注意事项 rust 中 dbg! 超时在 rust 中使用 dbg! 的时候,在题目判定时,可能会因为 dbg! 超时,提交代码的时候要去掉 dbg!
数组 双指针 第 27、977 题就是经典的双指针题目。
滑动窗口 注意,使用滑动窗口的时候,只用一个 for 循环代表滑动窗口的结尾,否则又会陷入两个 for 的困境。
前缀和 1 2 3 for (int i = 1 ; i <= n; i++) {1 ] + a[i];
Java 多组输入示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import java.util.Scanner;public class Main {public static void main (String[] args) {Scanner scanner = new Scanner (System.in);int n = scanner.nextInt();int [] nums = new int [n + 1 ];int [] s = new int [n + 1 ];for (int i = 1 ; i <= n; i++) {1 ] + nums[i];while (scanner.hasNextInt()) {int a = scanner.nextInt();int b = scanner.nextInt();1 ] - s[a]);
模拟矩阵
走完一行或者一列对 x 和 y 进行处理,使得继续走下一行而不下标越界
走完一行或者一列对 x 和 y 进行处理,使得走到没有写数字的地方
走完一行或者一列对边界进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 class Solution {public int [][] generateMatrix(int n) {int [][]result = new int [n][n];int count = 1 ;int x = 0 , y = 0 ;int xMax = n, yMax = n, xMin = 0 , yMin = 0 ;while (count <= n * n) {while (y < yMax) {1 ; while (x < xMax) {1 ; while (y >= yMin) {1 ; while (x >= xMin) {1 ; return result;
最大子数组和 dp[i] 代表以第 i 个元素结尾的最大子数组的和:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public int maxSubArray (int [] nums) {int n = nums.length;int [] dp = new int [n + 1 ];int ans = nums[0 ];0 ] = 0 ;for (int i = 1 ; i <= n; i++) {1 ] + nums[i - 1 ], nums[i - 1 ]);return ans;
合并区间 要点在于判断什么时候可以合并,什么时候不能合并:
先根据开头位置排序
下一个区间的开头大于当前末尾的时候不能合并
其他情况可以合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int [][] merge(int [][] intervals) {return a[0 ] - b[0 ]; });int []> ans = new ArrayList <>();0 ]);for (int i = 1 ; i < intervals.length; i++) {int right = ans.get(ans.size() - 1 )[1 ];if (intervals[i][0 ] > right) { else { 1 ]);1 )[1 ] = right;return ans.toArray(new int [ans.size()][]);
轮转数组 反转三次数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public void rotate (int [] nums, int k) {int n = nums.length;0 , n - 1 );0 , (k % n) - 1 );1 );private void reverse (int [] nums, int start, int end) {while (start < end) {int tmp = nums[start];
除自身以外数组的乘积 要求不使用除法,并且当前元素如果为 0 的时候,总和除以当前元素也用不了。
没有优化 要点在于将当前以外的乘积分为左边和右边部分,这样就可以划分并逐步计算得到答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public int [] productExceptSelf(int [] nums) {int n = nums.length;int [] l = new int [n + 1 ], r = new int [n + 1 ];0 ] = 1 ;1 ;for (int i = 1 ; i <= n; i++) {1 ] * nums[i - 1 ];for (int j = n - 1 ; j >= 1 ; j--) {1 ] * nums[j];int [] ans = new int [n];for (int i = 0 ; i < n; i++) {1 ];return ans;
优化空间
用 ans 数组记录右边数组的乘积,然后用一个变量记录左边数组的乘积。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public int [] productExceptSelf(int [] nums) {int n = nums.length;int [] ans = new int [n];0 ] = 1 ;1 ] = nums[n - 1 ];for (int i = n - 2 ; i >= 0 ; i--) {1 ] * nums[i];int l = 1 ;for (int i = 0 ; i < n; i++) {int r = 1 ;if (i < n - 1 ) r = ans[i + 1 ];return ans;
缺失的第一个正数 要点在于
原地哈希,f(nums[i]) = nums[i] - 1
其他的在于防止死循环和保证所有数字都被 hash 过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public int firstMissingPositive (int [] nums) {int n = nums.length;for (int i = 0 ; i < n; i++) {boolean isSwap = true ;while (isSwap) {int hash = nums[i] - 1 ;if (0 <= hash && hash < n && i != hash && nums[hash] != nums[i]) { else {false ;for (int i = 0 ; i < n; i++) {if (i + 1 != nums[i]) {return i + 1 ;return n + 1 ;private void swap (int [] nums, int i, int j) {int tmp = nums[i];
矩阵 矩阵置零 给定一个 m x n0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地
难点在于原地算法,否则很简单,模拟就好,模拟的时候注意不要跳过本来为 0 的元素。
旋转图像 要点在于:
做不到一步直接交换到位
先副对角线对称,然后上下对称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public void rotate (int [][] matrix) {int n = matrix.length;for (int i = 0 ; i < n; i++) {for (int j = 0 ; j <= n - 1 - i; j++) {1 - j, n - 1 - i);for (int i = 0 ; i < n / 2 ; i++) {for (int j = 0 ; j < n; j++) {1 - i, j);public void swap (int [][] matrix, int i, int j, int x, int y) {int tmp = matrix[i][j];
搜索二维矩阵 II img
二分 每一行二分搜索
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public boolean searchMatrix (int [][] matrix, int target) {for (int [] nums : matrix) {if (Arrays.binarySearch(nums, target) >= 0 ) {return true ;return false ;
总时间复杂度 O(m logn)
Z 字搜索 要点在于:
看矩阵右上角,左边严格小于,下面严格大于
所以每次可以排除掉一行或者一列,总时间复杂度 O(m + n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public boolean searchMatrix (int [][] matrix, int target) {int m = matrix.length;int n = matrix[0 ].length;int row = 0 , col = n - 1 ;while (row < m && col >= 0 ) {if (target == matrix[row][col]) {return true ;else if (target > matrix[row][col]) {else { return false ;
双指针 移动零 10^4 O(n)
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
key: 保证 right 在 left 左边。
盛最多水的容器 10^5 O(n)
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明: 你不能倾斜容器。
思考: 有两个变量决定盛水量:1. 左右的距离。 2. 较低的柱子高度。
左右的距离最左到最右最大,然后慢慢缩小。
如果移动较高的柱子,那么盛水量不会变大,但是如果移动较低的柱子,那么盛水量有可能会变大。
接雨水 2 * 10^4
img
1 2 3 输入:height = [0,1,0,2 ,1,0,1,3 ,2,1,2,1 ]6 0,1,0,2 ,1,0,1,3 ,2,1,2,1 ] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
key: 某一处的雨水 = 全局左右最高柱子的最小值 - 当前处的高度
剩下的点就在求左右最高柱子处进行优化。
动态规划 将左右最高柱子的高度分别记为 leftMax,rightMax,并 O(n) 计算出这个数组的。
可以用动态规划求 left 和 right 的原因是这里的 left 和 right 表示的是全局最高,而柱状图中最大的矩形 这道题中不是全局最低的。
需要注意的点是 初始值 和 边界 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int trap (int [] height) {int n = height.length;int [] leftMax = new int [n];int [] rightMax = new int [n];0 ] = height[0 ];for (int i = 1 ; i < n; i++) {1 ], height[i]);1 ] = height[n - 1 ];for (int i = n - 2 ; i >= 0 ; i--) {1 ], height[i]);int total = 0 ;for (int i = 1 ; i < n; i++) {return total;
时间复杂度:O(n),其中 n 是数组 height 的长度。计算数组 leftMax 和 rightMax 的元素值各需要遍历数组 height 一次,计算能接的雨水总量还需要遍历一次。
空间复杂度:O(n),其中 n 是数组 height 的长度。需要创建两个长度为 n 的数组 leftMax 和 rightMax。
单调栈 双指针 动态规划计算 leftMax 和 rightMax 的时候需要遍历一次数组,能不能直接得到 leftMax 和 rightMax 而不遍历呢?这样就可以将得到 max 的复杂度降低为 O(1) 了。
与盛最多水的容器相同的思路,可以从两边的雨水向中间进行计算 ,这样可以 O(1) 得到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int trap (int [] height) {int n = height.length;int ans = 0 ;int left = 0 , right = n - 1 ;int maxLeft = 0 , maxRight = 0 ;while (left < right) {if (height[left] > height[right]) {else {return ans;
滑动窗口 滑动窗口模板 1 2 3 4 5 6 7 8 for (int l = 0 , r = 0 ; r < n ; r++) {while (l <= r && check()) {
无重复字符的最长子串 5 * 10^4 级别
给定一个字符串 s ,请你找出其中不含有重复字符的最长子串的长度。
判断重复字符:Set
最长字串:滑动窗口
这道题官方解答为枚举所有起始位置,之后向右延申至不含重复字符的最长子串长度,如果包含重复字符,那么左指针持续移动到不含重复字符为止。
关键在于有重复字符的时候,是左指针持续地向右移动,而不是重新开始枚举,因为这个操作,使得时间复杂度为 O(n),那么为什么这样不会漏掉答案呢?也就是说为什么这样一定会取到最优答案呢?
因为当右边要出现重复字母的的候,这个时候左指针到右指针的子串一定是对应了右指针不移动情况下的最优子串。
所以可以枚举右指针,并让左指针不断向右。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public int lengthOfLongestSubstring (String s) {new HashSet <>();int n = s.length(), l = 0 , ans = 0 ;for (int r = 0 ; r < n; r++) {while (set.contains(s.charAt(r))) {1 );return ans;
找到字符串中所有字母异位词 给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
3 * 10^4 级别
与上一题相同,需要做以下操作:
判断异位词。
异位词子串。
确定异位词需要 O(n),n 是字符串长度。
key: 在这道题中,异位词和原词肯定是长度相同的,所以直接用固定长度的滑动窗口滑过去,这样时间复杂度为 O(n * m)。但是有更好的做法,就是当向右滑动的时候,删掉的是左面的字母,如果右边能够补齐,那么就说明是异位词,这样就可以 O(1) 判断异位词,再加上滑动的耗时,总计 O(m)。
Arrays.equals 可以判断两个数组相等。
统计好子数组的数目 给你一个整数数组 nums 和一个整数 k ,请你返回 nums 中 好 子数组的数目。
一个子数组 arr 如果有 至少 k 对下标 (i, j) 满足 i < j 且 arr[i] == arr[j] ,那么称它是一个 好 子数组。
子数组 是原数组中一段连续 非空 的元素序列。
示例 1:
1 2 3 输入:nums = [1,1,1,1,1] , k = 10 1
示例 2:
1 2 3 4 5 6 7 输入:nums = [3,1,4,3,2,2,4] , k = 2 4 4 个不同的好子数组:[3,1,4,3,2,2] 有 2 对。[3,1,4,3,2,2,4] 有 3 对。[1,4,3,2,2,4] 有 2 对。[4,3,2,2,4] 有 2 对。
提示:
1 <= nums.length <= 10^51 <= nums[i], k <= 10^9
核心思路:
如果窗口中有 c 个元素 x,再进来一个 x,会新增 c 个相等数对。
外层循环:从小到大枚举子数组右端点 right。现在准备把 x=nums[right] 移入窗口,那么窗口中有 cnt[x] 个数和 x 相同,所以 pairs 会增加 cnt[x]。然后把 cnt[x] 加一。
内层循环:如果发现 pairs≥k,说明子数组符合要求,右移左端点 left,先把 cnt[nums[left]] 减少一,然后把 pairs 减少 cnt[nums[left]]。
内层循环结束后,[left,right] 这个子数组是不满足题目要求的,但在退出循环之前的最后一轮循环,[left−1,right] 是满足题目要求的。由于子数组越长,越能满足题目要求,所以除了 [left−1,right],还有 [left−2,right],[left−3,right],…,[0,right] 都是满足要求的。也就是说,当右端点固定在 right 时,左端点在 0,1,2,…,left−1 的所有子数组都是满足要求的,这一共有 left 个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public long countGood (int [] nums, int k) {long ans = 0 ;new HashMap <>();int pairs = 0 ;int left = 0 ;for (int x : nums) {int c = cnt.getOrDefault(x, 0 );1 );while (pairs >= k) {1 ; 1 );return ans;
统计得分小于 K 的子数组数目 越短越合理。
滑动窗口使用前提:
连续子数组/子串。
有单调性。本题元素均为正数,所以子数组越长,分数越高;子数组越短,分数越低。这意味着只要某个子数组的分数小于 k,在该子数组内的更短的子数组,分数也小于 k。
为什么用滑动窗口的复杂度为 O(n):虽然用了两个循环,但是内层循环的总循环次数不超过 n,所以总的时间复杂度为 O(n)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {long [] sum;public long countSubarrays (int [] nums, long k) {int n = nums.length;new long [n + 1 ];long ans = 0 ;for (int i = 1 ; i <= n; i++) {1 ] + nums[i - 1 ];int left = 0 ;for (int right = 1 ; right <= n; right++) {while (left < right && !check(left, right, k)) {return ans;private boolean check (int left, int right, long k) {return (right - left) * (sum[right] - sum[left]) < k;
小优化 可以不用前缀和,把前缀和动态维护。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {long sum = 0 ;public long countSubarrays (int [] nums, long k) {int n = nums.length;long ans = 0 ;int left = 0 ;for (int right = 1 ; right <= n; right++) {1 ];while (left < right && !check(left, right, sum, k)) {return ans;private boolean check (int left, int right, long sum, long k) {return (right - left) * sum < k;
统计最大元素出现至少 K 次的子数组 给你一个整数数组 nums 和一个 正整数 k 。
请你统计有多少满足 「 nums 中的 最大 元素」至少出现 k 次的子数组,并返回满足这一条件的子数组的数目。
子数组是数组中的一个连续元素序列。
示例 1:
1 2 3 输入:nums = , k = 2
示例 2:
1 2 3 输入:nums = [1,4,2,1], k = 3 4 至少 3 次。
越长越合法。
内层循环结束后,[left,right] 这个子数组是不满足题目要求的,但在退出循环之前的最后一轮循环,[left−1,right] 是满足题目要求的。由于子数组越长,越能满足题目要求,所以除了 [left−1,right],还有 [left−2,right],[left−3,right],…,[0,right] 都是满足要求的。也就是说,当右端点固定在 right 时,左端点在 0,1,2,…,left−1 的所有子数组都是满足要求的,这一共有 left 个,加到答案中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public long countSubarrays (int [] nums, int k) {long ans = 0 ;int left = 0 , n = nums.length, count = 0 ;int max = nums[0 ];for (int i = 1 ; i < n; i++) {for (int right = 0 ; right < n; right++) {if (nums[right] == max) count++;while (count == k) { if (nums[left] == max) {return ans;
区间 合并区间 先排序,排序之后放入第一个元素,然后判断后续的开头是不是小于第一个元素的结尾,如果是的话就连起来,否则就形成新的区间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public int [][] merge(int [][] intervals) {return a1[0 ] - a2[0 ];int []> ans = new ArrayList <>();0 ]);for (int i = 1 ; i < intervals.length; i++) {if (intervals[i][0 ] > ans.get(ans.size() - 1 )[1 ]) {else {int right = ans.get(ans.size() - 1 )[1 ];1 ]);1 )[1 ] = right;return ans.toArray(new int [ans.size()][]);
区间列表的交集 因为两个列表里都为不相交且已经排序好的区间,我们可以使用双指针逐个检查重合区域
对于两个区间arr1=[left1,right1],arr2=[left2,right2]
若两个区间arr1与arr2相交, 那么重合区域为[max(left1,left2),min(right1,right2)]
假设right1<right2, 因为区间列表为不相交且已经排序好的, 则arr1不可能与secondList中arr2以后的任何区间相交。 所以每次优先移动当前区间尾段较小的指针 (right2<right1同理)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public int [][] intervalIntersection(int [][] firstList, int [][] secondList) {int []> ans = new ArrayList ();int i = 0 , j = 0 ;int n1 = firstList.length, n2 = secondList.length;while (i < n1 && j < n2) {int [] arr1 = firstList[i];int [] arr2 = secondList[j];int l = Math.max(arr1[0 ], arr2[0 ]);int r = Math.min(arr1[1 ], arr2[1 ]);if (l <= r) ans.add(new int []{l, r});if (arr1[1 ] < arr2[1 ]) i++;else j++;return ans.toArray(new int [ans.size()][]);
链表 链表对于有插入、交换或者删除的操作的时候,一般加一个虚拟头节点 更好处理。
203.移除链表元素
707.设计链表
206.翻转链表
206.翻转链表
19.删除链表的倒数第 N 个结点
K 个一组翻转链表 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
Key: 关键在于写一个 reverse 函数逆转从 head 到 tail 的链表。其中 reverse 函数可以返回逆转后的最后一个节点。还有需要维护返回的节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution {public ListNode reverseKGroup (ListNode head, int k) {if (k == 1 ) return head;boolean first = true ;ListNode dummy = new ListNode (0 , head), cur = head, pre = dummy, ret = null ;int count = 0 ;while (cur != null ) {if (count == k) {if (first) {false ;0 ;return ret;private ListNode reverse (ListNode pre, ListNode head, ListNode tail) {ListNode cur = head.next, retTail = head;while (cur != tail) { ListNode next = cur.next;return retTail;
排序链表 要点在于排序 + 链表操作
题目的进阶问题要求达到 O(nlogn) 的时间复杂度和 O(1) 的空间复杂度,时间复杂度是 O(nlogn) 的排序算法包括归并排序、堆排序和快速排序(快速排序的最差时间复杂度是 O(n^2)),其中最适合链表的排序算法是归并排序。
归并排序基于分治算法。最容易想到的实现方式是自顶向下的递归实现,考虑到递归调用的栈空间,自顶向下归并排序的空间复杂度是 O(logn)。如果要达到 O(1) 的空间复杂度,则需要使用自底向上的实现方式。=
递归写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Solution {public ListNode sortList (ListNode head) {if (head == null || head.next == null ) return head;ListNode mid = findMiddle(head);ListNode rightHead = mid.next;null ; ListNode left = sortList(head);ListNode right = sortList(rightHead);return mergeList(left, right);private ListNode mergeList (ListNode l1, ListNode l2) {ListNode dummy = new ListNode (0 );ListNode cur = dummy;while (l1 != null && l2 != null ) {if (l1.val < l2.val) {else {if (l1 != null ) {if (l2 != null ) {return dummy.next;private ListNode findMiddle (ListNode head) {ListNode slow = head;ListNode fast = head.next; while (fast != null && fast.next != null ) {return slow;
迭代写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 class Solution {public ListNode sortList (ListNode head) {ListNode dummy = new ListNode (0 , head);int length = listLength(head);for (int step = 1 ; step < length; step *= 2 ) {ListNode cur = dummy.next;ListNode newTail = dummy;while (cur != null ) {ListNode head1 = cur;ListNode head2 = splitList(head1, step);ListNode merged = mergeList(head1, head2);int len = 0 ;ListNode curr = merged;while (len < step * 2 && curr.next != null ) {return dummy.next;private ListNode splitList (ListNode head, int size) {ListNode cur = head;for (int i = 0 ; i < size - 1 && cur != null ; i++) {if (cur == null || cur.next == null ) return null ;ListNode nextHead = cur.next;null ; return nextHead;private int listLength (ListNode head) {int length = 0 ;while (head != null ) {return length;private ListNode mergeList (ListNode l1, ListNode l2) {ListNode dummy = new ListNode (0 );ListNode cur = dummy;while (l1 != null && l2 != null ) {if (l1.val < l2.val) {else {if (l1 != null ) {if (l2 != null ) {return dummy.next;
合并 K 个升序链表 朴素做法 用一个数组存储所有的 head,然后每次取出所有数组的最小值,然后插入到链表最后面。
每次取出最小值,复杂度为 O(k),然后一共要取 k n 次,n 是最长链表的长度,这样时间复杂度为 O(k^2 n),每次取出最小值的时候,有比较被浪费掉了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution {public ListNode mergeKLists (ListNode[] lists) {ListNode dummy = new ListNode (0 );ListNode cur = dummy;new ListNode [lists.length];int allLength = 500 * 10000 ;for (int i = 0 ; i < lists.length; i++) {int i = 0 ;while (i < allLength) {int minVal = 0x3f3f3f3f ;int minIndex = -1 ;for (int j = 0 ; j < lists.length; j++) {if (head[j] != null && minVal > head[j].val) {if (minIndex == -1 ) break ;return dummy.next;
二分做法 img
复杂度计算:
image-20250202004335203
链表两两合并避免比较浪费,左闭右闭实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution {public ListNode mergeKLists (ListNode[] lists) {return mergeLists(lists, 0 , lists.length - 1 );private ListNode mergeLists (ListNode[] lists, int l, int r) {if (l == r) return lists[l];if (l > r) return null ;int mid = l + (r - l) / 2 ;return mergeTwoLists(mergeLists(lists, l, mid), mergeLists(lists, mid + 1 , r));private ListNode mergeTwoLists (ListNode a, ListNode b) {ListNode dummy = new ListNode (0 );ListNode cur = dummy;while (a != null && b != null ) {if (a.val <= b.val) {else {if (a != null ) cur.next = a;if (b != null ) cur.next = b;return dummy.next;
左闭右开实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution {public ListNode mergeKLists (ListNode[] lists) {return mergeLists(lists, 0 , lists.length);private ListNode mergeLists (ListNode[] lists, int l, int r) {if (l >= r) return null ;if (r - l == 1 ) return lists[l];int mid = l + (r - l) / 2 ;return mergeTwoLists(mergeLists(lists, l, mid), mergeLists(lists, mid, r));private ListNode mergeTwoLists (ListNode a, ListNode b) {ListNode dummy = new ListNode (0 );ListNode cur = dummy;while (a != null && b != null ) {if (a.val <= b.val) {else {if (a != null ) cur.next = a;if (b != null ) cur.next = b;return dummy.next;
二叉树 二叉树的中序遍历 递归做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {new ArrayList <>();public List<Integer> inorderTraversal (TreeNode root) {return list;private void helper (TreeNode root) {if (root == null ) {return ;
非递归做法,用一个栈模拟递归栈。
前序遍历是中左右,如果还有左子树就一直向下找。完了之后再返回从最底层逐步向上向右找。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public List<Integer> inorderTraversal (TreeNode root) {new ArrayList <>();new LinkedList <>();while (root != null || !stack.isEmpty()) {while (root != null ) {return list;
中序是左中右,如果还有左子树就一直向下找,直到左边最底部,然后处理节点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public List<Integer> inorderTraversal (TreeNode root) {new ArrayList <>();new LinkedList <>();while (root != null || !stack.isEmpty()) {while (root != null ) {return list;
前序是先中间,再左边然后右边,而这里是先中间,再后边然后左边。那我们完全可以改造一下前序遍历,得到序列new_seq之后再reverse一下就是想要的结果了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public List<Integer> inorderTraversal (TreeNode root) {new ArrayList <>();new LinkedList <>();while (root != null || !stack.isEmpty()) {while (root != null ) {return list;
二叉树的最大深度 要点在于如何记录深度,递归的时候可以通过传参解决:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {int maxDepth = 0 ;public int maxDepth (TreeNode root) {0 );return maxDepth;private void helper (TreeNode root, int depth) {if (root == null ) {return ;1 );1 );
1 2 3 4 5 6 7 8 9 10 11 class Solution {public int maxDepth (TreeNode root) {if (root == null ) {return 0 ;else {int leftHeight = maxDepth(root.left);int rightHeight = maxDepth(root.right);return Math.max(leftHeight, rightHeight) + 1 ;
反转二叉树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public TreeNode invertTree (TreeNode root) {return root;private TreeNode helper (TreeNode root) {if (root == null ) return null ;TreeNode left = helper(root.right);TreeNode right = helper(root.left);return root;
对称二叉树 这里注意条件是 left.val == right.val && helper(left.left, right.right) && helper(left.right, right.left) ,因为对称是中心轴对称,而不是左右相等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {new ArrayList <>();public boolean isSymmetric (TreeNode root) {return helper(root.left, root.right);private boolean helper (TreeNode left, TreeNode right) {if (left == null && right == null ) {return true ;if (left == null || right == null ) {return false ;return left.val == right.val
二叉树的直径 二叉树的直径 = 最深左子树深度 + 最深右子树深度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {int ans = 0 ;public int diameterOfBinaryTree (TreeNode root) {return ans;private int helper (TreeNode root) {if (root == null ) return 0 ;int leftMax = helper(root.left);int rightMax = helper(root.right);return Math.max(leftMax, rightMax) + 1 ;
二叉树层序遍历 我的做法:先序遍历(root,左,右)的时候记住 depth 存到 map 中,然后最后把 map 中的数组组合起来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {new ArrayList <>();new HashMap <>();public List<List<Integer>> levelOrder (TreeNode root) {int depth = helper(root, 0 );for (int i = 0 ; i < depth; i++) {return ans;private int helper (TreeNode root, int depth) {if (root == null ) return depth;new ArrayList <Integer>());int leftMax = helper(root.left, depth + 1 );int rightMax = helper(root.right, depth + 1 );return Math.max(leftMax, rightMax);
bfs 做法:
root 入队列
队列不为空的时候
求当前队列长度 $s_i$
取 $s_i$ 个元素进行拓展,进入下一次迭代
它和普通广度优先搜索的区别在于,普通广度优先搜索每次只取一个元素拓展,而这里每次取 $s_i$ 个元素。在上述过程中的第 $i$ 次迭代得到了二叉树第 $i$ 层的 $s_i$ 个元素。(说白了就是每次迭代的时候把下一层级的所有元素都加到队列里面,这样每一次迭代整个队列元素的时候就是一个层级的所有元素)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public List<List<Integer>> levelOrder (TreeNode root) {new ArrayList <>();if (root == null ) return ans;new LinkedList <>();while (!queue.isEmpty()) {new ArrayList <>();int size = queue.size();for (int i = 0 ; i < size; i++) {TreeNode front = queue.poll();if (front.left != null ) queue.offer(front.left);if (front.right != null ) queue.offer(front.right);return ans;
将有序数组转换为二叉搜索树 递归建树:
1 <= nums.length <= 10^4-10^4 <= nums[i] <= 10^4nums 按 严格递增 顺序排列
image-20250205185730436
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public TreeNode sortedArrayToBST (int [] nums) {return helper(nums, 0 , nums.length);private TreeNode helper (int [] nums, int left, int right) {if (left >= right) return null ;int mid = left + (right - left) / 2 ;TreeNode root = new TreeNode (nums[mid]);1 , right);return root;
验证二叉搜索树 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
节点的左子树只包含 小于 当前节点的数。
节点的右子树只包含 大于 当前节点的数。
所有左子树和右子树自身必须也是二叉搜索树。
这里有一个问题是需要判断所有的子节点都大于或者都小于根节点。
二叉搜索树的中序遍历是递增的。 所以可以中序遍历,之后每个元素都小于前一个元素,则是二叉搜索树。
递归写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {new ArrayList <>();public boolean isValidBST (TreeNode root) {for (int i = 0 ; i < list.size() - 1 ; i++) {if (list.get(i) >= list.get(i + 1 )) {return false ;return true ;private void helper (TreeNode root) {if (root == null ) return ;
递归写法2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {long left = Long.MIN_VALUE;public boolean isValidBST (TreeNode root) {return helper(root);private boolean helper (TreeNode root) {if (root == null ) return true ;boolean l = helper(root.left);boolean tmp = left < root.val;boolean r = helper(root.right);return l && r && tmp;
递归写法3:
1 2 3 4 5 6 7 8 9 10 11 class Solution {public boolean isValidBST (TreeNode root) {return helper(root, Long.MIN_VALUE, Long.MAX_VALUE);private boolean helper (TreeNode root, long lower, long upper) {if (root == null ) return true ;if (root.val <= lower || root.val >= upper) return false ;return helper(root.left, lower, root.val) && helper(root.right, root.val, upper);
迭代写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public boolean isValidBST (TreeNode root) {return helper(root);private boolean helper (TreeNode root) {new LinkedList <TreeNode>();long left = Long.MIN_VALUE;while (root != null || !stack.isEmpty()) {while (root != null ) {if (left >= root.val) return false ;return true ;
二叉搜索树中第 K 小的元素 和验证二叉搜索树一样,在最外层存储一下状态。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {int count = 0 , target; public int kthSmallest (TreeNode root, int k) {return helper(root);private int helper (TreeNode root) {if (root == null ) return -1 ; int left = helper(root.left);if (left != -1 ) return left;if (target == count) {return root.val;int right = helper(root.right);if (right != -1 ) return right;return -1 ;
二叉树的右视图 给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
层序遍历中最右面的那个元素就是答案,放进去就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public List<Integer> rightSideView (TreeNode root) {new ArrayList <>();if (root == null ) return ans;new LinkedList <>();while (!queue.isEmpty()) {int size = queue.size();for (int i = 0 ; i < size; i++) {TreeNode node = queue.poll();if (node.left != null ) queue.offer(node.left);if (node.right != null ) queue.offer(node.right);if (i == size - 1 ) {return ans;
二叉树展开为链表 给你二叉树的根结点 root ,请你将它展开为一个单链表:
展开后的单链表应该同样使用 TreeNode ,其中 right 子指针指向链表中下一个结点,而左子指针始终为 null 。
展开后的单链表应该与二叉树 先序遍历
递归 先序遍历二叉树,然后记录 last,然后修改 last 的 left 和 right,但是这样会栈溢出。
原因是递归遍历 root.left 的时候,root.right 被改成了 root.left 导致死循环,保存一下状态就好了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {private TreeNode last;public void flatten (TreeNode root) {new TreeNode (0 , null , root);private void helper (TreeNode root) {if (root == null ) return ;TreeNode left = root.left;TreeNode right = root.right;null ;
迭代1 迭代写法,这里注意是第三种先序遍历的方法(递归,迭代1,迭代2),注意先入栈右边再入左边,保证左边先处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public void flatten (TreeNode root) {private void helper (TreeNode root) {if (root == null ) return ;TreeNode last = new TreeNode (0 , null , root);new LinkedList <>();while (!stack.isEmpty()) {TreeNode top = stack.poll();null ;if (top.right != null ) stack.push(top.right);if (top.left != null ) stack.push(top.left);
迭代2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public void flatten (TreeNode root) {private void helper (TreeNode root) {while (root != null ) {if (root.left != null ) {TreeNode next = root.left;TreeNode pre = next;while (pre.right != null ) {null ;
路径总和 III
二叉树的节点个数的范围是 [0,1000]
-10^9 <= Node.val <= 10^9 -1000 <= targetSum <= 1000
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
穷举 O(N^2) 访问每一个节点 node ,检测以 node 为起始节点且向下延深的路径有多少种。我们递归遍历每一个节点的所有可能的路径,然后将这些路径数目加起来即为返回结果。
定义 helper(p, val) 表示以 p 为起点向下满足和为 val 的路径数目。对每个节点 p 求出 helper(p, targetSum) 就是答案。
helper 的实现为
1 2 3 4 5 6 7 8 private int helper (TreeNode root, long targetSum) {int ret = 0 ;if (root == null ) return 0 ;if (root.val == targetSum) ret++;return ret;
接下来是对于每个节点都进行 helper,这里先 dfs 遍历所有节点,并对所有节点进行 helper 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public int pathSum (TreeNode root, long targetSum) {return dfs(root, targetSum);private int dfs (TreeNode root, long targetSum) {if (root == null ) return 0 ;int ret = 0 ;return ret;private int helper (TreeNode root, long targetSum) {int ret = 0 ;if (root == null ) return 0 ;if (root.val == targetSum) ret++;return ret;
前缀和优化 O(N) 我们定义节点的前缀和为:由根结点到当前结点的路径上所有节点的和。
我们利用先序遍历二叉树,记录下根节点 root 到当前节点 p 的路径上除当前节点以外所有节点的前缀和,在已保存的路径前缀和中查找是否存在前缀和刚好等于当前节点到根节点的前缀和 cur 减去 targetSum。
如果 (cur - targetSum) 存在,那么 cur - (cur - targetSum) = targetSum 也存在,就是从某个路径到当前节点的和为 targetSum。
key保存前缀和,value保存对应此前缀和的数量。
然后总体的思路和 560 是一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public int pathSum (TreeNode root, int targetSum) {new HashMap <Long, Integer>();0L , 1 );return dfs(root, prefix, 0L , targetSum);private int dfs (TreeNode root, Map<Long, Integer> prefix, long cur, int targetSum) {if (root == null ) return 0 ;int ret = 0 ;0 );0 ) + 1 );0 ) - 1 );return ret;
二叉树的最近公共祖先 暴力递归做法 每个节点判断是不是子节点是不是同时包含 p 和 q
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) {return dfs(root, p, q);private TreeNode dfs (TreeNode root, TreeNode p, TreeNode q) {if (root == p || root == q) return root;if (check(root.left, p, q) && check(root.right, p, q)) return root;if (check(root.right, p, q) == false ) return dfs(root.left, p, q);return dfs(root.right, p, q);private boolean check (TreeNode root, TreeNode p, TreeNode q) {if (root == null ) return false ;if (root == p || root == q) return true ;return check(root.left, p, q) || check(root.right, p, q);
改进递归做法
如果要找的节点只在左子树中,那么最近公共祖先也只在左子树中。
如果要找的节点只在右子树中,那么最近公共祖先也只在右子树中。
如果要找的节点左右子树都有,那么最近公共祖先就是当前节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) {return dfs(root, p, q);private TreeNode dfs (TreeNode root, TreeNode p, TreeNode q) {if (root == null ) return null ;if (root == p || root == q) return root;TreeNode left = dfs(root.left, p, q);TreeNode right = dfs(root.right, p, q);if (left == null ) return right; if (right == null ) return left; if (left != null && right != null ) return root;return null ;
记录父节点的做法 用哈希表记录每个 TreeNode 的父节点,然后遍历 p 的父节点和 q 的父节点,最先出现的那个就是最近公共祖先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {private HashMap<TreeNode, TreeNode> map = new HashMap <>();private Set<TreeNode> set = new HashSet <>();private void dfs (TreeNode root) {if (root == null ) return ;if (root.left != null ) {if (root.right != null ) {public TreeNode lowestCommonAncestor (TreeNode root, TreeNode p, TreeNode q) {while (p != null ) {while (q != null ) {if (set.contains(q)) return q;return null ;
二叉树中的最大路径和 与二叉树最大直径有异曲同工之妙。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {private int ans = Integer.MIN_VALUE;public int maxPathSum (TreeNode root) {return ans;private int helper (TreeNode root) {if (root == null ) return 0 ;int leftMax = Math.max(helper(root.left), 0 );int rightMax = Math.max(helper(root.right), 0 );return root.val + Math.max(leftMax, rightMax);
最深叶节点的最近公共祖先 暴力递归 先找到最深叶节点,然后找最近公共祖先
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 class Solution {new HashMap <>();public TreeNode lcaDeepestLeaves (TreeNode root) {0 );null ;int deep = 0 ;for (Map.Entry<Integer, List<TreeNode>> entry : deepMap.entrySet()) {if (entry.getKey() >= deep) {return MergeLCA(root, deepestNodes, 0 , deepestNodes.size() - 1 );private TreeNode ArrayLCA (TreeNode root, List<TreeNode> list) {TreeNode ans = list.get(0 );for (int i = 1 ; i < list.size(); i++) {return ans;private TreeNode MergeLCA (TreeNode root, List<TreeNode> list, int left, int right) {if (right - left == 0 ) return list.get(left);if (right - left == 1 ) {return LCA(root, list.get(left), list.get(right));if (right - left > 1 ) {int mid = left + (right - left) / 2 ;return LCA(root, MergeLCA(root, list, left, mid - 1 ), MergeLCA(root, list, mid + 1 , right));return null ;private void deepestNodes (TreeNode root, int deep) {if (root == null ) return ;new ArrayList <>());1 );1 );private TreeNode LCA (TreeNode root, TreeNode p, TreeNode q) {if (root == null ) return null ;if (root == p || root == q) return root;TreeNode left = LCA(root.left, p, q);TreeNode right = LCA(root.right, p, q);if (left == null ) return right; if (right == null ) return left; if (left != null && right != null ) return root;return null ;
改进的递归
从根节点开始递归,同时维护全局最大深度 deepMax。
在「递」的时候往下传 depth,用来表示当前节点的深度。
在「归」的时候往上传当前子树最深的空节点的深度。这里为了方便,用空节点代替叶子,因为最深的空节点的上面一定是最深的叶子。
设左子树最深空节点的深度为 leftMax,右子树最深空节点的深度为 rightMax。如果最深的空节点左右子树都有,也就是 leftMax=rightMax=deepMax,那么更新答案为当前节点。注意这并不代表我们找到了答案,如果后面发现了更深的空节点,答案还会更新。另外注意,这个判断方式在只有一个最深叶子的情况下,也是正确的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {int deepMax = 0 ;TreeNode ans = null ;public TreeNode lcaDeepestLeaves (TreeNode root) {0 );return ans;private int dfs (TreeNode root, int deep) {if (root == null ) {return deep;int leftMax = dfs(root.left, deep + 1 );int rightMax = dfs(root.right, deep + 1 );if (leftMax == deepMax && rightMax == deepMax) { return Math.max(leftMax, rightMax);
图论 岛屿数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {private int count = 0 ;private boolean [][] visited;private int [][] dirs = {0 , 1 },0 , -1 },1 , 0 },1 , 0 }public int numIslands (char [][] grid) {int m = grid.length;int n = grid[0 ].length;new boolean [m][n];for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {if (!visited[i][j] && grid[i][j] == '1' ) {return count;private void dfs (char [][] grid, int x, int y) { true ;for (int i = 0 ; i < 4 ; i++) { int dirX = dirs[i][0 ], dirY = dirs[i][1 ];int m = grid.length;int n = grid[0 ].length;int newX = x + dirX, newY = y + dirY;if (newX >= 0 && newX < m && newY >= 0 && newY < n && !visited[newX][newY] && grid[newX][newY] == '1' ) {true ;
腐烂的橘子 单源 bfs 不要改动橘子矩阵,新增一个时间矩阵表示橘子的情况。
bfs,如果时间更小则更新时间矩阵。
这个是单源 bfs,需要对于每个腐烂的橘子都进行 bfs。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class Solution {private boolean [][] visited;private int [][] dirs = {1 , 0 },1 , 0 },0 , 1 },0 , -1 },private int m, n;public int orangesRotting (int [][] grid) {0 ].length;new boolean [m][n];new int [m][n];for (int [] row : allTime) {0x3f3f3f3f );for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {int maxTime = 0 ;for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {if (grid[i][j] != 0 && allTime[i][j] == 0x3f3f3f3f ) { return -1 ;else if (grid[i][j] > 0 && allTime[i][j] != 0x3f3f3f3f ) {return maxTime;private void bfs (int [][] grid, int row, int col) {if (grid[row][col] != 2 ) return ; int []> queue = new LinkedList <>();new int []{row, col, 0 });0 ;true ;while (!queue.isEmpty()) {int [] pos = queue.poll();for (int i = 0 ; i < 4 ; i++) {if (pos[2 ] == 0x3f3f3f3f ) continue ; int newRow = dirs[i][0 ] + pos[0 ];int newCol = dirs[i][1 ] + pos[1 ];int newTime = 1 + pos[2 ];if (ok(newRow, newCol, newTime) && grid[newRow][newCol] > 0 ) {new int []{newRow, newCol, newTime});true ;private boolean ok (int row, int col, int time) {return row >= 0 && row < m && col >= 0 && col < n && (!visited[row][col] || time < allTime[row][col]);
多源 bfs 把所有腐烂的橘子都放到队列里面,进行多源 bfs,这样就不用每个腐烂橘子都 bfs 了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Solution {private boolean [][] visited;private int [][] dirs = {1 , 0 },1 , 0 },0 , 1 },0 , -1 },private int m, n;int []> queue = new LinkedList <>();public int orangesRotting (int [][] grid) {0 ].length;new boolean [m][n];new int [m][n];for (int [] row : allTime) {0x3f3f3f3f );for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {if (grid[i][j] == 2 ) {new int []{i, j, 0 });0 ;true ;int maxTime = 0 ;for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {if (grid[i][j] != 0 && allTime[i][j] == 0x3f3f3f3f ) { return -1 ;else if (grid[i][j] > 0 && allTime[i][j] != 0x3f3f3f3f ) {return maxTime;private void bfs (int [][] grid) {while (!queue.isEmpty()) {int [] pos = queue.poll();for (int i = 0 ; i < 4 ; i++) {int newRow = dirs[i][0 ] + pos[0 ];int newCol = dirs[i][1 ] + pos[1 ];int newTime = 1 + pos[2 ];if (ok(newRow, newCol, newTime) && grid[newRow][newCol] > 0 ) {new int []{newRow, newCol, newTime});true ;private boolean ok (int row, int col, int time) {return row >= 0 && row < m && col >= 0 && col < n && (!visited[row][col] || time < allTime[row][col]);
Trie 树 HashMap 实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Trie {new HashMap <>();new HashMap <>();public Trie () {public void insert (String word) {for (int i = 1 ; i <= word.length(); i++) {0 , i), true );true );public boolean search (String word) {return map.containsKey(word);public boolean startsWith (String prefix) {return prefixMap.containsKey(prefix);
正常实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Trie {class TrieNode {new HashMap <>();boolean isEnd = false ;public TrieNode () {public Trie () {new TrieNode ();public void insert (String word) {TrieNode node = root;for (char ch : word.toCharArray()) {new TrieNode ());true ;public boolean search (String word) {TrieNode node = root;for (char ch : word.toCharArray()) {if (node == null ) return false ;return node.isEnd;public boolean startsWith (String prefix) {TrieNode node = root;for (char ch : prefix.toCharArray()) {if (node == null ) return false ;return true ;
课程表
1 <= numCourses <= 20000 <= prerequisites.length <= 5000
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
例如,先修课程对 [0, 1] 表示:想要学习课程 0 ,你需要先完成课程 1 。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
像是要检测并完成图中是否有环?
拓扑排序的经典题?
我们将每一门课看成一个节点;
如果想要学习课程A之前必须完成课程B,那么我们从B到A连接一条有向边。这样以来,在拓扑排序中,B一定出现在A的前面。
求出该图是否存在拓扑排序,就可以判断是否有一种符合要求的课程学习顺序。事实上,由于求出一种拓扑排序方法的最优时间复杂度为O(n+m),其中n和m分别是有向图G的节点数和边数,方法见210. 课程表 II 的官方题解。而判断图G是否存在拓扑排序,至少也要对其进行一次完整的遍历,时间复杂度也为O(n+m)。因此不可能存在一种仅判断图是否存在拓扑排序的方法,它的时间复杂度在渐进意义上严格优于O(n+m)。这样一来,我们使用和210. 课程表 II完全相同的方法,但无需使用数据结构记录实际的拓扑排序。为了叙述的完整性,下面的两种方法与210. 课程表 II 的官方题解完全相同,但在「算法」部分后的「优化」部分说明了如何省去对应的数据结构。
代码与下面的 课程表 II 相同,如果存在拓扑排序就是 true。
课程表 II BFS 拓扑排序,bfs 思路,找入度为 0 的节点,放到队列和 ans 里面,并把 uv 的 v 节点的入度减一,并检测有哪些节点的入度为 0,继续放入队列中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {int [] indeg;int [] ans;int index = 0 ;public int [] findOrder(int numCourses, int [][] prerequisites) {new ArrayList <>();new int [numCourses];new int [numCourses]; new LinkedList <>();for (int i = 0 ; i < numCourses; i++) {new ArrayList <Integer>());for (int [] req : prerequisites) {1 ]).add(req[0 ]);0 ]]++;for (int i = 0 ; i < numCourses; i++) {if (indeg[i] == 0 ) {while (!queue.isEmpty()) {int first = queue.poll();for (int i = 0 ; i < v.size(); i++) {if (indeg[v.get(i)] == 0 ) {if (index < numCourses) return new int [0 ];else return ans;
回溯 回溯法就是暴力搜索,并不是什么高效的算法,最多再剪枝一下。
回溯算法能解决如下问题:
组合问题:N个数里面按一定规则找出k个数的集合
排列问题:N个数按一定规则全排列,有几种排列方式
切割问题:一个字符串按一定规则有几种切割方式
子集问题:一个N个数的集合里有多少符合条件的子集
棋盘问题:N皇后,解数独等等
模板框架:
1 2 3 4 5 6 7 8 9 10 11 12 void backtracking (参数) {if (终止条件) {return ;for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
全排列 主要就是回溯前后的状态的更新和恢复
还有要想清楚选定了某个元素之后,剩余的选择的范围是哪些。
对于全排列来说是选定了元素之后,这个元素不能再选。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {private int n;private boolean [] visited;private List<List<Integer>> ans;private List<Integer> tmp;public List<List<Integer>> permute (int [] nums) {new boolean [n];new ArrayList <>();new ArrayList <>();0 );return ans;private void dfs (int [] nums, int times) {if (times == n) {new ArrayList <>(tmp));return ;for (int i = 0 ; i < n; i++) {if (!visited[i]) {true ;1 );false ;1 );
子集 给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
DFS 要点在于思考选择了第一个元素,比如 [1] 之后,后续的选择就不能再选 1 了。
选了 [1, 2] 就不能有 [2, 1] 了。所以要点在于选元素的时候,候选项是下标大于自己的元素里面。
所以注意 dfs 的第二个参数是 start + 1 而不是 i + 1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {private List<List<Integer>> ans = new ArrayList <>();private boolean [] visited;new ArrayList <>();public List<List<Integer>> subsets (int [] nums) {int n = nums.length;new boolean [n];0 );return ans;private void dfs (int [] nums, int start) {new ArrayList <>(tmp));for (int i = start; i < nums.length; i++) {if (!visited[i]) {true ;1 );false ;1 );
位操作 例如,n=3,a={5,2,9}时:
0/1序列 子集 0/1序列对应的二进制数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public List<List<Integer>> subsets (int [] nums) {int n = nums.length;new ArrayList <>();for (int i = 0 ; i < (1 << n); i++) {new ArrayList <>();for (int j = 0 ; j < n; j++) {if ((i & (1 << j)) != 0 ) {return ans;
电话号码的数字组合 迭代 for 套 for,第一个 for 找上一层的号码,第二个 for 根据上一层加新的号码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution {char []> map = new HashMap <>();new ArrayList <>();public List<String> letterCombinations (String digits) {if (digits.length() == 0 ) return new ArrayList <String>();'2' , new char []{'a' , 'b' , 'c' });'3' , new char []{'d' , 'e' , 'f' });'4' , new char []{'g' , 'h' , 'i' });'5' , new char []{'j' , 'k' , 'l' });'6' , new char []{'m' , 'n' , 'o' });'7' , new char []{'p' , 'q' , 'r' , 's' });'8' , new char []{'t' , 'u' , 'v' });'9' , new char []{'w' , 'x' , 'y' , 'z' });for (int digitsIndex = 0 ; digitsIndex < digits.length(); digitsIndex++) {char [] res = map.get(digits.charAt(digitsIndex));if (digitsIndex == 0 ) {new ArrayList <>();for (char c : res) {else {1 );new ArrayList <>();int size = old.size();for (char c : res) {for (int i = 0 ; i < size; i++) {return ans.get(ans.size() - 1 );
递归 要点在于转换为子问题,只需要上一层的状态即可。要点在于 dfs(i) 表示第 i 个字母对应的答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {char []> map = new HashMap <>();new ArrayList <>();public List<String> letterCombinations (String digits) {if (digits.length() == 0 ) return new ArrayList <String>();'2' , new char []{'a' , 'b' , 'c' });'3' , new char []{'d' , 'e' , 'f' });'4' , new char []{'g' , 'h' , 'i' });'5' , new char []{'j' , 'k' , 'l' });'6' , new char []{'m' , 'n' , 'o' });'7' , new char []{'p' , 'q' , 'r' , 's' });'8' , new char []{'t' , 'u' , 'v' });'9' , new char []{'w' , 'x' , 'y' , 'z' });return dfs(digits, new ArrayList <String>(), 0 );private List<String> dfs (String digits, List<String> lastAns, int times) {if (times < digits.length()) {new ArrayList <>();char [] chars = map.get(digits.charAt(times));if (lastAns.size() != 0 ) {for (int i = 0 ; i < lastAns.size(); i++) {for (char ch : chars) {else {for (char ch : chars) {"" + ch);return dfs(digits, ans, times + 1 );else {return lastAns;
组合总数 要点:
ans.add(new ArrayList<>(tmp)); 添加的是 tmp 的 clone。dfs(candidates, target - num, i); 第三个参数是 i ,而不是 start + 1,既可以保证选到相同的数字,又保证没有同一种的不同组合。比如 [3, 5] 和 [5, 3]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {private List<List<Integer>> ans = new ArrayList <>();private List<Integer> tmp = new ArrayList <>();public List<List<Integer>> combinationSum (int [] candidates, int target) {0 );return ans;private void dfs (int [] candidates, int target, int start) {if (target < 0 ) return ;if (target == 0 ) {new ArrayList <>(tmp));return ;for (int i = start; i < candidates.length; i++) {int num = candidates[i];1 );
括号生成 要点:
候选为 ( 和 ),候选的个数为 n。每次应该可以从候选中任意选择。
选择之后添加到 tmp,然后继续递归,之后要删除 tmp 中添加的内容。
right 要在 left 之后才能被选择,所以放 right 的时候要确认可以选的 right > left。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {private List<String> ans = new ArrayList <>();private StringBuilder sb = new StringBuilder ();public List<String> generateParenthesis (int n) {return ans;private void dfs (int left, int right) {if (left == 0 && right == 0 ) {return ;if (left > 0 ) {'(' );1 , right);1 , sb.length());if (right > 0 && right > left) {')' );1 );1 , sb.length());
单词搜索 要点:
不允许重复使用,所以要使用 visited 数组。
回溯记得设置 visited 为 false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Solution {private int m, n;private boolean [][] visited;private int [][] dirs = new int [][]{1 , 0 },1 , 0 },0 , 1 },0 , -1 }public boolean exist (char [][] board, String word) {0 ].length;new boolean [m][n];for (int i = 0 ; i < m; i++) {for (int j = 0 ; j < n; j++) {if (board[i][j] == word.charAt(0 )) {if (1 == word.length()) return true ;true ;if (dfs(board, word, 1 , i, j)) return true ;false ;return false ;private boolean dfs (char [][] board, String word, int start, int row, int col) {for (int i = 0 ; i < 4 ; i++) {int [] dir = dirs[i];int newRow = row + dir[0 ];int newCol = col + dir[1 ];if (check(board, newRow, newCol, word.charAt(start))) { if (start == word.length() - 1 ) return true ; true ;boolean res = dfs(board, word, start + 1 , newRow, newCol);false ;if (res) return true ;return false ;private boolean check (char [][] board, int row, int col, char need) {return row >= 0 && row < m && col >= 0 && col < n && !visited[row][col] && need == board[row][col];
分割回文串 要点:
不管是递归还是 dp,重要的都是划分子问题,用 dp[i][j] 表示。
这里是枚举所有的分割方法,然后判断是不是回文字符串。枚举可以用回溯法,判断可以使用 dp 等方法进行优化。
枚举要有条理的枚举,比如从 i 开始,一直枚举到结尾,然后下次从 i + 1 再到结尾。
数据很弱,直接回溯都能过。
直接回溯 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {new ArrayList <>();new ArrayList <>();int n;public List<List<String>> partition (String s) {0 );return ans;private void dfs (String s, int start) {if (start == n) {new ArrayList <>(tmp));return ;for (int i = start + 1 ; i <= n; i++) {String sub = s.substring(start, i);if (check(sub)) { 1 );private boolean check (String s) {int left = 0 , right = s.length() - 1 ;while (left < right) {if (s.charAt(left) != s.charAt(right)) {return false ;return true ;
回溯 + dp 其实就是用 dp 记录一下哪些情况是回文字符串,这样就不用重复判断了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Solution {new ArrayList <>();new ArrayList <>();boolean [][] dp;int n;public List<List<String>> partition (String s) {0 );return ans;private void initDp (String s) {new boolean [n + 1 ][n + 1 ]; for (int i = 0 ; i < n; i++) {true ; for (int i = 0 ; i < n - 1 ; i++) {if (s.charAt(i) == s.charAt(i + 1 )) {1 ] = true ; for (int i = n - 2 ; i >= 0 ; i--) {for (int j = i + 1 ; j < n; j++) {if (dp[i + 1 ][j - 1 ] && s.charAt(i) == s.charAt(j))true ;private void dfs (String s, int start) {if (start == n) {new ArrayList <>(tmp));return ;for (int i = start + 1 ; i <= n; i++) {String sub = s.substring(start, i);if (dpCheck(start, i - 1 )) { 1 );private boolean dpCheck (int start, int end) {return dp[start][end];private boolean check (String s) {int left = 0 , right = s.length() - 1 ;while (left < right) {if (s.charAt(left) != s.charAt(right)) {return false ;return true ;
记忆化递归 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Solution {new ArrayList <>();new ArrayList <>();int [][] dp;int n;public List<List<String>> partition (String s) {new int [n][n];0 );return ans;private void dfs (String s, int start) {if (start == n) {new ArrayList <>(tmp));return ;for (int i = start + 1 ; i <= n; i++) {String sub = s.substring(start, i);if (memoryCheck(s, start, i - 1 ) == 1 ) { 1 );private int memoryCheck (String s, int i, int j) {if (dp[i][j] != 0 ) return dp[i][j]; if (i >= j) dp[i][j] = 1 ;else if (s.charAt(i) == s.charAt(j)) {1 , j - 1 );else {1 ;return dp[i][j];private boolean check (String s) {int left = 0 , right = s.length() - 1 ;while (left < right) {if (s.charAt(left) != s.charAt(right)) {return false ;return true ;
二分查找 搜索插入位置 左闭右闭 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int searchInsert (int [] nums, int target) {int left = 0 ;int right = nums.length - 1 ;int mid = 0 ;while (left <= right) {2 ;if (nums[mid] == target) return mid;else if (nums[mid] > target) {1 ;else {1 ;return left;
左闭右开 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int searchInsert (int [] nums, int target) {int left = 0 ;int right = nums.length;int mid = 0 ;while (left < right) {2 ;if (nums[mid] == target) return mid;else if (nums[mid] > target) {else {1 ;return left;
搜索二维矩阵 先在所有行中二分搜索第一个元素,然后在确定的某一行中搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public boolean searchMatrix (int [][] matrix, int target) {int left = 0 ;int right = matrix.length;int mid = 0 ;while (left < right) {2 ;if (matrix[mid][0 ] == target) {return true ;else if (matrix[mid][0 ] > target) {else {1 ;int row = 0 ;if (left > 0 ) row = left - 1 ;else row = left;0 ;0 ].length;while (left < right) {2 ;if (matrix[row][mid] == target) return true ;else if (matrix[row][mid] > target) {else {1 ;return false ;
在排序数组中查找元素的第一个和最后一个位置 一个搜索 lower bound,另一个 upper bound,搜索 lower bound 是等于 target 的时候设置 ans[0] = mid 并且 right = mid;upper bound 是等于 target 的时候设置ans[1] = mid 并且 left = mid + 1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public int [] searchRange(int [] nums, int target) {int left = 0 ;int right = nums.length;int mid;int [] ans = new int []{-1 , -1 };while (left < right) {2 ;if (nums[mid] == target) {0 ] = mid;else if (nums[mid] < target) {1 ;else {0 ;while (left < right) {2 ;if (nums[mid] == target) {1 ] = mid;1 ;else if (nums[mid] < target) {1 ;else {return ans;
搜索旋转排序数组 对一个旋转后的数组进行切分,总会切分成两部分,两部分中必定有一部分是顺序的,另一部分是乱序的,对于顺序的进行二分搜索,对于乱序的继续切分。
然后还要注意,判断在顺序部分的时候,nums[left] 和 target 的比较得是 <= ,否则无法处理 nums = [1, 3], target = 1 的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public int search (int [] nums, int target) {int left = 0 ;int right = nums.length;int mid;while (left < right) {2 ;if (nums[mid] == target) return mid;if (nums[left] < nums[mid]) { if (nums[left] <= target && target < nums[mid]) { else { 1 ;else { if (nums[mid] < target && target <= nums[right - 1 ]) { 1 ;else {return -1 ;
寻找旋转排序数组中的最小值 搜索旋转排序数组的简化版本,无论在哪里分隔,都是有序和无序部分,有序部分取最小值,然后继续去无序部分继续搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int findMin (int [] nums) {int left = 0 ;int right = nums.length;int mid;int min = nums[0 ];while (left < right) {2 ;if (nums[left] < nums[mid]) { 1 ;else { return min;
寻找两个正序数组的中位数 这道题的关键在于对中位数的理解,一个数组的中位数是能够将数组分为两部分的数,且左边部分的最大值小于右边部分最小值。
对于两个数组的情况:
image-20250227154454826
第一个条件:左边元素个数和右边相等或左边多一个 然后分割线左边元素个数和右边元素个数是可以被计算的,假设长度为 m 和 n,当 m + n 为偶数时,左边元素个数 = 右边元素个数 = (m + n) / 2。
当 m + n 为奇数时,假设中位数在左边,于是 左边元素个数 = (m + n + 1) / 2。
又偶数的时候,(m + n + 1) / 2 = (m + n) / 2,因为默认是向下取整。所以统一成了 左边元素个数 = (m + n + 1) / 2。
第二个条件:分割线左边最大元素 <= 分割线右边最大元素 对于两个数组的情况下:
第一个数组的分割线左边最大值 <= 第二个数组的分割线右边最小值
第二个数组的分割线左边最大值 <= 第一个数组的分割线右边最小值
如果不满足上面的情况,就要进行调整。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public double findMedianSortedArrays (int [] nums1, int [] nums2) {if (nums1.length > nums2.length) return findMedianSortedArrays(nums2, nums1);int m = nums1.length, n = nums2.length;int left = 0 , right = m;int median1 = 0 , median2 = 0 ;while (left <= right) {int i = left + (right - left) / 2 ;int j = (m + n + 1 ) / 2 - i;int nums_i_minus_1 = (i == 0 ? Integer.MIN_VALUE : nums1[i - 1 ]);int nums_i_add_1 = (i == m ? Integer.MAX_VALUE : nums1[i]); int nums_j_minus_1 = (j == 0 ? Integer.MIN_VALUE : nums2[j - 1 ]);int nums_j_add_1 = (j == n ? Integer.MAX_VALUE : nums2[j]); if (nums_i_minus_1 > nums_j_add_1) {1 ;else {1 ;return (m + n) % 2 == 0 ? (median1 + median2) / 2.0 : median1;
统计公平数对的数目 给你一个下标从 0 开始、长度为 n 的整数数组 nums ,和两个整数 lower 和 upper ,返回 公平数对的数目 。
如果 (i, j) 数对满足以下情况,则认为它是一个 公平数对 :
0 <= i < j < n,且lower <= nums[i] + nums[j] <= upper
由于排序不影响答案,可以先(从小到大)排序,这样可以二分查找。
nums 是 [1,2] 还是 [2,1],算出来的答案都是一样的,因为加法满足交换律 $a + b = b + a$。
排序后,枚举右边的 nums[j],那么左边的 nums[i] 需要满足 $0 \leq i < j$ 以及
计算 $\leq upper - nums[j]$ 的元素个数,减去 $< lower - nums[j]$ 的元素个数,即为满足上式的元素个数。(联想一下前缀和)
由于 nums 是有序的,我们可以在 $[0, j - 1]$ 中二分查找,原理见【基础算法精讲 04】:
找到 $> upper - nums[j]$ 的第一个数,设其下标为 $r$,那么下标在 $[0, r - 1]$ 中的数都是 $\leq upper - nums[j]$ 的,这有 $r$ 个。如果 $[0, j - 1]$ 中没有找到这样的数,那么二分结果为 $j$。这意味着 $[0, j - 1]$ 中的数都是 $\leq upper - nums[j]$ 的,这有 $j$ 个。
找到 $\geq lower - nums[j]$ 的第一个数,设其下标为 $l$,那么下标在 $[0, l - 1]$ 中的数都是 $< lower - nums[j]$ 的,这有 $l$ 个。如果 $[0, j - 1]$ 中没有找到这样的数,那么二分结果为 $j$。这意味着 $[0, j - 1]$ 中的数都是 $< lower - nums[j]$ 的,这有 $j$ 个。
满足 $lower - nums[j] \leq nums[i] \leq upper - nums[j]$ 的 nums[i] 的个数为 $r - l$,加入答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public long countFairPairs (int [] nums, int lower, int upper) {long ans = 0 ;for (int j = 0 ; j < nums.length; j++) {int r = lowerBound(nums, j, upper - nums[j] + 1 );int l = lowerBound(nums, j, lower - nums[j]);return ans;private int lowerBound (int [] nums, int right, int target) {int left = -1 ;while (left + 1 < right) {int mid = (left + right) >>> 1 ;if (nums[mid] >= target) {else {return right;
栈 有效的括号 判断右括号的时候栈顶能不能匹配就好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public boolean isValid (String s) {new LinkedList <>();for (int i = 0 ; i < s.length(); i++) {if (s.charAt(i) == '(' ) {'(' );else if (s.charAt(i) == '{' ) {'{' );else if (s.charAt(i) == '[' ) {'[' );else if (s.charAt(i) == ')' && (stack.size() == 0 || stack.pop() != '(' )) {return false ;else if (s.charAt(i) == '}' && (stack.size() == 0 || stack.pop() != '{' )) {return false ;else if (s.charAt(i) == ']' && (stack.size() == 0 || stack.pop() != '[' )) {return false ;return stack.size() == 0 ;
最小栈 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
要点在于增加一个栈,和用的栈同步 push 和 pop 数据,只不过 push 的时候 push 进去当前的最小值,pop 的时候同步 pop。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class MinStack {public MinStack () {new LinkedList <>();new LinkedList <>();public void push (int val) {if (minStack.size() == 0 ) {else {public void pop () {public int top () {return stack.peek();public int getMin () {return minStack.peek();
字符串解码 给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
1 2 输入:s = "3[a]2[bc]" "aaabcbc"
要点:
括号的处理,看到左括号右括号,要想到用栈来解决。
括号前是数字就解析为数字
括号前为字母就加进来
括号中的内容要用解析的数字进行一个重复
记得清空 sb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public String decodeString (String s) {new LinkedList <>();new LinkedList <>();int multi = 0 ;StringBuilder sb = new StringBuilder ();for (char ch : s.toCharArray()) {if (ch == '[' ) {0 ;new StringBuilder ();else if (ch == ']' ) {int times = numStack.pop();StringBuilder tmp = new StringBuilder ();for (int i = 0 ; i < times; i++) {new StringBuilder ();else if ('0' <= ch && ch <= '9' ) {10 + (ch - '0' );else {return sb.toString();
每日温度 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0 来代替。
从右向左 要点:单调栈
栈里面存的是当前 index,当新放进来的温度比栈中已有的温度低的时候,新放进来的温度就有答案了。
否则就更新栈。
image-20250301225057849
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Solution {public int [] dailyTemperatures(int [] temperatures) {int [] ans = new int [temperatures.length];new LinkedList <>();for (int i = temperatures.length - 1 ; i >= 0 ; i--) {int temp = temperatures[i];while (!tempStack.isEmpty() && temp >= temperatures[tempStack.peek()]) {if (!tempStack.isEmpty()) {return ans;
从左向右 单调栈内存放的是 index,然后都是新放进去的 index 大,同时只放进去没有更高温度的 index。
当新给的温度比栈顶的温度高的时候,那些温度就都有救了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int [] dailyTemperatures(int [] temperatures) {int n = temperatures.length;int [] ans = new int [n];new LinkedList <>();for (int i = 0 ; i < n; i++) {int temp = temperatures[i];while (!st.isEmpty() && temp > temperatures[st.peek()]) { int j = st.pop();return ans;
柱状图中最大的矩形 image.png
所以这题的关键在于给定一个柱子,找到左边和右边第一个高度小于给定柱子的下标。
暴力做法就是硬找,给定一个柱子,遍历所有的柱子找到高度更小的。找柱子复杂度为 O(n)。
优化做法就是优化如何得到 left[i] 和 right[i]。
left[i] 表示给定第 i 个柱子,左边第一个比他矮的柱子的下标。
right[i] 表示给定第 i 个柱子,右边第一个比他矮的柱子的下标。
求 left[i] 的方法:从左向右,要求的是比当前柱子高度低的柱子,所以用单调栈使得:单调栈内只留下比当前柱子高度更矮的柱子 。然后剩下的这个柱子就是答案。另一种理解方法是:单调栈内比当前柱子高的柱子(更左面更高的柱子)都用不到了
求 right[i] 的方法也是同理:从右向左,要求的是比当前柱子高度低的柱子,所以用单调栈使得:单调栈内只留下比当前柱子高度更矮的柱子 。然后剩下的这个柱子就是答案了。另一种理解方法是:单调栈内比当前柱子高的柱子(更右面更高的柱子)都用不到了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Solution {public int largestRectangleArea (int [] heights) {int n = heights.length;int [] left = new int [n];int [] right = new int [n];new LinkedList <>();for (int i = 0 ; i < n; i++) {int h = heights[i];while (!st.isEmpty() && h <= heights[st.peek()]) { 1 : st.peek();for (int i = n - 1 ; i >= 0 ; i--) {int h = heights[i];while (!st.isEmpty() && h <= heights[st.peek()]) { int ans = 0 ;for (int i = 0 ; i < n; i++) {1 ));return ans;
堆 数组中的第 K 个最大元素 快速选择 O(n) 和快排的思路一致:对于一组数据,选择一个基准元素(base),通常选择第一个或最后一个元素,通过第一轮扫描,比base小的元素都在base左边,比base大的元素都在base右边,再有同样的方法递归排序这两部分,直到序列中所有数据均有序为止。
如果有大量相似的元素,那么要二路快排。否则时间复杂度会退化到 O(n^2)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution {public int findKthLargest (int [] nums, int k) {int n = nums.length;return quickSelect(nums, 0 , n - 1 , n - k);private int quickSelect (int [] nums, int left, int right, int k) {if (left == right) return nums[left];int pivotIndex = partition(nums, left, right);if (k == pivotIndex) {return nums[k];else if (k < pivotIndex) {return quickSelect(nums, left, pivotIndex - 1 , k);else {return quickSelect(nums, pivotIndex + 1 , right, k);private int partition (int [] nums, int left, int right) {int pivot = nums[right];int l = left;int r = right - 1 ;while (l <= r) { while (l <= r && nums[l] < pivot) l++; while (l <= r && pivot < nums[r]) r--; if (l <= r) {return l; private void swap (int [] nums, int i, int j) {int tmp = nums[i];
堆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {public int findKthLargest (int [] nums, int k) {int heapSize = nums.length;for (int i = nums.length - 1 ; i >= nums.length - k + 1 ; --i) {0 , i);0 , heapSize);return nums[0 ];public void buildMaxHeap (int [] a, int heapSize) {for (int i = heapSize / 2 - 1 ; i >= 0 ; --i) {public void maxHeapify (int [] a, int i, int heapSize) {int l = i * 2 + 1 , r = i * 2 + 2 , largest = i;if (l < heapSize && a[l] > a[largest]) {if (r < heapSize && a[r] > a[largest]) {if (largest != i) {public void swap (int [] a, int i, int j) {int temp = a[i];
前 k 个高频元素 遍历一遍并统计频率,并且放到堆里面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public int [] topKFrequent(int [] nums, int k) {int n = nums.length;if (n == k) return nums;int []> queue = new PriorityQueue <>((a, b) -> {return b[0 ] - a[0 ];int count = 1 ;for (int i = 0 ; i < n; i++) {if (i + 1 < n && nums[i] == nums[i + 1 ]) { else {new int []{count, nums[i]});1 ;int [] ans = new int [k];for (int i = 0 ; i < k; i++) {1 ];return ans;
数据流的中位数 要点在于:
用两个堆,一个升序保存比中位数大的数,一个降序保存比中位数小的数
这样中位数就是比中位数大的数中最小的和比中位数小的数中最大的两个数的一半
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class MedianFinder {public MedianFinder () {new PriorityQueue <>((a, b) -> (a - b)); new PriorityQueue <>((a, b) -> (b - a)); public void addNum (int num) {if (ltQueue.isEmpty() || num <= ltQueue.peek()) {if (ltQueue.size() > gtQueue.size() + 1 ) {else {if (gtQueue.size() > ltQueue.size()) {public double findMedian () {if (ltQueue.size() - gtQueue.size() == 1 ) {return ltQueue.peek();return (gtQueue.peek() + ltQueue.peek()) / 2.0 ;
技巧 买卖股票的最佳时机 给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
要点:
在每天都卖,买的价格是已出现的最小值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public int maxProfit (int [] prices) {int ans = 0 ;int n = prices.length;int lowest = prices[0 ];for (int i = 1 ; i < n; i++) {int x = prices[i];if (x < lowest) {else {return ans;
跳跃游戏 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public boolean canJump (int [] nums) {int n = nums.length;new ArrayList <>();for (int i = 0 ; i < n; i++) {if (nums[i] == 0 && i != n - 1 ) { int lastStart = 0 ;for (int i = 0 ; i < list.size(); i++) {boolean ok = false ;for (int j = list.get(i) - 1 ; j >= lastStart; j--) {if (nums[j] > list.get(i) - j) {true ;if (!ok) {return false ;return true ;
官解:判断能跳过去的最大长度是否超过结尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Solution {public boolean canJump (int [] nums) {int n = nums.length;int rightmost = 0 ;for (int i = 0 ; i < n; ++i) {if (i <= rightmost) {if (rightmost >= n - 1 ) {return true ;return false ;
x 的平方根 二分 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public int mySqrt (int x) {int l = 0 , r = x, ans = -1 ;while (l <= r) {int mid = l + (r - l) / 2 ;if ((long ) mid * mid <= x) {1 ;else {1 ;return ans;
转换为对数 对于平方根有以下运算:
$\sqrt{x} = x^{1/2} = \left(e^{\ln x}\right)^{1/2} = e^{\frac{1}{2} \ln x}$
1 2 3 4 5 6 7 8 9 class Solution {public int mySqrt (int x) {if (x == 0 ) {return 0 ;int ans = (int ) Math.exp(0.5 * Math.log(x));return (long ) (ans + 1 ) * (ans + 1 ) <= x ? ans + 1 : ans;
统计隐藏数组数目 给你一个下标从 0 开始且长度为 n 的整数数组 differences ,它表示一个长度为 n + 1 的 隐藏 数组 相邻 元素之间的 差值 。更正式的表述为:我们将隐藏数组记作 hidden ,那么 differences[i] = hidden[i + 1] - hidden[i] 。
image-20250421172529810
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int numberOfArrays (int [] differences, int lower, int upper) {int maxWave = 0 ;int minWave = 0 ;int cur = 0 ;for (int i = 0 ; i < differences.length; i++) {if (maxWave - minWave > upper - lower) {return 0 ;int ans = upper - lower + 1 ; return ans - (maxWave - minWave);
子串 和为 K 的子数组 2 * 10^4 O(n^2) 或者 O(n)
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
前缀和 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public int subarraySum (int [] nums, int k) {int left = 0 , n = nums.length, right = n - 1 , ans = 0 ;;int [] sum = new int [n];0 ] = nums[0 ];for (int i = 1 ; i < n; i++) {1 ] + nums[i];for (int i = 0 ; i < n; i++) {for (int j = i + 1 ; j < n; j++) {if (sum[j] - sum[i] == k) { for (int i = 0 ; i < n; i++) { if (sum[i] == k) {return ans;
优化前缀和中的 O(n^2) 用 “两数之和” 的思路来优化掉枚举所有前缀和的过程,用 HashMap 直接找到想要的前缀和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {public int subarraySum (int [] nums, int k) {int left = 0 , n = nums.length, right = n - 1 , ans = 0 ;;int [] sum = new int [n];0 ] = nums[0 ];new HashMap <>();for (int i = 1 ; i < n; i++) {1 ] + nums[i];for (int i = 0 ; i < n; i++) {int num = k + sum[i];if (map.containsKey(sum[i])) { 0 ) + 1 ); for (int i = 0 ; i < n; i++) { if (sum[i] == k) {return ans;
滑动窗口最大值 10^5 O(n) 可以做
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
像前缀和一样,维护区间的最大值呢?
ST 表 复杂度为 O(nlogn):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public int [] maxSlidingWindow(int [] nums, int k) {int n = nums.length, l = 0 , logN = (int )(Math.log(n) / Math.log(2 )) + 1 ;int [] result = new int [n - k + 1 ];int f[][] = new int [n + 1 ][logN];int [] logn = new int [n + 5 ];for (int i = 1 ; i <= n; i++) {0 ] = nums[i - 1 ];1 ] = 0 ;2 ] = 1 ;for (int i = 3 ; i < n; i++) {2 ] + 1 ;for (int j = 1 ; j <= logN; j++)for (int i = 1 ; i + (1 << j) - 1 <= n; i++)1 ], f[i + (1 << (j - 1 ))][j - 1 ]); for (int i = 1 ; i <= n - k + 1 ; i++) {int x = i, y = Math.min(n, i + k - 1 );int s = logn[y - x + 1 ];1 ] = Math.max(f[x][s], f[y - (1 << s) + 1 ][s]);return result;
优先队列 O(nlogn)
这里的思路是用一个堆来维护最大值,同时在堆中记录下最大值的下标,当左指针移动时,要删掉那些失效的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public int [] maxSlidingWindow(int [] nums, int k) {new PriorityQueue <>((a, b) -> b.getKey() - a.getKey());int n = nums.length, l = 0 ;int ret[] = new int [n - k + 1 ];for (int r = 0 ; r < n; r++) {new java .util.AbstractMap.SimpleEntry<>(nums[r], r));if (r - l + 1 == k) {while (pq.peek().getValue() < l) pq.poll();1 ] = pq.peek().getKey();return ret;
单调队列 O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public int [] maxSlidingWindow(int [] nums, int k) {int n = nums.length, l = 0 ;int [] ans = new int [n - k + 1 ];new LinkedList <Integer>(); for (int r = 0 ; r < n; r++) {while (!deque.isEmpty() && nums[r] > nums[deque.peekLast()]) { if (r - l + 1 == k) {while (!deque.isEmpty() && deque.peekFirst() <= l) { return ans;
分块 + 前后缀数组 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {public int [] maxSlidingWindow(int [] nums, int k) {int n = nums.length;if (n == 1 ) return nums;int [] prefixMax = new int [n]; int [] suffixMax = new int [n]; for (int i = 0 ; i < n; i++) {if (i % k == 0 ) { else { 1 ], nums[i]);for (int i = n - 1 ; i >= 0 ; i--) {if ((i + 1 ) % k == 0 || i == n - 1 ) {else {1 ], nums[i]);int [] ans = new int [n - k + 1 ];for (int i = 0 ; i < n - k + 1 ; i++) { if (i % k == 0 ) { 1 ];else { 1 ]);return ans;
最小覆盖子串 要点:
滑动窗口走过所有的子串
用哈希表判断是否涵盖所有字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution {new HashMap <>();new HashMap <>();public String minWindow (String s, String t) {int n = s.length();int l = 0 ;int ansL = 0 , ansR = -1 , ansLen = Integer.MAX_VALUE;for (char ch : t.toCharArray()) {0 ) + 1 );for (int r = 0 ; r < n; r++) {0 ) + 1 );while (l <= r && check()) {if (r - l + 1 < ansLen) {1 ;1 ) - 1 );return ansR == -1 ? "" : s.substring(ansL, ansR + 1 );private boolean check () {for (Map.Entry<Character, Integer> entry : tMap.entrySet()) {if (windowMap.getOrDefault(entry.getKey(), 0 ) < entry.getValue()) {return false ;return true ;
双指针 前后指针: 经典的一个 pre 指针,一个 cur 指针:可以解决反转链表、交换节点等问题。快慢指针: 还有一个 fast 指针,一个 slow 指针:可以解决删除第 n 个元素的问题。
19.删除链表的倒数第 N 个结点 两个间隔 n 个节点的指针,快指针到末尾的时候,慢指针就是倒数第 n 个节点。
142.环形链表 II 判断链表是否有环,如果有返回入环的第一个节点
根据题意,任意时刻,fast 指针走过的距离都为 slow 指针的 2 倍。因此,我们有
a+(n+1)b+nc=2(a+b)⟹a=c+(n−1)(b+c)
因此,当发现 slow 与 fast 相遇时,我们再额外使用一个指针 ptr。起始,它指向链表头部;随后,它和 slow 每次向后移动一个位置。最终,它们会在入环点相遇。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Solution {public ListNode detectCycle (ListNode head) {ListNode fast = head;ListNode slow = head;while (slow != null && fast != null && slow.next != null && fast.next != null && fast.next.next != null ) {if (slow == fast) { ListNode index1 = fast;ListNode index2 = head;while (index1 != index2) {return index1;return null ;
哈希表 两数之和 10^4 O(n)
一个哈希表
三数之和 3000
O(n^2)
排序+双指针
四数之和 排序+双指针
注意溢出
四数相加 与上一题不同在于有 4 个数组,4 个数组等长度,上一题每个区间长度不同
哈希表 + 哈希表
字母异位词分组 10^4 O(n) 或 O(nlogn)
主要考虑异位词表示为相同的 map key,这样就可以将异位词聚集在一起。
最长连续序列 10^5 O(n)
未排序的数组,O(n) 找到数字连续的最长序列,不要求在原数组中连续。
排序做法为 O(nlogn)
key:考虑某一个数是不是连续序列的第一个数字,如果是则继续往下。
1 2 3 4 5 6 7 for (int num : set) {int i = 1 ;while (set.contains(num + i)) {
这种写法最坏会变成 O(n^2),需要思考如何跳过重复情况。如果再开一个 TreeSet 来定位下一个数字是 O(logn),应该可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public int longestConsecutive (int [] nums) {if (nums.length == 0 ) return 0 ;new HashSet <>();new TreeSet <>();Integer next = 0x3f3f3f3f ;for (int i = 0 ; i < nums.length; i++) {int longest = 1 ;while (next != null ) {int i = 1 ;while (set.contains(next)) {1 ;return longest;
还有一种 O(1) 定位下一个数字的方法:
如果这个数字为 x,那么不存在 x-1 的话,这个数字一定是连续序列的第一个数字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int longestConsecutive (int [] nums) {if (nums.length == 0 ) return 0 ;new HashSet <>();for (int i = 0 ; i < nums.length; i++) {int longest = 1 ;for (int num : set) {if (set.contains(num - 1 )) continue ;int i = 1 ;while (set.contains(num + i)) {return longest;
使数组的值全部为 K 的最少操作次数
给你一个整数数组 nums 和一个整数 k 。
如果一个数组中所有 严格大于 h 的整数值都 相等 ,那么我们称整数 h 是 合法的 。
比方说,如果 nums = [10, 8, 10, 8] ,那么 h = 9 是一个 合法 整数,因为所有满足 nums[i] > 9 的数都等于 10 ,但是 5 不是 合法 整数。
你可以对 nums 执行以下操作:
选择一个整数 h ,它对于 当前 nums 中的值是合法的。
对于每个下标 i ,如果它满足 nums[i] > h ,那么将 nums[i] 变为 h 。
你的目标是将 nums 中的所有元素都变为 k ,请你返回 最少 操作次数。如果无法将所有元素都变 k ,那么返回 -1 。
其实就是把大的数字变小,需要变几次。
我的做法:用 SortedSet 统计大于 k 的有多少,以及是否有小于 k 的。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public int minOperations (int [] nums, int k) {new TreeSet <>();for (int num : nums) {if (set.first() < k) return -1 ;if (set.first() == k) return set.size() - 1 ;return set.size();
官解:
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public int minOperations (int [] nums, int k) {new HashSet <>();for (int x : nums) {if (x < k) {return -1 ;else if (x > k) {return st.size();
统计坏数对的数目 给你一个下标从 0 开始的整数数组 nums 。如果 i < j 且 j - i != nums[j] - nums[i] ,那么我们称 (i, j) 是一个 坏数对 。
请你返回 nums 中 坏数对 的总数目。
正难则反,考虑坏数对的个数=总数对-好数对。
好数对:j - i == nums[j] - nums[i] 得到 j - nums[j] = nums[i] - i
于是有:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public long countBadPairs (int [] nums) {int n = nums.length;long ans = (long )n * (n - 1 ) / 2 ;new HashMap <>();for (int i = 0 ; i < n; i++) {long x = nums[i] - i;long c = map.getOrDefault(x, 0L );1 );return ans;
字符串 KMP 算法 next 数组:是一个前缀表,前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配。
那么什么是前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀。
下标5之前这部分的字符串(也就是字符串aabaa)的最长相等的前缀 和 后缀字符串是 子字符串aa ,因为找到了最长相等的前缀和后缀,匹配失败的位置是后缀子串的后面,那么我们找到与其相同的前缀的后面重新匹配就可以了。
反转字符串中的单词 方法一:split 之后拼接。
1 "a good example" .split()
方法二:反转整个字符串之后,再反转单个字符串。
最长公共子串 状态转移方程如下,dp[i][j] 表示字符串 x 以 i 结尾,字符串 y 以 j 结尾的最长公共子串,这样就有了:
按照上面方程实现的算法时间复杂度为 $O(n^2)$,空间复杂度为 $O(n^2)$。
image.png
注意到,更新 $dp[i][j]$ 只需要上一列,即 $dp[i-1]$ 列,所以可以将空间复杂度降低为 $O(n)$,但是需要注意因为使用的是相同的数组列,所以字符串不相等时需要设置 $dp[j] = 0$,同时要注意从后向前更新数组,因为如果从前向后更新,那么当前的 $dp[j]$ 使用的是当前列刚刚更新过的数据,而我们需要的是上一列的数据,所以可以从后向前更新数据避免这个问题。
rust 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 let mut dp = vec! [0 ; s2.len ()];for i in 0 ..s1.len () {for j in (0 ..s2.len ()).s2 () {if s[i] == s2[j] {if i == 0 || j == 0 {1 ;else {1 ] + 1 ;if dp[j] > max_len {let before_s2 = s2.len () - 1 - j;if before_s2 + dp[j] - 1 == i {else {0 ;
最长回文子串 动态规划 将字符串倒置之后求最长公共子串(状态转移方程与最长公共子串相同),并判断是否为回文子串,这里回文子串「由倒置字符串推出的原字符串末尾下标」与「i」应该相等。
代码中 longest_palindrome1 的求最长公共子串空间复杂度为 $O(n^2)$,longest_palindrome2 的求最长公共子串空间复杂度为 $O(n)$。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 struct Solution ;impl Solution {pub fn longest_palindrome1 (s: String ) -> String {if s.len () <= 1 {return s;let rev : String = s.chars ().rev ().collect ();let rev = rev.as_bytes ();let s = s.as_bytes ();let mut dp = vec! [vec! [0 ; rev.len ()]; s.len ()];let mut max_len = 0 ;let mut max_end = 0 ;for i in 0 ..s.len () {for j in 0 ..rev.len () {if s[i] == rev[j] {if i == 0 || j == 0 {1 ;else {1 ][j - 1 ] + 1 ;if dp[i][j] > max_len {let before_rev = rev.len () - 1 - j;if before_rev + dp[i][j] - 1 == i {str ::from_utf8 (&s[max_end + 1 - max_len..max_end + 1 ])unwrap ()to_string ()pub fn longest_palindrome2 (s: String ) -> String {if s.len () < 1 {return s;let rev : String = s.chars ().rev ().collect ();let s = s.as_bytes ();let rev = rev.as_bytes ();let mut max_len = 0 ;let mut max_end = 0 ;let mut dp = vec! [0 ; rev.len ()];for i in 0 ..s.len () {for j in (0 ..rev.len ()).rev () {if s[i] == rev[j] {if i == 0 || j == 0 {1 ;else {1 ] + 1 ;if dp[j] > max_len {let before_rev = rev.len () - 1 - j;if before_rev + dp[j] - 1 == i {else {0 ;str ::from_utf8 (&s[max_end + 1 - max_len..max_end + 1 ])unwrap ()to_string ()
中心拓展算法 为了避免在之后的叙述中出现歧义,这里我们指出什么是“朴素算法”。
该算法通过下述方式工作:对每个中心位置 $i$ 在比较一对对应字符后,只要可能,该算法便尝试将答案加 $1$。
该算法是比较慢的:它只能在 $O(n^2)$ 的时间内计算答案。
该算法的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vector<int > d1 (n) , d2 (n) ;for (int i = 0 ; i < n; i++) {1 ;while (0 <= i - d1[i] && i + d1[i] < n && s[i - d1[i]] == s[i + d1[i]]) {0 ;while (0 <= i - d2[i] - 1 && i + d2[i] < n &&1 ] == s[i + d2[i]]) {
1 2 3 4 5 6 7 8 9 10 11 0 ] * n0 ] * nfor i in range (0 , n):1 while 0 <= i - d1[i] and i + d1[i] < n and s[i - d1[i]] == s[i + d1[i]]:1 0 while 0 <= i - d2[i] - 1 and i + d2[i] < n and s[i - d2[i] - 1 ] == s[i + d2[i]]:1
Manacher 算法1 2 Manacher 算法是对中心拓展算法的优化,为了快速计算,我们维护已找到的最靠右的子回文串的 边界 $(l, r)$ (即具有最大 $r$ 值的回文串,其中 $l$ 和 $r$ 分别为该回文串左右边界的位置)。初始时,我们置 $l = 0$ 和 $r = -1$(-1 需区别于倒序索引位置,这里可为任意负数,仅为了循环初始时方便)。
现在假设我们要对下一个 $i$ 计算 $P[i]$,而之前所有 $P[]$ 中的值已计算完毕。我们将通过下列方式计算:
如果 $i$ 位于当前子回文串之外,即 $i > r$,那么我们调用朴素算法。
因此我们将连续地增加 $d_1[i]$,同时在每一步中检查当前的子串 $[i - P[i] \dots i + P[i]]$($P[i]$ 表示半径长度,下同)是否为一个回文串。如果我们找到了第一处对应字符不同,又或者碰到了 $s$ 的边界,则算法停止。在两种情况下我们均已计算完 $P[i]$。此后,仍需记得更新 $(l, r)$。
现在考虑 $i \le r$ 的情况。我们将尝试从已计算过的 $P[]$ 的值中获取一些信息。首先在子回文串 $(l, r)$ 中反转位置 $i$,即我们得到 $j = l + (r - i)$。现在来考察值 $P[j]$。因为位置 $j$ 同位置 $i$ 对称,我们 几乎总是 可以置 $P[i] = P[j]$。
存在 棘手的情况 ,主要有以下:
超出了 $r$
图转自 LeetCode
当我们要求 $P [ i ]$ 的时候,$P [mirror] = 7$,而此时 $P [ i ]$ 并不等于 $7$,为什么呢,因为我们从 $i$ 开始往后数 $7$ 个,等于 $22$,已经超过了最右的 $r$,此时不能利用对称性了,但我们一定可以扩展到 $r$ 的,所以 $P [ i ]$ 至少等于 $r - i = 20 - 15 = 5$,会不会更大呢,我们只需要比较 $T [ r+1 ]$ 和 $T [ r+1 ]$ 关于 $i$ 的对称点就行了,就像中心扩展法一样一个个扩展。
$P[i]$ 遇到了原字符串的左边界
image.png
此时$P [ i_{mirror} ] = 1$,但是 $P [ i ]$ 赋值成 1 是不正确的,出现这种情况的原因是 $P [ i_{mirror} ]$ 在扩展的时候首先是 “#” == “#”,之后遇到了 “^” 和另一个字符比较,也就是到了边界,才终止循环的。而 $P [ i ]$ 并没有遇到边界,所以我们可以继续通过中心扩展法一步一步向两边扩展就行了。
$i = r$
此时我们先把 P [ i ] 赋值为 0,然后通过中心扩展法一步一步扩展就行了。
考虑 $r$ 的更新
就这样一步一步的求出每个 $P [ i ]$,当求出的 $P [ i ]$ 的右边界大于当前的 $r$ 时,我们就需要更新 $r$ 为当前的回文串了。
最长公共子序列(LCS) 动态规划 状态转移方程如下:
LCS 对应的状态转移方程与最长公共子串不同之处在于:
最长公共子串要求字符串连续,所以下一个状态只能由上一个对应的字符串得到。
LCS 不要求字符串连续,所以可以前后移动,就有了第二个式子。
知道状态定义之后,我们开始写状态转移方程。
当 $text_1[i - 1] = text_2[j - 1]$ 时,说明两个子字符串的最后一位相等,所以最长公共子序列又增加了 1,所以 $dp[i][j] = dp[i - 1][j - 1] + 1$;举个例子,比如对于 ac 和 bc 而言,他们的最长公共子序列的长度等于 a 和 b 的最长公共子序列长度 $0 + 1 = 1$。
当 $text_1[i - 1] \ne text_2[j - 1]$ 时,说明两个子字符串的最后一位不相等,那么此时的状态 $dp[i][j]$ 应该是 $dp[i - 1][j]$ 和 $dp[i][j - 1]$ 的最大值。举个例子,比如对于 ace 和 bc 而言,他们的最长公共子序列的长度等于
① ace 和 b 的最长公共子序列长度 0 与
② ac 和 bc 的最长公共子序列长度 1 的最大值,即 1。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct Solution ;impl Solution {pub fn longest_common_subsequence (text1: String , text2: String ) -> i32 {let text1 = text1.as_bytes ();let text2 = text2.as_bytes ();let m = text1.len ();let n = text2.len ();let mut dp = vec! [vec! [0 ; n + 1 ]; m + 1 ];for i in 1 ..=m {for j in 1 ..=n {if text1[i - 1 ] == text2[j - 1 ] {1 ][j - 1 ] + 1 ;else {max (dp[i][j - 1 ], dp[i - 1 ][j]);return dp[m][n];
动态规划 动态规划总结 基本步骤:
确定dp数组(dp table)以及下标的含义
确定递推公式
dp数组如何初始化
确定遍历顺序
举例推导dp数组
对于动态规划,可以先初始化一个 dp 数组,然后手写出 dp[0] dp[1] dp[2] dp[3] 等等。这一步可以帮助思考 dp 数组和确定递推公式。
使用最小花费爬楼梯 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。
请你计算并返回达到楼梯顶部的最低花费。
要点:
dp[i] 为到达第 n 层的最低花费
可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯,dp[0] = 0,dp[1] = 0
第 i 层可以从 i - 1 和 i - 2 过来,从 i - 1 过来的花费是 cost[i - 1],从 cost[i - 2] 过来的花费是 cost[i - 2]
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public int minCostClimbingStairs (int [] cost) {int n = cost.length;int [] dp = new int [n + 1 ]; 0 ] = 0 ;1 ] = 0 ;for (int i = 2 ; i <= n; i++) {1 ] + cost[i - 1 ], dp[i - 2 ] + cost[i - 2 ]);return dp[n];
杨辉三角 主要难点在处理边界情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public List<List<Integer>> generate (int numRows) {new ArrayList <>();for (int i = 1 ; i <= numRows; i++) {new ArrayList <>(i);for (int j = 0 ; j < i; j++) {0 );0 , 1 );1 , 1 );if (ret.size() >= 2 ) {1 );for (int j = 1 ; j < i - 1 ; j++) { 1 ) + lastArr.get(j));return ret;
打家劫舍 要点在于对于某一个房子是否抢劫以及边界处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public int rob (int [] nums) {int n = nums.length;if (n == 1 ) return nums[0 ];if (n == 2 ) return Math.max(nums[0 ], nums[1 ]);int [] dp = new int [n + 1 ];0 ] = 0 ;1 ] = nums[0 ];2 ] = Math.max(nums[0 ], nums[1 ]);for (int i = 3 ; i <= n; i++) {2 ] + nums[i - 1 ], dp[i - 1 ]);return dp[n];
最大子序和 要点在于当前数字结尾的最大子串的和只能来自于前一个,也就是上楼梯只能由前一个上过来,或者现在新开一个。
1 2 3 4 5 6 7 8 9 10 11 12 class Solution {public int maxSubArray (int [] nums) {int n = nums.length;int [] dp = new int [n + 1 ]; int ans = -0x3f3f3f3f ;for (int i = 1 ; i <= n; i++) {1 ] + nums[i - 1 ], nums[i - 1 ]);return ans;
完全平方数 动态规划 要点是 dp[i] 表示结果为 i 的最少数量,然后转移的话,dp[i] 只能从 dp[i - 所有平方数] 来,于是写出状态转移方程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {public int numSquares (int n) {if (n == 1 ) return 1 ;if (n == 2 ) return 2 ;if (n == 3 ) return 3 ;if (n == 4 ) return 1 ;if (n == 5 ) return 2 ;int sqrtN = (int )Math.sqrt(n) + 1 ;int [] square = new int [sqrtN];for (int i = 1 ; i < sqrtN; i++) {int [] dp = new int [n + 1 ];0 ] = 0 ;1 ] = 1 ;2 ] = 2 ;3 ] = 3 ;4 ] = 1 ;5 ] = 2 ;for (int i = 1 ; i <= n; i++) {int min = 999 ;for (int j = 1 ; j < sqrtN; j++) {if (i - square[j] >= 0 ) {1 , min);return dp[n];
优化一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public int numSquares (int n) {int [] dp = new int [n + 1 ];for (int i = 1 ; i <= n; i++) {int min = 999 ;for (int j = 1 ; j * j <= i; j++) {if (i - j * j >= 0 ) {1 , min);return dp[n];
四平方和定理 image-20250107155619501
零钱兑换 这是一个完全背包问题,硬币可以重复使用。与爬楼梯类似。
$dp[i] = dp[i - coins[j]] + 1$。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public int coinChange(int [] coins, int amount) {if (amount == 0 ) return 0 ;int n = coins.length;int [] dp = new int [Math.max(n, amount) + 10 ]; for (int i = 0 ; i < n; i++) {if (coins[i] > amount) {continue ;1 ;for (int i = 0 ; i <= amount; i++) {if (dp[i] == 0 ) {0x3f3f3f3f ;0 ] = 0 ;int max = 0 ;for (int i = 1 ; i <= amount; i++) {for (int j = 0 ; j < n; j++) {if (i - coins[j] >= 0 ) {1 , dp[i]);return dp[amount] == 0x3f3f3f3f ? -1 : dp[amount];
单词拆分
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20
模拟 + 剪枝 不断地尝试所有可能的拼接,看最后能否拼接出来,注意要剪枝,否则会超时。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public boolean wordBreak (String s, List<String> wordDict) {int n = wordDict.size();new HashSet <>();int maxLen = 0x3f3f3f3f ;for (int i = 0 ; i < n; i++) {String word = wordDict.get(i);if (s.startsWith(word)) while (maxLen < s.length()) {new HashSet <>(dp); int minLen = 0x3f3f3f3f ;for (String cur : tmp) {if (cur.length() < maxLen) continue ;for (int i = 0 ; i < n; i++) {String newString = cur + wordDict.get(i);if (s.startsWith(newString)) { return dp.contains(s);
优化一下
动态规划 image-20250107182951481
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public boolean wordBreak (String s, List<String> wordDict) {int n = wordDict.size();new HashSet <>(wordDict);boolean [] dp = new boolean [s.length() + 1 ];0 ] = true ;for (int i = 1 ; i <= s.length(); i++) {for (int j = 0 ; j < i; j++) {if (dp[j] && set.contains(s.substring(j, i))) {true ;break ;return dp[s.length()];
最长递增子序列 要点在于 dp 为以第 i 个数字结尾的最长上升子序列长度,也就是 dp[i] 是 i 被选择的情况下的最长上升子序列长度。
这题要求的是子序列,而不是子数组,也就是可以跳过一些数字,所以动态转移方程就是对于 dp[i] 可以从任意的 dp[i - j] 跳过来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public int lengthOfLIS (int [] nums) {int n = nums.length, max = 1 ;int [] dp = new int [n + 1 ]; for (int i = 1 ; i <= n; i++) {1 ; for (int j = 1 ; j < i; j++) {if (nums[i - 1 ] > nums[j - 1 ]) {1 );return max;
乘积最大子数组 dp_max[i] 表示以第 i 个元素结尾的连续子数组的最大乘积。
对于每一个 dp[i] 来说,他会从前一个最大的 dp[i - 1] 过来,或者从最小的 dp[i - 1] 过来,或者在当前位置另起炉灶。与子序列不同,dp[i] 的子数组只能从 dp[i - 1] 过来,而不能从任意的 dp[i - j] 过来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public int maxProduct (int [] nums) {if (nums.length == 0 ) return 0 ;int n = nums.length;int [] dp_max = new int [n];int [] dp_min = new int [n];0 ] = nums[0 ];0 ] = nums[0 ];int ans = nums[0 ];for (int i = 1 ; i < n; i++) {1 ] * nums[i], dp_min[i-1 ] * nums[i]), nums[i]);1 ] * nums[i], dp_min[i-1 ] * nums[i]), nums[i]);return ans;
分割等和子集 1 <= nums.length <= 200,1 <= nums[i] <= 100 数据范围暗示了是和数组中最大数有关的二维 dp
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
如何将该问题转换为具有最优子结构的问题是难点。
动态规划,时间复杂度与元素大小相关的。
这个问题可以转换为:给定一个只包含正整数的非空数组 nums[0],判断是否可以从数组中选出一些数字,使得这些数字的和等于整个数组的元素和的一半。因此这个问题可以转换成「0−1 背包问题」。这道题与传统的「0−1 背包问题」的区别在于,传统的「0−1 背包问题」要求选取的物品的重量之和不能超过背包的总容量,这道题则要求选取的数字的和恰好等于整个数组的元素和的一半。类似于传统的「0−1 背包问题」,可以使用动态规划求解。
关键在于:将这个数组分割成两个子集 = 选出的数字的和是数组一半
然后关键的转移方程为:
和为 j 的数字可以由 j - nums[i](如果存在的话) 得到
和为 j 的数字可以由 j (如果存在的话)得到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Solution {public boolean canPartition (int [] nums) {int n = nums.length, target = 0 , max = 0 ;for (int i = 0 ; i < n; i++) {if ((target & 1 ) == 1 ) return false ; else target /= 2 ;if (max > target) return false ;boolean [][] dp = new boolean [n][target + 1 ]; for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < i; j++) {true ;for (int i = 0 ; i < n; i++) {0 ] = true ;for (int i = 1 ; i < n; i++) {for (int j = 1 ; j <= target; j++) {if (j >= nums[i]) {1 ][j] | dp[i - 1 ][j - nums[i]];else {1 ][j];if (dp[i - 1 ][j]) {true ;return dp[n - 1 ][target];
然后又有这一行仅仅由上一行确定得到,于是有:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 class Solution {public boolean canPartition (int [] nums) {int n = nums.length, target = 0 , max = 0 ;for (int i = 0 ; i < n; i++) {if ((target & 1 ) == 1 ) return false ; else target /= 2 ;if (max > target) return false ;boolean [][] dp = new boolean [n][target + 1 ]; for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < i; j++) {true ;for (int i = 0 ; i < n; i++) {0 ] = true ;for (int i = 1 ; i < n; i++) {int num = nums[i];for (int j = 1 ; j <= target; j++) {if (j >= num) {1 ][j] | dp[i - 1 ][j - num];else {1 ][j];return dp[n - 1 ][target];
优化空间:
和零钱兑换的一个关系:
可以把nums看成是各种零钱组合,整数amount对应这里的target,也就是nums总和的一半。区别在于这里nums里面的值只能用一次。
所以外层遍历都是遍历零钱组合,而内层遍历在遍历amount的时候有一个差别,即分割等和子集是倒着遍历,而零钱是正着遍历。
这里为什么要倒着遍历就是因为这里的值是不能用两遍 ,而零钱问题中是可以用多遍的,所以从小到大遍历~~
另外一个只判断能否成功一个判断最小零钱只是输出上的差异了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public boolean canPartition (int [] nums) {int n = nums.length, target = 0 , max = 0 ;for (int i = 0 ; i < n; i++) {if ((target & 1 ) == 1 ) return false ; else target /= 2 ;if (max > target) return false ;boolean [] dp = new boolean [target + 1 ]; 0 ] = true ;for (int i = 0 ; i < n; i++) { int num = nums[i];for (int j = target; j >= num; j--) {return dp[target];
最长有效括号 动态规划 0 <= s.length <= 3 * 10^4
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
定义 dp[i] 表示以下标 i 字符结尾的最长有效括号的长度。
难点在于怎么思考状态转移方程。
想到如果是合法的括号,那么肯定是左右都有,那么是不是可以每次走两步
s [i ]=‘)’ 且 s [i −1]=‘(’,也就是字符串形如 “……()”,我们可以推出:dp[i]=dp[i−2]+2
key: 两种有效的括号类型:(…)(…)(…),另一种为嵌套格式 ((…))
第一种可以 dp[i] = dp[i - 2] + 2,第二种则比较复杂。
考虑第一次遇到 … ))时,需要找到和右括号匹配的左括号,我们这里可以根据最优子结构得到 dp[i - 1] 代表了前一个右括号之前的有效括号,那么 i - dp[i - 1] - 1 的位置就是和当前右括号匹配的位置,如果这个位置是左括号,那么最长有效长度就可以 + 2,否则就不更新。
截屏2020-04-17下午4.26.34.png
同时还要考虑 …((…)) 的情况,也就是加上 dp[i - dp[i - 1] - 2]
于是有以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public int longestValidParentheses (String s) {int n = s.length();int [] dp = new int [n]; int max = 0 ;for (int i = 1 ; i < n; i++) {if (s.charAt(i - 1 ) == '(' && s.charAt(i) == ')' ) {2 ? dp[i - 2 ] : 0 ) + 2 ;else if (s.charAt(i - 1 ) == ')' && s.charAt(i) == ')' ) {if (i - dp[i - 1 ] - 1 >= 0 && s.charAt(i - dp[i - 1 ] - 1 ) == '(' ) {1 ] + 2 + ((i - dp[i - 1 ] - 2 ) > 0 ? dp[i - dp[i - 1 ] - 2 ] : 0 );return max;
栈 如果用栈,那么关键在于对于 …(…)() 和 …(()) 这两种情况如何判断长度和判断连续。
对于连续来说,可以过一遍字符串即可,对于长度判断,要点在于,如果对于右括号没有对应的左括号时,说明需要另起炉灶,重新计算最大长度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Solution {public int longestValidParentheses (String s) {int max = 0 ;new LinkedList <Integer>();1 );for (int i = 0 ; i < s.length(); i++) {if (s.charAt(i) == '(' ) {else {if (stack.isEmpty()) {else {return max;
寻找两个正序数组的中位数3 中位数定义:将一个集合划分为两个长度相等的子集,其中一个子集中的元素总是大于另一个子集中的元素。
left_part | right_part
A[0], A[1], ..., A[i-1] | A[i], A[i+1], ..., A[m-1]
B[0], B[1], ..., B[j-1] | B[j], B[j+1], ..., B[n-1]
根据中位数的定义,我们需要找到以上的划分(设两个数组总长度为偶数)使得
$\text{len}(left_part) = \text{len}(right_part)$
$\max(left_part)=\max(right_part)$
此时的中位数为:
所以现在的问题关键在于寻找这样一个划分。要寻找这样一个划分需要根据这个划分满足的两个条件:
左边元素共有 $i + j$ 个,右边元素共有 $(m-i)+(n-j)$ 个,所以由第一个式子可以得到 $i+j=(m-i)+(n-j)$。变形得到 $i+j=\frac{m+n}{2}$。假设 $m < n$,即 B 数组长于 A 数组,则 $i\in[0,m]$,有 $j = \frac{m+n}{2}-i$ 且 $j \in [0,n]$,所以只要知道 $i$ 的值,那么 $j$ 的值也是确定的。
在 $(0, m)$ 中找到 $i$,满足 $A[i-1] \le B[j]$ 且 $A[i] \ge B[j-1]$ 。
注意到第一个条件中,当 $i$ 增大的时候,$j$ 会减小以此来保证左右两部分的元素个数相同。同时 A、B 数组都是单调不递减的,所以一定存在一个最大的 $i$ 满足 $A[i-1] \le B[j]$。(当 $i$ 取 $i+1$ 时 $A[i] > B[j-1]$)
所以问题转化为:找一个最大的 $i$ 使得 $A[i-1] \le B[j]$。
对于这个问题,我们容易枚举 $i$,同时 A、B 都是单调递增的,所以我们还能知道枚举出的 $i$ 是不是满足条件($A[i-1] \le B[j]$),并从中找出满足条件的最大 $i$ 值即可。
对于两个数组总长度为奇数的情况,可以使得 $j = \lfloor \frac{m+n+1}{2}-i \rfloor$。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #[warn(dead_code)] struct Solution ;impl Solution {pub fn find_median_sorted_arrays (nums1: Vec <i32 >, nums2: Vec <i32 >) -> f64 {if nums1.len () > nums2.len () {return Solution::find_median_sorted_arrays (nums2, nums1);let (m, n) = (nums1.len (), nums2.len ());let mut left = 0 ;let mut right = m;let mut pos = 0 ;let mut median1 = 0 ;let mut median2 = 0 ;while left <= right {let i = (left + right) / 2 ;let j = (m + n + 1 ) / 2 - i;let nums_im1 = if i == 0 { -0x3f3f3f3f } else { nums1[i - 1 ] };let nums_i = if i == m { 0x3f3f3f3f } else { nums1[i] };let nums_jm1 = if j == 0 { -0x3f3f3f3f } else { nums2[j - 1 ] };let nums_j = if j == n { 0x3f3f3f3f } else { nums2[j] };if nums_im1 <= nums_j {max (nums_im1, nums_jm1);min (nums_i, nums_j);1 ;else {1 ;if (m + n) & 1 == 0 {as f64 / 2.0 else {as f64
三数之和 朴素算法 排序之后三重循环,判断三个数之和是否为 $0$,时间复杂度 $O(n^3)$。
排序的目的是为了容易地去除重复数字,因为排序之后只需要判断当前和前一个元素是否相等就可以知道是否是重复数字。
排序后双指针 注意到排序之后整个数组是单调非递减的,我们需要 $a+b+c=0$,当固定了 $a$ 和 $b$ 的时候,$c$ 从大到小地判断是否有 $a+b+c=0$ 即可。看似是最外层对应 $a$ 的循环嵌套对应 $b$ 的循环,并在其中加上了 $c$ 递减的循环,但是实际上注意到当 $b$ 与 $c$ 是同一个元素时,如果仍然不满足 $a+b+c=0$,那么 $c$ 继续向左减小就与之前的数字重复了,所以对于每一次 $b$ 中的循环,最多运行 $n$ 次,外边再嵌套 $a$ 的循环,时间复杂度为 $O(n^2)$。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 #[warn(dead_code)] struct Solution ;impl Solution {pub fn three_sum (mut nums: Vec <i32 >) -> Vec <Vec <i32 >> {sort ();let len = nums.len ();let mut ans = Vec ::new ();for i in 0 ..len {if i > 0 && nums[i - 1 ] == nums[i] {continue ;let mut third = len - 1 ;for j in i + 1 ..len {if j > i + 1 && nums[j - 1 ] == nums[j] {continue ;while j < third && nums[i] + nums[j] + nums[third] > 0 {1 ;if j == third {break ;if nums[i] + nums[j] + nums[third] == 0 {push (vec! [nums[i], nums[j], nums[third]]);
盛最多水的容器4 由上面的公式可以知道,面积由两部分共同决定:
所以考虑尽可能地增加宽度和高度。假设左指针指向的数为 $x$,右指针指向的数为 $y$,假设 $x < y$,距离为 $t$,接下来进行具体分析:
水量 $ area = \min(x, y) t = x t $,当左指针不变的时候,右指针无论在哪都不会影响容器的水量了,水量是固定的 $x*t$。
所以考虑左指针向右移动,这样才有可能取到更大的水量。
同理左指针指向的数大于右指针指向的数的时候,左移右指针才有可能取到更大的水量。
重复以上步骤就可以得到最大水量。
总时间复杂度为 $O(n)$。
注解:
对于双指针问题,两个指针的初始位置不一定都在最左或者最右,要灵活地设置指针位置。
最接近三数之和 与「盛最多水的容器」和「三数之和」类似,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #[warn(dead_code)] struct Solution ;impl Solution {pub fn three_sum_closest (mut nums: Vec <i32 >, target: i32 ) -> i32 {sort ();let len = nums.len ();let mut ans = 0 ;let mut diff = 0x3f3f3f3f ;for i in 0 ..len {if i > 0 && nums[i] == nums[i - 1 ] {continue ;let mut j = i + 1 ;let mut k = len - 1 ;while j < k {let sum = nums[i] + nums[j] + nums[k];if sum == target {return sum;let tmp = (sum - target).abs ();if tmp < diff {if sum > target {let mut k0 = k - 1 ;while j < k0 && nums[k0] == nums[k] {1 ;else {let mut j0 = j + 1 ;while j0 < k && nums[j0] == nums[j] {1 ;
最大整除子集 给你一个由 无重复 正整数组成的集合 nums ,请你找出并返回其中最大的整除子集 answer ,子集中每一元素对 (answer[i], answer[j]) 都应当满足:
answer[i] % answer[j] == 0 ,或answer[j] % answer[i] == 0
如果存在多个有效解子集,返回其中任何一个均可。
动态规划 设子集为 A,题目要求对于任意 (A[i],A[j]),都满足 A[i]modA[j]=0 或者 A[j]modA[i]=0,也就是一个数是另一个数的倍数。
这里有两个条件,不好处理。我们可以把 A 排序,或者说把 nums 排序(从小到大)。由于 nums 所有元素互不相同(没有相等的情况),题目要求变成:
从(排序后的)nums 中选一个子序列,在子序列中,右边的数一定是左边的数的倍数。
从(排序后的)nums 中选一个子序列,在子序列中,任意相邻的两个数,右边的数一定是左边的数的倍数。
下文把满足题目要求的子序列叫做合法子序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public List<Integer> largestDivisibleSubset (int [] nums) {int n = nums.length;int [] dp = new int [n]; int [] from = new int [n];1 );int maxI = 0 ;for (int i = 0 ; i < n; i++) {for (int j = 0 ; j < i; j++) {if (nums[i] % nums[j] == 0 && dp[j] > dp[i]) {if (dp[i] > dp[maxI]) {new ArrayList <>(dp[maxI]);for (int i = maxI; i >= 0 ; i = from[i]) {return path;
多维 dp 不同路径 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
二维爬楼梯,对于每个位置能从上面和左边过来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public int uniquePaths (int m, int n) {int [][] dp = new int [m][n];for (int i = 0 ; i < n; i++) {0 ][i] = 1 ;for (int i = 0 ; i < m; i++) {0 ] = 1 ;for (int i = 1 ; i < m; i++) {for (int j = 1 ; j < n; j++) {1 ] + dp[i - 1 ][j];return dp[m - 1 ][n - 1 ];
最小路径和 还是和不同路径一样,不同的是从左上到右下的时候需要记录最小路径和。还有初始化状态的时候,要记得加上走过来的时候的最小值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Solution {public int minPathSum (int [][] grid) {int m = grid.length;int n = grid[0 ].length;int [][] dp = new int [m][n]; 0 ][0 ] = grid[0 ][0 ];for (int i = 1 ; i < n; i++) {0 ][i] = grid[0 ][i] + dp[0 ][i - 1 ];for (int i = 1 ; i < m; i++) {0 ] = grid[i][0 ] + dp[i - 1 ][0 ];for (int i = 1 ; i < m; i++) {for (int j = 1 ; j < n; j++) {1 ][j], dp[i][j - 1 ]) + grid[i][j];return dp[m - 1 ][n - 1 ];
最长回文子串 要点在于:
初始状态所有字符都和自己回文。
dp$$i][j] 表示子串 i…j 是否是回文串。
为了便于考虑边界情况,外层循环枚举 j,内层循环枚举 i。
dpi + 1][j - 1] 是回文字符串,并且 s[i] == s[j]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution {public String longestPalindrome (String s) {int n = s.length();boolean dp[][] = new boolean [n][n];int maxLen = 0 ;int start = 0 , end = 0 ;for (int i = 0 ; i < n; i++) {true ;for (int j = 0 ; j < n; j++) {for (int i = 0 ; i < j; i++) {if ((j - i <= 1 || dp[i + 1 ][j - 1 ]) && s.charAt(i) == s.charAt(j)) {true ;if (j - i + 1 > maxLen) {1 ;return s.substring(start, end + 1 );
最长公共子序列 要点:
dp[i][j] 表示字符串 s1[0…i) 和 s2[0…j) 的最长公共子序列长度,注意这里是左闭右开。
对于 dp[i][j] 能从 dp[i - 1][j - 1] + 1 得到,此时 s1[i] == s2[j]
不相等时 dp[i][j] 是 Math.max(dp[i - 1][j], dp[i][j - 1]), 也就是跳过当前字符
这里的 i 从 1…len1,然后 i-1 是 0…len1-1,所以 i-1 遍历了整个字符串。如果不使用这种处理方式,会导致最后一位字符未被处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public int longestCommonSubsequence (String text1, String text2) {int len1 = text1.length();int len2 = text2.length();int [][] dp = new int [len1 + 1 ][len2 + 1 ]; for (int i = 1 ; i <= len1; i++) {for (int j = 1 ; j <= len2; j++) {if (text1.charAt(i - 1 ) == text2.charAt(j - 1 )) {1 ][j - 1 ] + 1 ;else {1 ][j], dp[i][j - 1 ]);return dp[len1][len2];
编辑距离 要点:
dp[i][j] 表示 word1 前 i 个字符变成 word2 前 j 个字符需要的最少操作数
边界条件是 0 字符和有 i 个字符的情况。
状态转移
1 2 3 从 dp[i - 1] [j - 1] 过来是替换掉 word1 中的字符,因为 dp[i - 1] [j - 1] 已经匹配[i - 1] [j] 过来是删除掉 word1 中的字符,因为 dp[i - 1] [j] 已经匹配[i] [j - 1] 过来是删除掉 word2 中的字符(等价于 word1 增加字符),因为 dp[i] [j - 1] 已经匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public int minDistance (String word1, String word2) {int len1 = word1.length();int len2 = word2.length();int [][] dp = new int [len1 + 1 ][len2 + 1 ]; for (int i = 1 ; i <= len1; i++) {0 ] = i;for (int i = 1 ; i <= len2; i++) {0 ][i] = i;for (int i = 1 ; i <= len1; i++) {for (int j = 1 ; j <= len2; j++) {if (word1.charAt(i - 1 ) == word2.charAt(j - 1 )) { 1 ][j - 1 ];else { 1 ][j - 1 ], Math.min(dp[i - 1 ][j], dp[i][j - 1 ])) + 1 ;return dp[len1][len2];
数据结构 合并K个升序链表 使用优先队列即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 use std::{cmp::Reverse, collections::BinaryHeap};impl Solution {pub fn merge_k_lists (lists: Vec <Option <Box <ListNode>>>) -> Option <Box <ListNode>> {let mut priority_queue = BinaryHeap::new ();let mut ret = Box ::new (ListNode::new (0 ));let mut ptr = &mut ret;for list in lists {let mut plist = &list;while let Some (node) = plist {push (Reverse (node.val));while let Some (Reverse (node)) = priority_queue.pop () {Some (Box ::new (ListNode::new (node)));as_mut ().unwrap ();
贪心 有序三元组中的最大值 I
3 <= nums.length <= 1001 <= nums[i] <= 106
给你一个下标从 0 开始的整数数组 nums 。
请你从所有满足 i < j < k 的下标三元组 (i, j, k) 中,找出并返回下标三元组的最大值。如果所有满足条件的三元组的值都是负数,则返回 0 。
下标三元组 (i, j, k) 的值等于 (nums[i] - nums[j]) * nums[k] 。
数组长度 <= 100,也就是说 n^3 = 1e6,可以暴力:
但是要注意 ans 是 long 的,所以存在超出 int 的情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public long maximumTripletValue (int [] nums) {long ans = 0 ;int n = nums.length;for (int i = 0 ; i < n - 2 ; i++) {for (int k = n - 1 ; k >= i + 2 ; k--) {for (int j = i + 1 ; j < k; j++) {long )nums[k] * (nums[i] - nums[j]));return ans;
优化为 O(n^2),要点在于当固定 j, k 时,i 是 0…j 的最大值,所以 i 可以由 j 动态得到。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public long maximumTripletValue (int [] nums) {long ans = 0 ;int n = nums.length;for (int k = 2 ; k < n; k++) {long i = nums[0 ];for (int j = 1 ; j < k; j++) {return ans;
优化为 O(n),要点在于可以提前维护 0…j 和 j…n 的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public long maximumTripletValue (int [] nums) {long ans = 0 ;int n = nums.length;int [] leftMax = new int [n + 1 ];int [] rightMax = new int [n + 1 ];for (int i = 1 ; i < n; i++) {1 ], nums[i - 1 ]);for (int i = n - 2 ; i > 0 ; i--) {1 ], nums[i + 1 ]);for (int i = 1 ; i < n - 1 ; i++) {long )rightMax[i] * (leftMax[i] - nums[i]));return ans;
优化空间为 O(1),要点在于对于 (nums[i] - nums[j]) * nums[k],i 和 j 是小于 k 的,所以 i,j 要走的路,k 都走过了,所以可以枚举 k 的时候维护其他状态。
然后维护其他状态的思路是考虑固定 k,如果要枚举 k,那么考虑 k 被固定的情况,其他的两个变量如何变化。
维护 nums[i] - nums[j] 的最大值,维护 nums[i] 的最大值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public long maximumTripletValue (int [] nums) {long ans = 0 ;int n = nums.length;int maxI = 0 ;int maxISubJ = 0 ;for (int k = 0 ; k < n; k++) {long )maxISubJ * nums[k]);return ans;
使数组元素互不相同所需的最少操作次数 给你一个整数数组 nums,你需要确保数组中的元素 互不相同 。为此,你可以执行以下操作任意次:
从数组的开头移除 3 个元素。如果数组中元素少于 3 个,则移除所有剩余元素。
注意: 空数组也视作为数组元素互不相同。返回使数组元素互不相同所需的 最少操作次数 。
模拟 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public int minimumOperations (int [] nums) {int n = nums.length;int [] c = new int [101 ];for (int i = 0 ; i < n; i++) {int ans = 0 ;for (int i = 0 ; i < n; i+=3 ) {boolean ok = true ;for (int j = 1 ; j <= 100 ; j++) {if (c[j] > 1 ) {if (i + 1 < n) c[nums[i+1 ]]--;if (i + 2 < n) c[nums[i+2 ]]--;false ;break ;if (!ok) ans++;return ans;
技巧 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Solution {public int minimumOperations (int [] nums) {int n = nums.length;int ans = n / 3 ;boolean [] seen = new boolean [101 ];for (int i = n - 1 ; i >= 0 ; i--) {if (seen[nums[i]]) {return i / 3 + 1 ;true ;return 0 ;
数学 找出所有子集的异或总和再求和 简单做法 枚举所有子集,然后求出异或总和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public int subsetXORSum (int [] nums) {int n = nums.length;int ans = 0 ;for (int i = 0 ; i < (1 << n); i++) {int XORSum = 0 ;for (int j = 0 ; j < n; j++) {if ((i & (1 << j)) != 0 ) {return ans;
数学做法 提示1 对于异或运算,每个比特位是互相独立的,我们可以先思考只有一个比特位的情况,也就是 nums 中只有 0 和 1 的情况。(从特殊到一般)
在这种情况下,如果子集中有偶数个 1,那么异或和为 0;如果子集中有奇数个 1,那么异或和为 1。所以关键是求出异或和为 1 的子集个数。题目要求的是子集的异或总和再求和,异或和为 1 的子集的个数就是最终答案。
设 nums 的长度为 n,且包含 1。我们可以先把其中一个 1 拿出来,剩下 n−1 个数随便选或不选,有 $2^{n−1}$ 种选法。
如果这 n−1 个数中选了偶数个 1,那么放入我们拿出来的 1(选这个 1),得到奇数个 1,异或和为 1。
如果这 n−1 个数中选了奇数个 1,那么不放入我们拿出来的 1(不选这个 1),得到奇数个 1,异或和为 1。
所以,恰好有 $2^{n−1}$ 个子集的异或和为 1。
注意这个结论与 nums 中有多少个 1 是无关的,只要有 1,异或和为 1 的子集个数就是 $2^{n−1}$。如果 nums 中没有 1,那么有 0 个子集的异或和为 1。
所以,在有至少一个 1 的情况下,nums 的所有子集的异或和的总和为 $2^{n−1}$。
提示2 推广到多个比特位的情况。
例如 $nums = [3,2,8]$,3 = 11,2 = 10,8 = 1000
第 $0,1,3$ 个比特位上有 $1$,每个比特位对应的「所有子集的异或和的总和」分别为
相加得
怎么知道哪些比特位上有 $1$?计算 $nums$ 的所有元素的 OR,即 $1011_{(2)}$。
注意到,所有元素的 OR,就是上例中的 $2^0 + 2^1 + 2^3$。
一般地,设 $nums$ 所有元素的 OR 为 $or$,$nums$ 的所有子集的异或和的总和为
1 2 3 4 5 6 7 8 9 10 class Solution {public int subsetXORSum (int [] nums) {int n = nums.length;int XORSum = 0 ;for (int i = 0 ; i < n; i++) {return XORSum * 1 << (n - 1 );
数位 dp 统计强大整数的数目 给你三个整数 start ,finish 和 limit 。同时给你一个下标从 0 开始的字符串 s ,表示一个 正 整数。
如果一个 正 整数 x 末尾部分是 s (换句话说,s 是 x 的 后缀 ),且 x 中的每个数位至多是 limit ,那么我们称 x 是 强大的 。
请你返回区间 [start..finish] 内强大整数的 总数目 。
如果一个字符串 x 是 y 中某个下标开始(包括 0 ),到下标为 y.length - 1 结束的子字符串,那么我们称 x 是 y 的一个后缀。比方说,25 是 5125 的一个后缀,但不是 512 的后缀。
组合数学 我们可以实现一个计数函数 calculate(x) 来直接计算小于等于 x 的满足 limit 的数字数量,然后答案即为 calculate(finish) - calculate(start - 1)。 首先考虑 x 中与 s 长度相等的后缀部份(如果 x 长度小于 s,答案为 0),如果 x 的后缀大于等于 s,那么后缀部份对答案贡献为 1。 接着考虑剩余的前缀部份。令 preLen 表示前缀的长度,即 |x| - |s|。对于前缀的每一位 x[i]: - 如果超过了 limit,意味着当前位最多只能取到 limit,后面的所有位任取组成的数字也不会超过 x。因此包括第 i 位,后面的所有位(共 preLen - i 位)都可以取 [0, limit](共 limit + 1 个数),对答案的贡献是 (limit + 1)^(preLen - i)。 - 如果 x[i] 没有超过 limit,那么当前位最多取到 x[i],后面的所有位可以取 [0, limit],对答案的贡献是 x[i] × (limit + 1)^(preLen - i - 1)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public long numberOfPowerfulInt (long start, long finish, int limit, String s) {String StrFinish = String.valueOf(finish);String StrStart = String.valueOf(start - 1 );return calculate(StrFinish, s, limit) - calculate(StrStart, s, limit);private long calculate (String x, String s, int limit) {if (x.length() < s.length()) {return 0 ;if (x.length() == s.length()) {return x.compareTo(s) >= 0 ? 1 : 0 ;String suffix = x.substring(x.length() - s.length()); long count = 0 ;int preLen = x.length() - s.length();for (int i = 0 ; i <= preLen; i++) {int digit = x.charAt(i) - '0' ;if (limit < digit) {long ) Math.pow(limit + 1 , preLen - i);return count;long )digit * (long )Math.pow(limit + 1 , preLen - 1 - i);if (suffix.compareTo(s) >= 0 ) {return count;
数位 dp 定义 dfs(i, limitLow, limitHigh) 表示构造第 i 位及其之后数位的合法方案数,其余参数的含义为:
limitHigh 表示当前是否受到了 finish 的约束(我们要构造的数字不能超过 finish)。若为真,则第 i 位填入的数字至多为 finish[i],否则至多为 9,这个数记作 hi。如果在受到约束的情况下填了 finish[i],那么后续填入的数字仍会受到 finish 的约束。例如 finish = 123,那么 i = 0 填的是 1 的话,i = 1 的这一位至多填 2。limitLow 表示当前是否受到了 start 的约束(我们要构造的数字不能低于 start)。若为真,则第 i 位填入的数字至少为 start[i],否则至少为 0,这个数记作 lo。如果在受到约束的情况下填了 start[i],那么后续填入的数字仍会受到 start 的约束。
枚举第 i 位填什么数字。
如果 i < n - |s|,那么可以填 [lo, min(hi, limit)] 内的数,否则只能填 s[i - (n - |s|)]。这里 |s| 表示 s 的长度。
为什么不能把 hi 置为 min(hi, limit)?
1 int hi = limitHigh ? Math.min(high[i] - '0' , limit ) : 9 ;
你就隐含地说:hi 是由 limit 限制的,而不是由 high 限制的limitHigh && d == hi 判断会出错!
举个例子:
假设 high = 5299, 当前正在处理第 1 位(从左往右),也就是处理 2,而 limit = 1。
如果你写:
你会枚举 0,1 而不是原本允许的 0,1,2,并且还会让 limitHigh && d == hi 在本应为 d==2 时失效!
正确的逻辑应该是:
hi 始终 由 limitHigh ? high[i] : 9 来决定;limit 是附加的“过滤”逻辑,不应该影响 Digit DP 的状态定义;在枚举循环内部 使用 Math.min(hi, limit) 来限制合法的数位;
这样才能确保转移关系和 memo 的缓存是准确的。
递归终点:dfs(n, *, *) = 1,表示成功构造出一个合法数字。
递归入口:dfs(0, true, true),表示:
从最高位开始枚举。
一开始要受到 start 和 finish 的约束(否则就可以随意填了,这肯定不行)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Solution {public long numberOfPowerfulInt (long start, long finish, int limit, String s) {String low = String.valueOf(start);String high = String.valueOf(finish);int n = high.length();"0" .repeat(n - low.length()) + low; long [] memo = new long [n];1 );return dfs(0 , true , true , low.toCharArray(), high.toCharArray(), limit, s.toCharArray(), memo);private long dfs (int i, boolean limitLow, boolean limitHigh, char [] low, char [] high, int limit, char [] s, long [] memo) {if (i == high.length) return 1 ;if (!limitLow && !limitHigh && memo[i] != -1 ) {return memo[i];int lo = limitLow ? low[i] - '0' : 0 ;int hi = limitHigh ? high[i] - '0' : 9 ;long res = 0 ;if (i < high.length - s.length) { for (int d = lo; d <= Math.min(hi, limit); d++) {1 , limitLow && d == lo, limitHigh && d == hi, low, high, limit, s, memo);else {int x = s[i - (high.length - s.length)] - '0' ;if (lo <= x && x <= hi) { 1 , limitLow && x == lo, limitHigh && x == hi, low, high, limit, s, memo);if (!limitLow && !limitHigh) {return res;
统计对称整数的数目 暴力判断 O((high −low )loghigh ) 数位 dp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class Solution {private char [] lowS, highS;private int n, m, diffLh;private int [][][] memo;public int countSymmetricIntegers (int low, int high) {2 ;new int [n][diffLh + 1 ][m * 18 + 1 ]; for (int [][] mat : memo) {for (int [] row : mat) {1 );return dfs(0 , -1 , m * 9 , true , true );private int dfs (int i, int start, int diff, boolean limitLow, boolean limitHigh) {if (i == n) {return diff == m * 9 ? 1 : 0 ;if (start != -1 && !limitLow && !limitHigh && memo[i][start][diff] != -1 ) {return memo[i][start][diff];int lo = limitLow && i >= diffLh ? lowS[i - diffLh] - '0' : 0 ;int hi = limitHigh ? highS[i] - '0' : 9 ;if (start < 0 && (n - i) % 2 > 0 ) {return lo > 0 ? 0 : dfs(i + 1 , start, diff, true , false );int res = 0 ;boolean isLeft = start < 0 || i < (start + n) / 2 ;for (int d = lo; d <= hi; d++) {1 ,0 && d > 0 ? i : start, if (start != -1 && !limitLow && !limitHigh) {return res;
树状数组 统计数组中好三元组数目 给你两个下标从 0 开始且长度为 n 的整数数组 nums1 和 nums2 ,两者都是 [0, 1, ..., n - 1] 的 排列 。
好三元组 指的是 3 个 互不相同 的值,且它们在数组 nums1 和 nums2 中出现顺序保持一致。换句话说,如果我们将 pos1v 记为值 v 在 nums1 中出现的位置,pos2v 为值 v 在 nums2 中的位置,那么一个好三元组定义为 0 <= x, y, z <= n - 1 ,且 pos1x < pos1y < pos1z 和 pos2x < pos2y < pos2z 都成立的 (x, y, z) 。
请你返回好三元组的 总数目 。
示例 1:
1 2 3 4 5 输入:nums1 = [2 ,0 ,1 ,3 ], nums2 = [0 ,1 ,2 ,3 ]1 4 个三元组 满足 pos1 x < pos1 y < pos1 z ,分别是 , , 和 。2 x < pos2 y < pos2 z 。所以只有 1 个好三元组。
示例 2:
1 2 3 输入:nums1 = [4 ,0 ,1 ,3 ,2 ], nums2 = [4 ,1 ,0 ,2 ,3 ]4 4 个好三元组 , , 和 。
题意解读 题目本质上是求:nums1 和 nums2 的长度恰好为 3 的公共子序列的个数。
你可能想到了 [1143. 最长公共子序列]。但本题 $n$ 太大,写 $O(n^2)$ 的 DP 太慢。
核心思路 本题是排列,所有元素互不相同。如果可以通过某种方法,把 nums1 变成 [0,1,2, ... ,n - 1],我们就能把「公共子序列问题」变成「严格递增子序列问题」,后者有更好的性质,可以更快地求解。
此外,本题子序列长度为 3,对于 3 个数的问题,通常可以枚举中间那个数。
前置知识:置换 置换是一个排列到另一个排列的双射。
以示例 2 为例,定义如下置换 $P(x)$:
把 nums1 = [4,0,1,3,2] 中的每个元素 $x$ 替换为 $P(x)$,可以得到一个单调递增的排列 $A = [0,1,2,3,4]$。把 $P(x)$ 应用到 nums2 = [4,1,0,2,3] 上,可以得到一个新的排列 $B = [0,2,1,4,3]$。
在置换之前,(4,0,3) 是两个排列的公共子序列。
在置换之后,$(P(4),P(0),P(3)) = (0,1,3)$ 也是两个新的排列的公共子序列。
⚠️注意:置换不是排序,是映射(可以理解成重命名),原来的公共子序列在映射后,子序列元素的位置没变,只是数值变了,仍然是公共子序列。所以置换不会改变公共子序列的个数。
思路 把 nums1 置换成排列 $A = [0,1,2, … ,n - 1]$,设这一置换为 $P(x)$。把 $P(x)$ 也应用到 nums2 上,得到排列 $B$。
置换后,我们要找的长为 3 的公共子序列,一定是严格递增的。由于 $A$ 的所有子序列都是严格递增的,我们只需关注 $B$。现在问题变成:
对于长为 3 的严格递增子序列 $(x,y,z)$,枚举中间元素 $y$。现在问题变成:
在 $B$ 中,元素 $y$ 的左侧有多少个比 $y$ 小的数 $x$?右侧有多少个比 $y$ 大的数 $z$?
枚举 $y = B[i]$,设 $i$ 左侧有 $less_y$ 个元素比 $y$ 小,那么 $i$ 左侧有 $i - less_y$ 个元素比 $y$ 大。在整个排列 $B$ 中,比 $y$ 大的数有 $n - 1 - y$ 个,减去 $i - less_y$,得到 $i$ 右侧有 $n - 1 - y - (i - less_y)$ 个数比 $y$ 大。所以(根据乘法原理)中间元素是 $y$ 的长为 3 的严格递增子序列的个数为:
$ less_y \cdot (n - 1 - y - (i - less_y)) $
枚举 $y = B[i]$,计算上式,加入答案。
如何计算 $less_y$ ?这可以用值域树状数组 (或者有序集合)。
值域树状数组的意思是,把元素值视作下标。添加一个值为 3 的数,就是调用树状数组的 update(3,1)。查询小于 3 的元素个数,即小于等于 2 的元素个数,就是调用树状数组的 pre(2)。
由于本题元素值是从 0 开始的,但树状数组的下标是从 1 开始的,所以把元素值转成下标,要加一。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class FenwickTree {private final int [] tree;public FenwickTree (int n) {new int [n + 1 ]; public void update (int i, long val) {for (; i < tree.length; i += i & -i) {public int pre (int i) {int res = 0 ;for (; i > 0 ; i &= i - 1 ) {return res;class Solution {public long goodTriplets (int [] nums1, int [] nums2) {int n = nums1.length;int [] p = new int [n];for (int i = 0 ; i < n; i++) {long ans = 0 ;FenwickTree t = new FenwickTree (n);for (int i = 0 ; i < n - 1 ; i++) {int y = p[nums2[i]];int less = t.pre(y);long ) less * (n - 1 - y - (i - less));1 , 1 );return ans;
参考
1 . https://leetcode-cn.com/problems/longest-palindromic-substring/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-bao-gu ↩
2 . https://oi-wiki.org/string/manacher/ ↩
3 . https://leetcode-cn.com/problems/median-of-two-sorted-arrays/solution/xun-zhao-liang-ge-you-xu-shu-zu-de-zhong-wei-s-114/ ↩
4 . https://leetcode-cn.com/problems/container-with-most-water/solution/sheng-zui-duo-shui-de-rong-qi-by-leetcode-solution/ ↩

 img
img img
img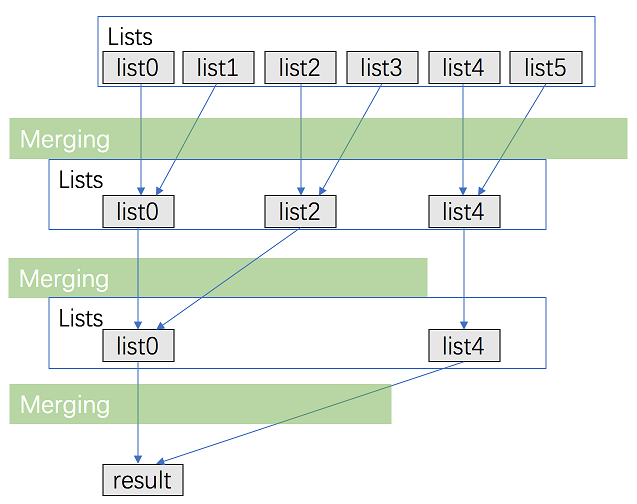 img
img image-20250202004335203
image-20250202004335203 image-20250205185730436
image-20250205185730436 image-20250227154454826
image-20250227154454826 image-20250301225057849
image-20250301225057849 image.png
image.png image-20250421172529810
image-20250421172529810 image.png
image.png 图转自 LeetCode
图转自 LeetCode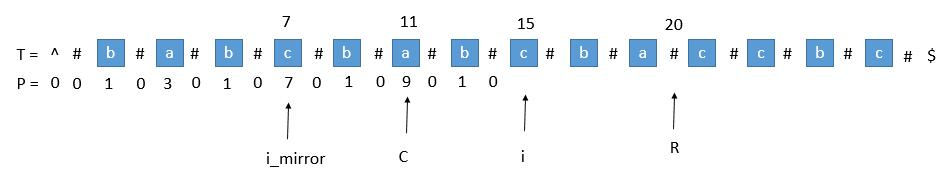
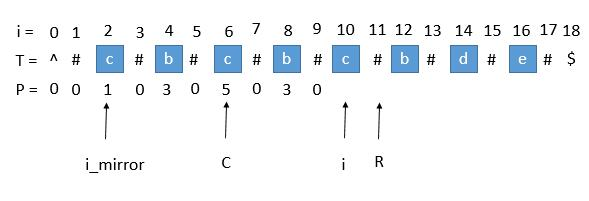
 image-20250107155619501
image-20250107155619501 image-20250107182951481
image-20250107182951481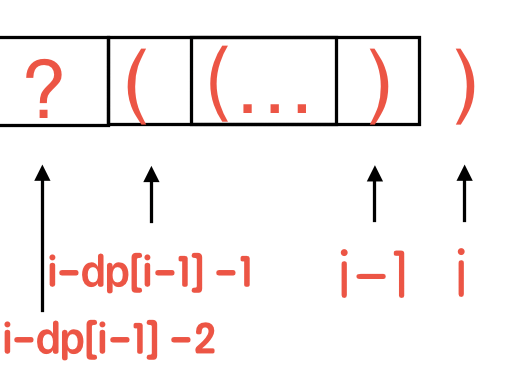 截屏2020-04-17下午4.26.34.png
截屏2020-04-17下午4.26.34.png