex = len (log) 和 conflictTerm = None。
- 如果追随者的日志中有 prevLogIndex,但任期不匹配,它应该返回 conflictTerm = log [prevLogIndex].Term,然后在其日志中搜索第一个条目的任期等于 conflictTerm 的索引。
- 领导者收到冲突响应后,应该首先在其日志中搜索 conflictTerm。如果它在日志中找到一个具有该任期的条目,它应该将 nextIndex 设置为该任期在其日志中最后一个条目的索引之后的那个索引。
- 如果它没有找到具有该任期的条目,它应该将 nextIndex 设置为 conflictIndex。
一个折中的解决方案是只使用 conflictIndex(忽略 conflictTerm),这简化了实现,但这样领导者有时会向追随者发送比使其跟上进度严格所需更多的日志条目。
在 Raft 之上构建应用(续)
在 Raft 之上构建服务(例如 6.824 课程 Raft 实验二中的键值存储)时,服务与 Raft 日志之间的交互可能很难处理得当。本节详细介绍开发过程中的一些方面,你在构建应用程序时可能会发现它们很有用。
应用客户端操作
你可能会对如何依据复制日志来实现应用程序感到困惑。一开始,你可能会让服务在每次收到客户端请求时,将该请求发送给领导者,等待 Raft 应用某些内容,执行客户端请求的操作,然后再返回给客户端。虽然这种方式在单客户端系统中可行,但对于并发客户端却不适用。
相反,服务应该构建为一个状态机,客户端操作会使状态机从一种状态转换到另一种状态。你应该在某个地方设置一个循环,每次获取一个客户端操作(在所有服务器上顺序相同 —— 这就是 Raft 发挥作用的地方),并按顺序将每个操作应用到状态机上。这个循环应该是你代码中唯一接触应用程序状态(6.824 课程中的键值映射)的部分。这意味着面向客户端的 RPC 方法应该只是将客户端的操作提交给 Raft,然后等待这个 “应用循环” 应用该操作。只有当客户端的命令轮到时才执行它,并读取任何返回值。请注意,这也包括读取请求!
这就引出了另一个问题:你如何知道客户端操作何时完成?在无故障的情况下,这很简单 —— 你只需等待放入日志中的内容返回(即被传递给 apply ())。当这种情况发生时,你将结果返回给客户端。然而,如果出现故障会怎样呢?例如,客户端最初联系你时你可能是领导者,但此后其他人当选为领导者,而你放入日志中的客户端请求已被丢弃。显然你需要让客户端重试,但你如何知道何时告诉他们出错了呢?
解决这个问题的一种简单方法是在插入客户端操作时,记录它在 Raft 日志中的位置。一旦该索引处的操作被发送到 apply (),你就可以根据该索引处出现的操作是否实际上是你放入的操作,来判断客户端操作是否成功。如果不是,则发生了故障,可以向客户端返回错误。
重复检测
一旦客户端在遇到错误时重试操作,你就需要某种重复检测机制。例如,如果客户端向你的服务器发送一个 APPEND 请求,没有收到回复,然后又将其重新发送到下一个服务器,你的 apply () 函数需要确保 APPEND 不会被执行两次。为此,你需要为每个客户端请求设置某种唯一标识符,以便你能够识别是否曾经见过,更重要的是,是否应用过某个特定操作。此外,这个状态需要成为你状态机的一部分,以便所有 Raft 服务器都能消除相同的重复操作。
有很多方法可以分配这样的标识符。一种简单且相当高效的方法是为每个客户端分配一个唯一标识符,然后让它们为每个请求标记一个单调递增的序列号。如果客户端重新发送请求,它会重用相同的序列号。你的服务器跟踪每个客户端它所见过的最新序列号,并且简单地忽略任何它已经见过的操作。
棘手的边角情况
如果你的实现遵循上述大致框架,那么至少有两个微妙的问题你很可能会遇到,而且如果不进行一些认真的调试可能很难发现。为你节省一些时间,以下是这两个问题:
- 重新出现的索引:假设你的 Raft 库有某个方法 Start (),它接受一个命令,并返回该命令在日志中放置的索引(这样你就知道何时返回给客户端,如上文所述)。你可能会认为你永远不会看到 Start () 两次返回相同的索引,或者至少,如果你再次看到相同的索引,那么第一次返回该索引的命令一定失败了。事实证明,即使没有服务器崩溃,这两种情况都不是真的。
考虑以下有五台服务器 S1 到 S5 的场景。最初,S1 是领导者,其日志为空。
- 两个客户端操作(C1 和 C2)到达 S1。
- Start () 为 C1 返回 1,为 C2 返回 2。
- S1 向 S2 发送包含 C1 和 C2 的 AppendEntries,但它的所有其他消息都丢失了。
- S3 站出来成为候选者。
- S1 和 S2 不会投票给 S3,但 S3、S4 和 S5 都会投票,所以 S3 成为领导者。
- 另一个客户端请求 C3 进入 S3。
- S3 调用 Start ()(返回 1)。
- S3 向 S1 发送 AppendEntries,S1 从其日志中丢弃 C1 和 C2,并添加 C3。
- S3 在向任何其他服务器发送 AppendEntries 之前失败。
- S1 站出来,由于其日志是最新的,它被选为领导者。
- 另一个客户端请求 C4 到达 S1。
- S1 调用 Start (),返回 2(这也是 Start (C2) 返回的值)。
- S1 的所有 AppendEntries 都被丢弃,S2 站出来。
- S1 和 S3 不会投票给 S2,但 S2、S4 和 S5 都会投票,所以 S2 成为领导者。
- 一个客户端请求 C5 进入 S2。
- S2 调用 Start (),返回 3。
- S2 成功地向所有服务器发送 AppendEntries,S2 通过在下一个心跳中包含更新后的 leaderCommit = 3 向服务器报告。
- 由于 S2 的日志是 [C1 C2 C5],这意味着在索引 2 处提交(并在所有服务器上应用,包括 S1)的条目是 C2。尽管 C4 是最后一个在 S1 返回索引 2 的客户端操作。
- 四路死锁:发现这个问题的功劳全归于 Steven Allen,他是 6.824 课程的另一位助教。他发现了以下这种在基于 Raft 构建应用程序时很容易陷入的棘手四路死锁。
无论你的 Raft 代码如何构建,它可能都有一个类似 Start () 的函数,允许应用程序向 Raft 日志添加新命令。它可能还有一个循环,当 commitIndex 更新时,对日志中 lastApplied 和 commitIndex 之间的每个元素调用应用程序的 apply ()。这些例程可能都需要获取某个锁 a。在你基于 Raft 的应用程序中,你可能在 RPC 处理程序的某个地方调用 Raft 的 Start () 函数,并且在其他某个地方有一些代码,每当 Raft 应用一个新的日志条目时就会收到通知。由于这两者需要通信(即 RPC 方法需要知道它放入日志中的操作何时完成),它们可能都需要获取某个锁 b。
在 Go 语言中,这四个代码段可能看起来像这样:
1 | |
现在考虑如果系统处于以下状态:
- App.RPC 刚刚获取了 a.mutex 并调用了 Raft.Start。
- Raft.Start 正在等待获取 r.mutex。
- Raft.AppendEntries 持有 r.mutex,并且刚刚调用了 App.apply。
我们现在就出现了死锁,因为:
- Raft.AppendEntries 在 App.apply 返回之前不会释放锁。
- App.apply 在获取 a.mutex 之前无法返回。
- a.mutex 在 App.RPC 返回之前不会被释放。
- App.RPC 在 Raft.Start 返回之前不会返回。
- Raft.Start 在获取 r.mutex 之前无法返回。
- Raft.Start 必须等待 Raft.AppendEntries。
有几种方法可以解决这个问题。最简单的方法是在 App.RPC 中调用 a.raft.Start 之后获取 a.mutex。然而,这意味着在 App.RPC 有机会记录它希望被通知之前,App.apply 可能会被调用处理 App.RPC 刚刚调用 Raft.Start 的操作。另一种可能产生更简洁设计的方案是,让一个单独的、专门的线程从 Raft 调用 r.app.apply。这个线程可以在每次 commitIndex 更新时收到通知,然后在应用时就不需要持有锁,从而打破死锁。
Raft 3A. 实现 leader 选举
- leader election
- heartbeats (
AppendEntriesRPCs with no log entries)
leader election
- Reply false if term < currentTerm
- If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote
1 | |
heartbeats
1 | |
1 | |
TestInitialElection3A 过不去
TestInitialElection3A 要注意初始化的时候设置 voteFor = -1,为未投票状态
TestReElection3A 过不去
上面的写法能够过去 TestInitialElection3A,但是无法过去 TestReElection3A。
TestReElection3A 在 3 个节点中选出一个 leader 之后,让 leader disconnected。
这个时候剩余两个节点,一个节点在等待选举超时时,另外一个节点已经触发了超时,这个时候就能够选出一个新的 leader。
这里就有一个问题,上一个 term 选出了 old leader,新 term 的候选者是否应该被投票。因为这个时候的 votedFor 还是 old leader。
这里查看 voteFor 的定义是:candidateId that received vote in current term (or null if none)
更新了 term 之后,voteFor 也要相应地更新。
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower
所以不管是 AppendEntries 还是 RequestVote,只要有更大的 term 就 update。
更新了上面这条之后整个 3A (leader 选举)就完成了。
主要包括:
- 初始化都是 follower 的情况下的 leader 选举。
- 掉线的重新选举。
- 7 个节点任意掉线 3 个的选举。
Raft 3B. 实现日志添加
 AE RPC
AE RPC
 follower 可能出现的日志情况
follower 可能出现的日志情况
TestBasicAgree3B
在网络不可靠的情况下实现最基础的共识算法,为了保证日志匹配属性(如果两个日志包含相同任期和相同index的日志,那么在给定 index 之前的所有 log 都是相同的),需要实现以下两个内容:
- 如果不同日志两条目有相同的 index 和 term,那么他们存储相同的命令。
- 如果不同日志两条目有相同的 index 和 term,那么所有先前的条目都相同。
正常运行时,这样就保证了 leader 的日志和 follower 的日志完全一致。但是因为 leader 可能会宕机,这就导致了日志不一致的情况。于是 follower 可能存在以下情况:
- 缺少条目
- 额外的未提交条目
- 上面两者都有
在 Raft 中,leader 强制 follower 复制自己的日志来保持一致性,于是 follower 的冲突条目将被 leader 给覆盖。
为了实现安全覆盖,leader 需要知道两个日志中一致的最新一条条目,并删除该条目之后的所有条目,并给 follower 发送所有该条目之后的条目。
leader 为每个 follower 维护一个 nextIndex 数组,记录要发给 follower 的下一条的条目的 index。
当首次当选 leader 时,将 nextIndex 初始化为 leader 日志最后一个条目的下一个的 index(也就是假设所有 follower 与 leader 的日志一致,图 7 中就是都是 11)。
如果 follower 和 leader 的日志不一样,那么下一个 AppendEntries RPC 的一致性检查就会失败(AE RPC 图中的 2、3),在拒绝之后 leader 减少 nextIndex 并重新发送 AE RPC,直到 leader 和 follower 的日志匹配。这种情况下,AE RPC 会成功,并且会删除 follower 中任何冲突的条目,并添加新的条目(如果有的话)。一旦成功之后,leader 和 follower 的日志就会在剩下的 leader term 中都保持一致了。
一些优化:
现在 AE RPC 是每次递减 1,然而可以在冲突时,follower 包含冲突的 term 以及该 term 的第一个 index,这样就变成了每次回退一个 term 而不是一个 index。
作者说这个优化其实是不必要的,因为故障发生的频率较低,不会有多个不一致的条目。
AppendEntries RPC 实现:
Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm。
如果日志中没有包含与 preLogTerm 条目匹配的 preLogIndex 条目,则应答 false。
如果是 PrevLogTerm 匹配了,但是 PrevLogIndex 不匹配,这种情况 reply false,让 leader 的 nextIndex - 1 就好。这里也可以使用优化。
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it
这里是 PrevLogIndex 匹配了,而且 PrevLogIndex 对应的 PrevLogTerm 匹配,但是后续的 term 不匹配,这种情况要删除已有的条目和后续条目。
总之,要 PrevLogIndex 和 PrevLogTerm 都匹配才会开始在 follower 写日志,PrevLogIndex 和 PrevLogTerm 匹配代表着找到了相同的 log,于是之后的 log 就以 leader 的为准就好。
PrevLogIndex 和 PrevLogTerm 任意一个不匹配就回退 nextIndex:
- PrevLogIndex 不匹配 nextIndex 就回退到 follower 存在的最大 PrevLogIndex
- PrevLogTerm 不匹配就回退到 follower 和 leader 在
PrevLogTerm和PrevLogIndex都相同的 index。
handleAppendEntriesReply 实现:
这里要注意 matchIndex 的更新是 PrevLogIndex + len (Entries) 而不是 matchIndex = len (log) 这种,因为受到 reply 的时候,log 已经被改变了。
然后要注意如果用了条件变量,要根据需要更新条件变量,否则不会启动日志复制。
同时要注意 follower 以 leader 为准,只要 follower 收到 leader 的 AppendEntries 并 success 之后,就直接添加日志了。
这样就可以过去了。
Raft 3B. TestRPCBytes3B
这个用例测试每个 command 只被发送到 peer 一次。
把测试用例里面自己添加的 Debug 输出给注释掉就过了。
Debug(dTest, "nCommitted cfg.logs: %+v", cfg.logs)
原因应该是 rpc 内容太长了,然后我 debug 输出的时候,耗时太久了,然后 follower 以为 leader 寄了,然后重新当选 leader 触发重传了。
把 debug 的地方换成 time.Sleep(50 * time.Millisecond) 进行测试,发现延时越高,发送的字节数越多。
很神奇的,添加延时之后,heartbeat rpc 就变成了 AppendEntries RPC。
Raft 3B. TestFailNoAgree3B
条件变量标准使用模式
1 | |
互斥锁与条件变量的协作
- 进入临界区:先获取互斥锁
- 条件检查:在锁保护下检查条件
- 等待操作:
Wait()内部自动释放锁,允许其他协程进入临界区 - 被唤醒:重新自动获取锁,再次检查条件
- 退出临界区:显式释放锁
Signal 之前也要先 lock。
Raft 中和集群断开网络的 follower 会自己不断地递增 currentTerm 吗?
答案是肯定的。该 follower 会有很高的 term,那么该 follower 很可能会成为 leader 吗?答案是否定的,因为投票的时候,除了未投票这一条件,还有一个条件是候选者的要和接收者的日志一样新,这样才会去投票。
这个时候原先的节点在知道了有更高的 term 之后,立马成为 follower,并且设置自己的 term = 更高的 term,然后以更高的 term 重新当选为 leader,这个时候掉线的节点就可以恢复日志了。
Raft 3B. TestRejoin3B 过不去
投票的时候判断日志是否是最新
1 | |
这里很关键的是,不是要求 index 和 term 都是候选者大才行,而是任期大,或者任期相同的情况下 index 大。
Raft 3B. TestCount3B
提示 too many RPCs (%v) for 1 second of idleness 原因是判断是否需要复制日志写错了,应该是
return rf.role == Leader && rf.nextIndex[peer] < rf.log[len(rf.log)-1].Index (过不去 TestLeaderFailure3B)
之前写成了
return rf.role == Leader && rf.nextIndex[peer] <= len(rf.log)
导致总是 return true 无限加日志。
又改成了 return rf.role == Leader && rf.nextIndex[peer] < len(rf.log) (过不去 TestFailAgree3B)
按照论文的写法应该是:return rf.role == Leader && rf.nextIndex[peer] <= rf.log[len(rf.log)-1].Index
但是过不去 TestFailAgree3B 以及 TestRejoin3B、TestBackup3B,除此之外都是 ok 的。
TestRejoin3B 过不去原因是 apply error: commit index=3 server=1 105 != server=2 104,但是有时候能过去。
修改了 rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries)) 之后,剩余 TestFailAgree3B 和 TestBackup3B(测试了好几次能过去了)
TestFailAgree3B 是相互之间都不给对方投票,因为 candidate’s older log。原因是上面的 isLogLeastAsReceiver 写错了,改写成
1 | |
就 OK 了。
还有 rf.replicatorCond[peer].L.Lock() 不要乱用。
参考
- 本文作者:EnableAsync
- 本文链接:https://enableasync.github.io/uncategorized/6-824/index.html
- 版权声明:本博客所有文章均采用 BY-NC-SA 许可协议,转载请注明出处!